“Priceline has been at the forefront of using machine learning for many years. Vector search gives us the ability to semantically query the billions of real-time signals we receive as part of our checkout experience that flow back to Astra DB. We plan to use Google Cloud’s Generative AI capabilities alongside Astra DB’s vector search to power our real time data infrastructure and Generative AI experiences."
Astra DB
NoSQL and Vector DB for Generative AI, Instantly, at Scale
New vector search capabilities enable complex, context-sensitive searches across diverse data formats for use in Generative AI applications, powered by Apache Cassandra®.

Benefits
Move from AI Experimentation to AI Production
Build in any language
Create real-time data applications easily with the language and APIs you already love, from CQL to Document (JSON), REST, GraphQL and gRPC APIs. Build flexible query patterns using globally-distributed relational indexes.
Gen AI for the Enterprise: Secure, Scalable, Compliant and 5X cheaper
Scale to petabytes of data for the most demanding AI apps, with world-class performance at a fraction of the cost
Deliver enterprise ready Generative AI through enhanced high availability delivered with data replication across regions and availability zones.
Secure and Compliant
AI apps built on DataStax are enterprise ready, built on a proven stack, governed and compliant to the highest standards for PCI, SOC2, HIPAA, ISO 27001 and more.

Integrate with Vertex AI
Leverage the power of AI technology and the speed and scalability of Cassandra and Astra DB to fuel Generative AI projects by connecting data to Vertex AI.
Developers
Accelerate development with APIs
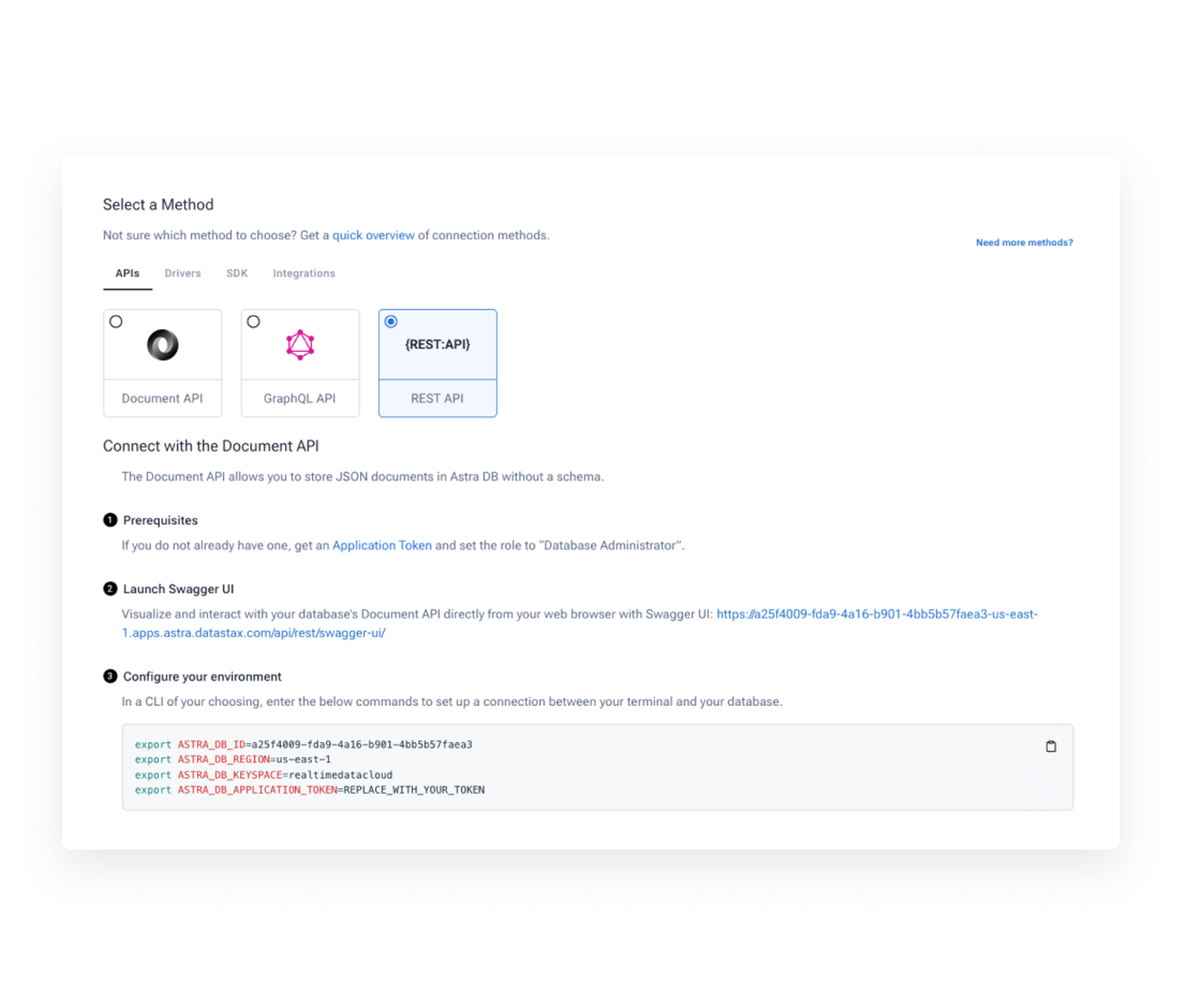
Stargate API gateway integrated with Astra DB makes it easier to build for maximum flexibility with the APIs of your choice.

REST APIs
Secure RESTful APIs for Astra DB to integrate fast with front-end apps.

GraphQL
Serve a GraphQL API from Astra DB. Develop in schema first or cql first modes.

Document (schemaless)
Fast ingest and retrieval of JSON documents and collections in Astra DB with no data modeling needed.

gRPC
Blend performance with simplicity using gRPC that’s easier to maintain than drivers and faster than HTTP APIs. Use our supported Go, Java, Node.js and Rust clients or build your own.
curl --request POST \
--url https://${ASTRA_DB_ID}-${ASTRA_DB_REGION}.apps.astra.datastax.com/api/rest/v2/schemas/keyspaces/${ASTRA_DB_KEYSPACE}/tables \
--header 'content-type: application/json' \
--header "x-cassandra-token: ${ASTRA_DB_APPLICATION_TOKEN}" \
--data
'{"name":"rest_example_products","ifNotExists":true,"columnDefinitions": [
{"name":"id","typeDefinition":"uuid","static":false},
{"name":"productname","typeDefinition":"text","static":false},
{"name":"description","typeDefinition":"text","static":false},
{"name":"price","typeDefinition":"decimal","static":false}, {"name":"created","typeDefinition":"timestamp","static":false}],"primaryKey":
{"partitionKey":["id"]},"tableOptions":{"defaultTimeToLive":0}}'Vector Search from Any Cloud, with Global Scale and Zero Ops
Discover how to build Generative AI apps with the scale and performance you need, without the operational burden, so you can focus on delivering code.
Trusted by AI Leaders in Every Industry
Migrations
Easily migrate your data and apps with zero downtime
Automated self-service migration
Thinking about migrating to Astra DB? Use Zero Downtime Migration (ZDM) yourself to migrate easily to Astra DB.
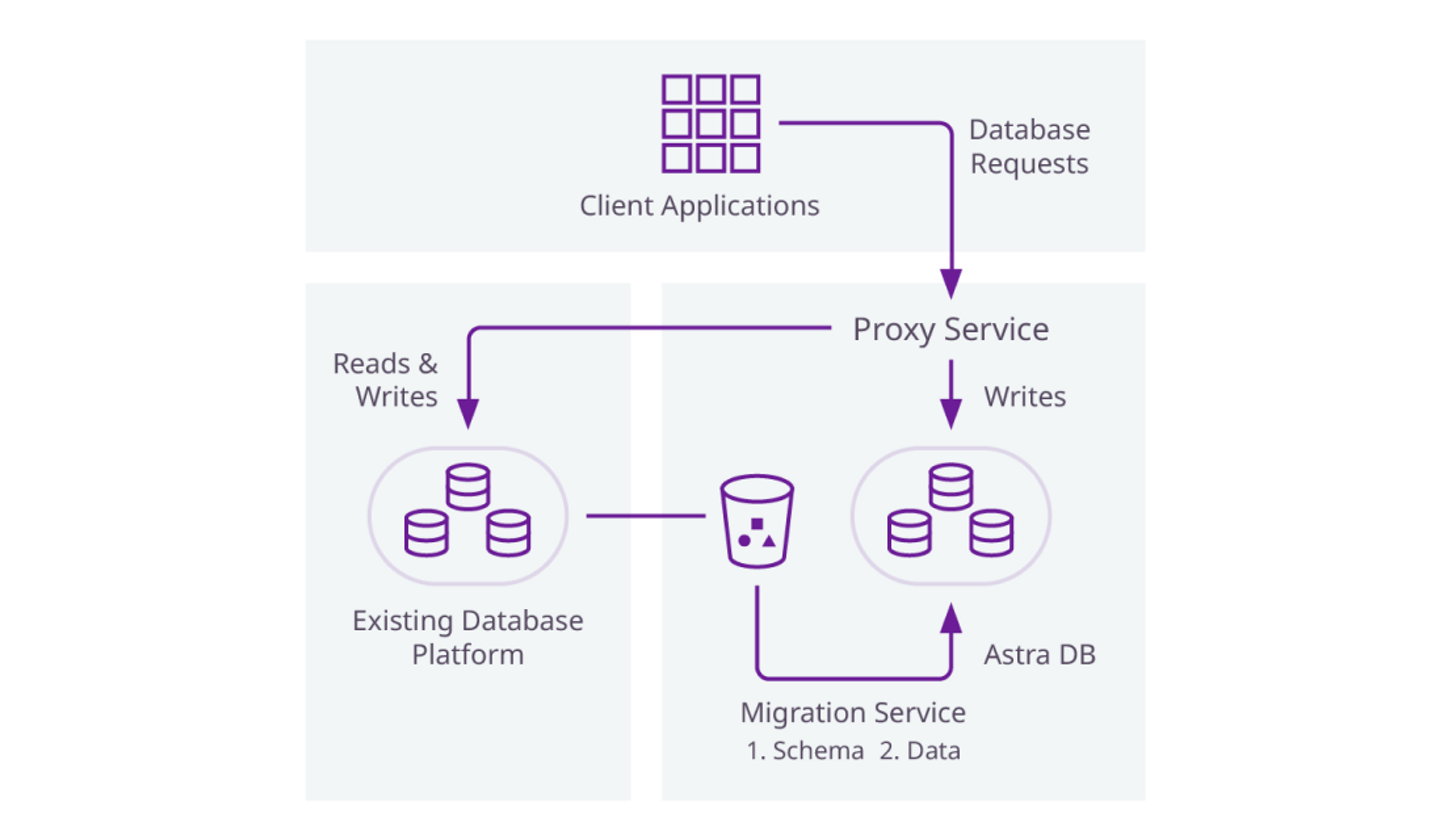
Get a migration assessment
DataStax can also help you with personalized sizing and TCO and build a customized migration plan with you.
Reviews
