

Flexibilität
Erfordert kein vordefiniertes Schema. Neue Datentypen und Felder können im laufenden Betrieb hinzugefügt werden.
NoSQL-Datenbanken wurden entwickelt, um Anforderungen von Cloud-Anwendungen zu unterstützen und die Einschränkungen traditioneller relationaler Datenbanken (RDBMS) in puncto Skalierung, Performance, Datenmodell und Datenverteilung zu überwinden.
Um NoSQL-Datenbanken besser zu verstehen, werfen wir zunächst einen Blick auf ihre Alternative: relationale Datenbanken. Die Programmiersprache SQL wurde entwickelt, um relationale Datenbanken auf einfache Weise abzufragen und zu ändern. Relationale Datenbanken, die SQL auf diese Weise nutzen, werden einfach als SQL-Datenbanken bezeichnet. Ihre Verwendung reicht bis in die frühen 1970er Jahre zurück, als die Datenspeicherung extrem teuer war. Aus diesem Grund wird die Datenduplizierung zwischen den Tabellen in relationalen Datenbanken minimiert. Dadurch sind SQL-Datenbanken zwar hochgradig organisiert, aber auch extrem unflexibel und schwierig zu ändern. Bevor die Datenbank erstellt wird, erfordert ihr Design viel Zeit und gründliche Überlegungen.
Seitdem sind die Speicherkosten stark gesunken, sodass es weitaus weniger wichtig ist, Zeit und Ressourcen zur Vermeidung von Datenduplizierung aufzuwenden. Stattdessen sind die Kosten für die Entwicklerzeit dramatisch gestiegen. Um die Entwicklerproduktivität zu maximieren, wurden NoSQL-Datenbanken entwickelt. Sie sind äußerst flexibel und benutzerfreundlich und nicht auf den Tabellenansatz beschränkt. Alle Datentypen können zusammen in derselben Datenstruktur gespeichert und abgerufen werden.
Weitere Schlüsselfaktoren bei der Entwicklung und Einführung von NoSQL waren das explodierende Datenvolumen und die immense Datenvielfalt. Seit dem Aufkommen des Internets in den 1990er Jahren gibt es eine ständig wachsende Datenflut; Daten kommen von überall und in allen Formen und Größen. Starre, tabellarische relationale Datenbanken eignen sich nicht mehr für die ständig wachsende Vielfalt von Datenquellen, darunter Web-Interaktionen, mobile Geräte, E-Commerce-Transaktionen, soziale Medien, Video, Audio, digitale Bilder, IoT-Sensoren, Analysen, Wetterdaten, KI, maschinelles Lernen und vieles mehr. Unternehmen brauchten einen Nachfolger von SQL – eine Datenbanklösung, die flexibel genug ist, um alle Datentypen, strukturierte und unstrukturierte, zu verarbeiten. Außerdem musste sich die Lösung kostengünstig skalieren lassen, um alle Informationen ungeachtet der stetig wachsenden Datenbestände zuverlässig zu speichern.
Führende Internetunternehmen wie Amazon, Google und Facebook spürten diese Herausforderung zuerst um die Jahrhundertwende. Als Antwort entwickelten sie NoSQL („Not only SQL“ oder „Non-SQL“), eine neue Lösung zum Speichern und Abrufen von Daten, die nicht länger auf relationalen Datenbanken beruhte. Diese Technologiegiganten benötigten massiv skalierbare Datenbankmanagementsysteme, die Daten überall auf der Welt schreiben und lesen konnten und gleichzeitig Milliarden von Benutzern Performance und Verfügbarkeit boten. Mit der ständigen Zunahme von Cloud Computing und Big Data müssen die meisten Unternehmen heute umfangreiche Anwendungen bereitstellen, die das Kundenerlebnis personalisieren. Die Datenbanktechnologie der Wahl zur Unterstützung solcher Systeme ist NoSQL.
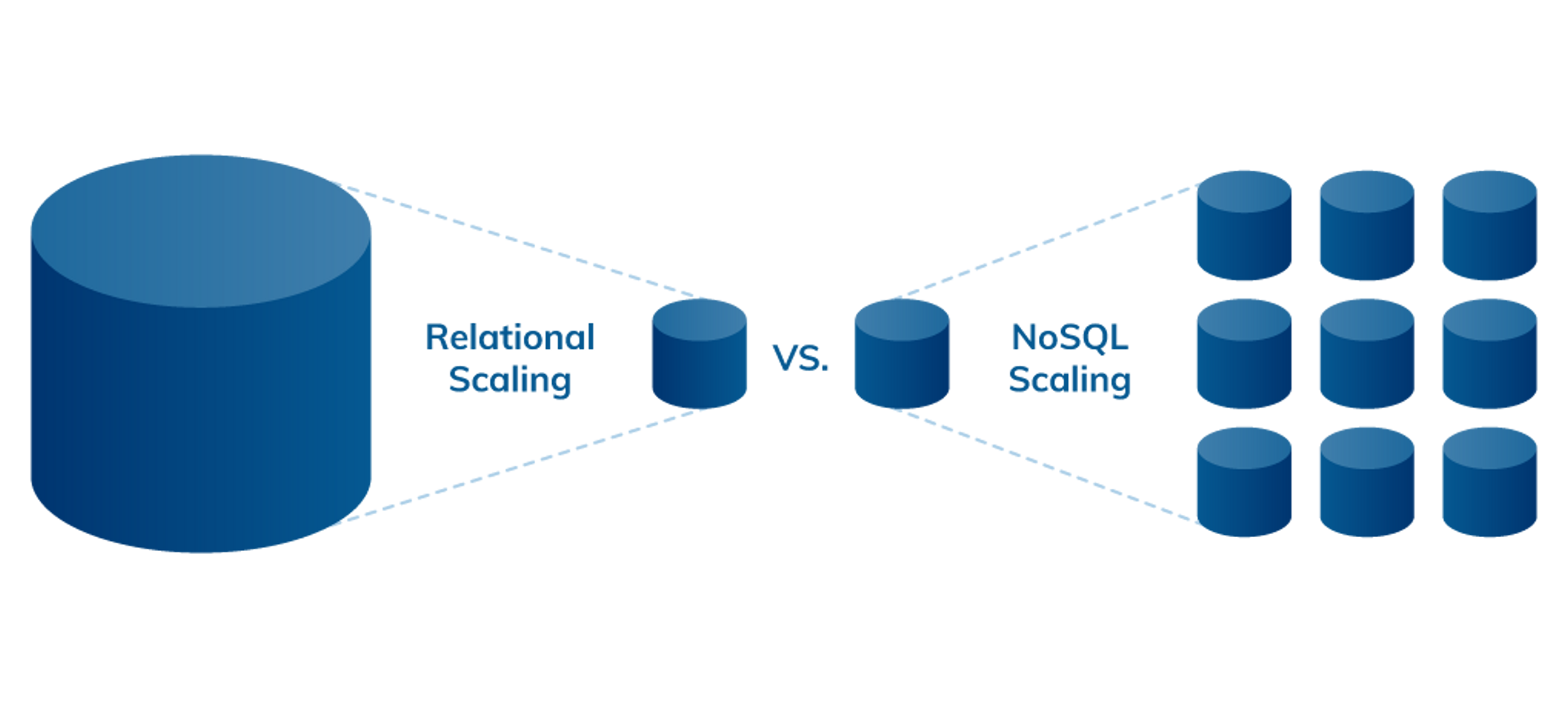
Wie unten dargestellt, ist die Skalierbarkeit einer der Hauptunterschiede zwischen relationalen und NoSQL-Datenbanken. Relationale Datenbanken werden in der Regel vertikal skaliert. Die Kapazität lässt sich dabei nur durch eine Erhöhung der Hardware-Leistung, z. B. bei RAM, CPU und SSD, auf dem vorhandenen Server oder durch Migration auf einen größeren, teureren Server erweitern. Dagegen werden NoSQL-Datenbanken horizontal skaliert. Anstatt teure Hardware aufzurüsten, können sie einfach und kostengünstig durch das Hinzufügen handelsüblicher Server oder Cloud-Instanzen erweitert werden.
NoSQL- und RDBMS-Datenbanken (wie SQL) erfüllen unterschiedliche Anwendungsanforderungen und werden in Unternehmen häufig nebeneinander eingesetzt, um diverse Anwendungsfälle zu unterstützen. Zu den wichtigsten technischen Entscheidungskriterien gehören:
Relationale Datenbanken | NoSQL | |
|---|---|---|
Anwendungsfall | Zentralisierte, monolithische Anwendungen | Dezentralisierte (hochgradig skalierbare) Microservice-Anwendungen |
Verfügbarkeit | mittlere bis hohe Verfügbarkeit | kontinuierliche Verfügbarkeit, null Ausfallzeiten |
Geschwindigkeit | moderat schnelle Daten | schnelle Daten (Geräte, Sensoren etc.) |
Datentypen | hauptsächlich strukturierte Daten | strukturierte, halbstrukturierte oder unstrukturierte Daten |
Transaktionen | komplexe/verschachtelte Transaktionen und Verknüpfungen | einfache Transaktionen und Abfragen |
Lesen und Schreiben | Skalierung von Lesevorgängen | Skalierung von Schreib- und Lesevorgängen |
Skalierbarkeit | Scale-up (auch „vertikale Skalierbarkeit“ genannt) | Scale-out (auch „horizontale Skalierbarkeit“ genannt) |
NoSQL kann zudem mehrere Datenbanktypen vorweisen, sodass Sie flexibel auswählen können, welcher Typ für Ihre Daten und Ziele am besten geeignet ist. Die Haupttypen sind:
Key-Value-Datenbanken
Key-Value-Datenbanken gehören zu den am wenigsten komplexen NoSQL-Datenbanken, da alle ihre Daten aus einem indizierten Schlüssel (Key) und einem Wert (Value) bestehen. Sie verwenden einen Hash-Mechanismus, sodass die Datenbank bei einem bestimmten Schlüssel schnell einen zugehörigen Wert abrufen kann. Hashing-Mechanismen bieten konstanten Zeitzugriff, sodass auch bei großen Datenmengen eine hohe Performance aufrechterhalten werden kann. Die Schlüssel können jede Art von Objekt sein, sind aber typischerweise ein String. Die Werte sind in der Regel undurchsichtige Blobs (d. h. eine Folge von Bytes, die die Datenbank nicht interpretiert). Sie erleichtern das Speichern großer Datenmengen und das schnelle Durchführen von Suchabfragen.
Beispiele
Einige tabellarische NoSQL-Datenbanken wie Cassandra können auch Key-Value-Anforderungen erfüllen.
Dokumentendatenbanken
Dokumentendatenbanken erweitern die Grundidee von Key-Value-Speichern, wobei „Dokumente“ komplexer sind, da sie Daten enthalten und jedem Dokument ein eindeutiger Schlüssel zugewiesen wird, der zum Abrufen des Dokuments verwendet wird. Diese Datenbanken sind für die Speicherung, den Abruf und die Verwaltung dokumentenorientierter Daten, die häufig als JSON gespeichert werden, konzipiert. Jedes Dokument kann unterschiedliche Datentypen enthalten. Gruppen von Dokumenten werden als Sammlungen bezeichnet. Jedes Dokument in einer Sammlung kann eine andere Struktur haben.
Da die Dokumentendatenbank die Dokumentinhalte prüfen kann, ist die Datenbank in der Lage, zusätzliche Abrufe zu verarbeiten. Im Gegensatz zu RDBMS, die ein statisches Schema erfordern, haben Dokumentendatenbanken ein flexibles Schema, das durch den Dokumentinhalt definiert wird.
Beispiele
Beachten Sie, dass einige RDBMS- und NoSQL-Datenbanken außerhalb reiner Dokumentenspeicher JSON-Dokumente speichern und abfragen können, einschließlich Cassandra.
Tabellarische Datenbanken
Tabellarische Datenbanken organisieren Daten in Zeilen und Spalten, aber mit einer Veränderung gegenüber traditionellen RDBMS. Die so genannten Wide-Column-Speicher oder Partitioned-Row-Speicher bieten die Möglichkeit, verwandte Zeilen in Partitionen zu organisieren, die zusammen auf denselben Replikaten gespeichert werden, was schnelle Abfragen begünstigt.
Im Gegensatz zu RDBMS besteht nicht unbedingt ein striktes Tabellenformat. Beispielsweise verlangt Apache Cassandra™ nicht, dass alle Zeilen Werte für alle Spalten in der Tabelle enthalten. Wie Key-Value- und Dokumentdatenbanken verwenden tabellarische Datenbanken Hashing, um Zeilen aus der Tabelle abzurufen.
Beispiele
Graphdatenbanken
Graphdatenbanken speichern ihre Daten unter Verwendung einer Graphmetapher, um die Beziehungen zwischen Daten auszunutzen. Knoten im Graph sind die Datenelemente, während Kanten die Beziehungen zwischen den Datenelementen darstellen. Graphdatenbanken sind für hochkomplexe und verbundene Daten konzipiert, die die Beziehungs- und Verknüpfungskapazitäten eines RDBMS überschreiten. Graphdatenbanken sind oft außergewöhnlich gut darin, Gemeinsamkeiten und Anomalien in großen Datenbeständen zu finden.
Beispiele
Multi-Modell-Datenbanken
Multi-Modell-Datenbanken sind sowohl auf dem NoSQL- als auch auf dem RDBMS-Markt stark im Kommen. Sie sind darauf ausgelegt, mehrere Datenmodelle für ein einziges, integriertes Backend zu unterstützen. Die meisten Datenbankmanagementsysteme sind um ein einziges Datenmodell herum organisiert, das festlegt, wie Daten organisiert, gespeichert und bearbeitet werden können. Im Gegensatz dazu bietet eine Multi-Modell-Datenbank die Möglichkeit, Teile der Systemdaten in verschiedenen Datenmodellen zu speichern, was die Anwendungsentwicklung vereinfacht.
NoSQL-Datenbanken dienen in erster Linie dazu, dezentralisierte Systeme für Cloud-Anwendungen zu unterstützen. Eine NoSQL-Datenbank wie Cassandra bietet typischerweise folgende Vorteile gegenüber anderen Datenbankmanagementsystemen:
Erfordert kein vordefiniertes Schema. Neue Datentypen und Felder können im laufenden Betrieb hinzugefügt werden.
Die Datenbank bleibt selbst bei katastrophalen Infrastrukturausfällen verfügbar.
Aktive Daten, wo auch immer Sie diese benötigen.
Ausreichend schnelle Antwortzeiten für Ihre intensivsten operativen Cloud-Anwendungen.
Vorhersehbare Skalierbarkeit (Scale-out und Scale-in) für aktuelle und künftige Datenanforderungen von Cloud-Anwendungen.
Einheitliche Integration und Interoperabilität gemischter Workloads und mehrerer Datenmodelle.
Enterprisefähige Datenverwaltung für Cloud-Anwendungen.
Keine Investition in spezialisierte Hardware oder zusätzliche Software nötig.
Auf dem Markt gibt es viele verschiedene NoSQL-Datenbanken. Die wichtigsten Differenzierungsmerkmale sind:
NoSQL-Datenbanken können nach dem Datenmodell, das sie unterstützen, klassifiziert werden. Manche unterstützen einen Wide-Row-Tabellenspeicher, andere ein dokumentenorientiertes, ein Key-Value- oder ein Graphenmodell. Mehr dazu weiter unten.
NoSQL ist bei Entwicklern wegen seiner Flexibilität und Benutzerfreundlichkeit beliebt. Ein Beispiel dafür ist das NoSQL-Konzept für Programmierschnittstellen (APIs). NoSQL bietet Entwicklern eine breite Palette von APIs, die das Interagieren mit und das Ändern von Daten erleichtern. Jedes NoSQL-Datenmodell – Key-Value, dokumentenorientiert, tabellarisch und Graph – verfügt über einen eigenen Satz von APIs. Und es gibt noch mehr Auswahl, da die verschiedenen NoSQL-Datenbanken unterschiedliche Entwicklungs-APIs anbieten. Cassandra unterstützt Cassandra Query Language, eine SQL-ähnliche Sprache, und andere APIs wie REST und GraphQL befinden sich in der Entwicklung.
NoSQL-Datenbanken replizieren Datenkopien über mehrere Server hinweg. So stellen sie sicher, dass die Daten immer verfügbar sind. Dies bietet Schutz vor Datenverlust, wenn einer der Datenbankserver ausfällt. Bei NoSQL-Datenbanken kommen zwei verschiedene Replikationsarchitekturen zum Einsatz: primär/sekundär und Peer-to-Peer.
Beim primären/sekundären Ansatz, der vor allem von MongoDB verwendet wird, erstellt das System einen Replikatsatz, der einen primären Replikatknoten und mehrere sekundäre Kopien enthält. Nur das primäre Replikat kann Datenaktualisierungen und Schreibanfragen verarbeiten. Änderungen am primären Replikat werden dann in den sekundären Kopien dupliziert. Das primäre Replikat kann den Prozess aufhalten, da es alle Aktualisierungen verarbeiten und weitergeben muss. Wenn beim primären Replikat ein Fehler auftritt, kann eine der sekundären Kopien seinen Platz einnehmen. Dieser Vorgang kann jedoch länger als 10 Sekunden dauern.
Cassandra, Couchbase und andere verwenden die Peer-to-Peer-Replikationsarchitektur. Bei diesem Ansatz haben alle Knoten in einem Datenbankcluster das gleiche Gewicht. Sie alle führen Lese- und Schreibvorgänge durch. Der Verlust eines von ihnen verursacht keine Ausfallzeit, da Anfragen von jedem der Knoten bearbeitet werden können. Außerdem kann die Performance verbessert werden, indem einfach weitere Knoten hinzugefügt werden. Der größte Nachteil der Peer-to-Peer-Replikation ist Inkonsistenz. Da Änderungen auf alle Knoten verteilt werden, können auf den noch nicht aktualisierten Knoten inkonsistente Daten vorhanden sein. Außerdem kann ein Konflikt entstehen, wenn derselbe Datensatz gleichzeitig auf zwei oder mehr verschiedenen Knoten eine Schreibaktualisierung erhält.
Aufgrund ihrer Architektur unterscheiden sich NoSQL-Datenbanken darin, wie sie das Lesen, Schreiben und Verteilen von Daten unterstützen. NoSQL-Plattformen wie Cassandra unterstützen Schreib- und Lesevorgänge auf allen Knoten in einem Cluster und können Daten zwischen vielen Rechenzentren und Cloud-Anbietern replizieren oder synchronisieren.
Erwähnen sollte man noch eine weitere neu entstandene Gruppe von Datenbanken. Die so genannten „NewSQL“-Datenbanken weisen viele der von NoSQL-Datenbanken eingeführten Prinzipien der verteilten Systemarchitektur auf und versuchen gleichzeitig, die vollständige relationale Semantik traditioneller RDBMS bereitzustellen. Diese Datenbanken, zu denen Google Cloud Spanner und Cockroach DB gehören, bieten andere Kompromisse als Cassandra und andere NoSQL-Datenbanken.
Informationen zum Benchmarking von NoSQL-DatenbankenWie können Sie konkret auf NoSQL umsteigen und Ihre erste Anwendung implementieren? Generell gibt es drei Möglichkeiten, die Einführung einer NoSQL-Datenbank anzugehen:
Viele steigen in NoSQL ein, indem sie es in neuen Cloud-Anwendungen implementieren und von Grund auf neu starten. Durch einen solchen Ansatz entfallen zum Beispiel Datenmigrationen und die Notwendigkeit, Anwendungen neu zu schreiben.
Manche beschließen, ein bestehendes System um eine NoSQL-Komponente zu erweitern. Das geschieht häufig bei Anwendungen, die aus einem RDBMS „herausgewachsen“ sind, sei es aufgrund von Skalierungsproblemen oder weil eine bessere Verfügbarkeit erforderlich ist.
Systeme, bei denen die Kosten steigen oder die prinzipiell an ihre Grenzen stoßen (z. B. aufgrund einer Zunahme der Datengeschwindigkeit, der Datenmenge oder der Anzahl an gleichzeitigen Benutzern), werden komplett durch eine NoSQL-Datenbank ersetzt.
Kostengünstige, horizontale Skalierung. Null Ausfallzeiten. Flexible Handhabung aller Datentypen und die Möglichkeit, Änderungen im laufenden Betrieb vorzunehmen. Mehrere Datenbanktypen für eine Vielzahl von Anwendungsfällen. NoSQL-Datenbanken haben viel zu bieten. Sind NoSQL-Datenbanken das Richtige für Ihre Datenumgebung und Ihre Unternehmensziele?