

Flexibilité
Ne nécessite pas de schéma prédéfini. De nouveaux types de données et champs peuvent être ajoutés à la volée.
Les bases de données NoSQL sont conçues pour répondre aux exigences des applications cloud et surmonter les limites des bases de données relationnelles classiques (SGBDR) en termes d’évolution, de performance, de modèle de données et de distribution.
Pour mieux comprendre les bases de données NoSQL, penchons-nous d’abord sur l’alternative, à savoir les bases de données relationnelles. Le langage de programmation SQL a été conçu comme un moyen facile d’interroger et de modifier les bases de données relationnelles. Les bases de données relationnelles qui utilisent SQL de cette manière sont simplement appelées bases de données SQL. Leur utilisation remonte au début des années 1970 à une époque où le stockage de données était très onéreux. Pour cette raison, la duplication de données entre les tables dans les bases de données relationnelles est réduite au minimum. Bien qu’extrêmement organisées, les bases de données SQL sont aussi de ce fait extrêmement inflexibles et difficiles à modifier. Il faut consacrer beaucoup de temps et de réflexion à leur conception avant de les créer.
Depuis cette époque, le coût du stockage a chuté, il est donc beaucoup moins important de consacrer du temps et des ressources à éliminer la duplication des données. À l’inverse, le coût du temps de développement a considérablement augmenté. Pour maximiser la productivité des développeurs, les bases de données NoSQL ont été conçues pour être extrêmement flexibles et faciles à utiliser sans se limiter à l’approche par table. Tous les types de données peuvent être stockés et sont accessibles ensemble dans la même structure de données.
Un autre facteur clé dans le développement et l’adoption de NoSQL est l’explosion du volume et de la diversité des données. Depuis l’essor de l’Internet dans les années 1990, le flot de données provenant de partout et sous toutes les formes n’a cessé de croître. Les bases de données relationnelles tabulaires rigides ne sont plus la bonne solution pour des sources de données toujours plus variées, dont les interactions Internet, les appareils mobiles, les transactions e-commerce, les réseaux sociaux, la vidéo, le son, les images numériques, les capteurs IoT, les analyses, les relevés météo, l’IA, le machine learning, etc. Les entreprises avaient besoin d’une suite à SQL, une solution de base de données possédant la flexibilité nécessaire pour gérer tous les types de données, structurées et non structurées, et capable d’évoluer à moindre coût pour tout stocker de manière rentable, peu importe le volume de la pile.
Les leaders d’Internet comme Amazon, Google et Facebook ont été les premiers à en prendre conscience au tournant du millénaire et ont créé NoSQL (signifiant « pas seulement SQL » ou « non SQL »), une nouvelle manière de stocker les données et d’y accéder qui ne s’appuyait plus sur les bases de données relationnelles. Ces géants de la tech avaient besoin de systèmes de gestion de bases de données très évolutifs capables d’écrire et de lire des données partout dans le monde tout en offrant performance et disponibilité à des milliards d’utilisateurs. Compte tenu de la croissance continue du cloud computing et du Big Data, aujourd’hui, la plupart des organisations doivent fournir des applications à grande échelle qui personnalisent l’expérience client. NoSQL est la technologie de base de données à privilégier pour mettre en place de tels systèmes.
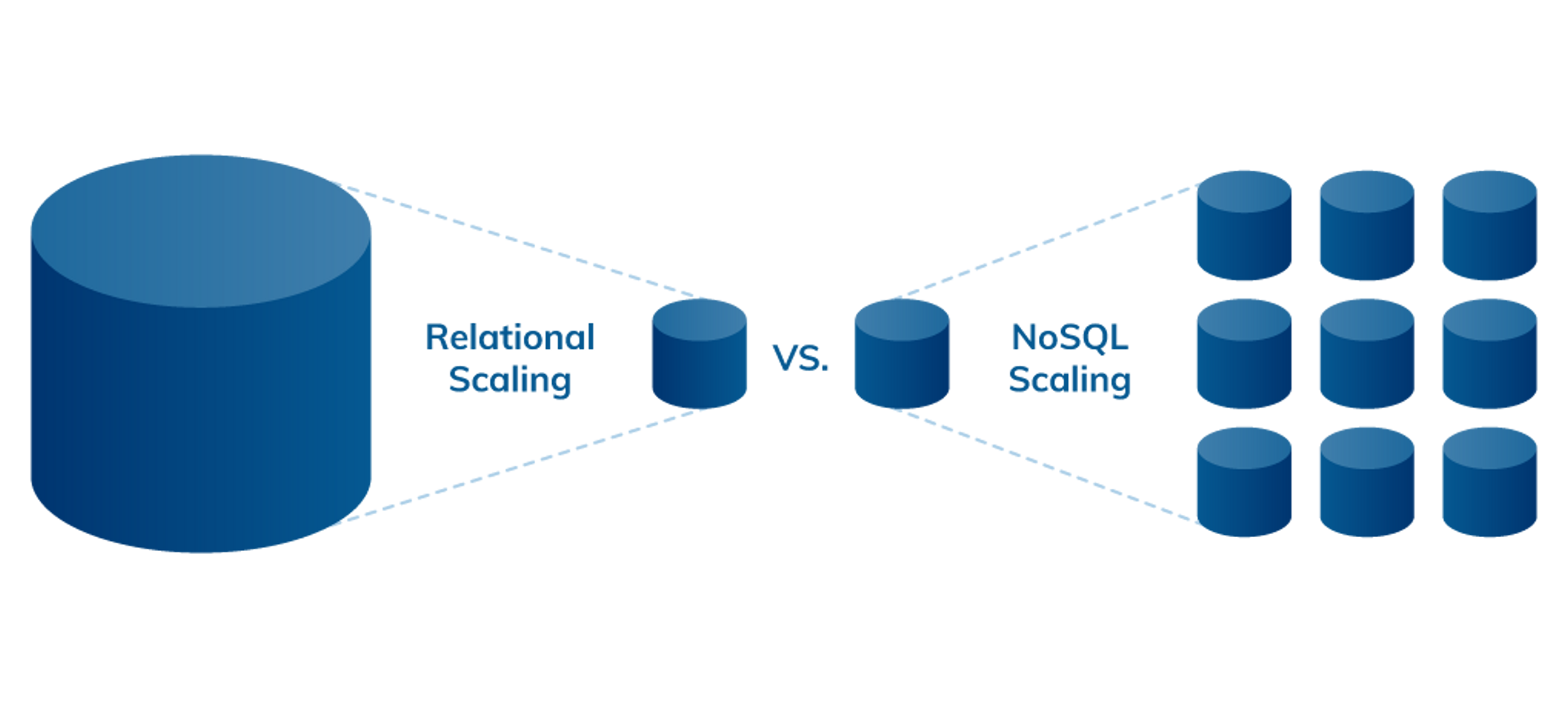
Comme vous le verrez plus loin, l’évolutivité est l’une des différences clés entre les bases de données relationnelles et NoSQL. La norme pour les bases de données relationnelles est la scalabilité verticale qui implique nécessairement l’augmentation des capacités comme la RAM, les processeurs et les SSD, sur le serveur existant ou en migrant vers un serveur plus grand et plus cher. Les bases de données NoSQL quant à elles offrent la scalabilité horizontale. Au lien d’exiger du matériel onéreux, elles peuvent s’étendre à moindre coût simplement grâce à l’ajout de serveurs standard ou d’instances cloud.
Les bases de données NoSQL et SDGBR (comme SQL) prennent en charge différentes exigences applicatives et coexistent fréquemment dans les entreprises pour s’adapter à différents cas d’utilisation. Les critères essentiels de choix technologique sont les suivants :
Bases de données relationnelles | NoSQL | |
|---|---|---|
Cas d’utilisation | Applications centralisées monolithiques | Applications de microservices décentralisées (hautement évolutives) |
Disponibilité | Disponibilité moyenne à élevée | Disponibilité continue, indisponibilité zéro |
Rapidité | Des données avec vitesse modérée | Des données avec vitesse élevée (appareils, capteurs, etc.) |
Types de données | Données principalement structurées | Structurées, semi-structurées ou non structurées |
Transactions | Jointures et transactions complexes/imbriquées | Requêtes et transactions simples |
Lecture et écriture | Évolution en lecture | Évolution en lecture et en écriture |
Évolutivité | Évolutivité verticale | Évolutivité horizontale |
NoSQL a aussi plusieurs types de bases de données qui vous donnent la flexibilité de choisir ce qui convient le mieux à vos données et objectifs. Les principaux types sont :
Bases de données clé-valeur
Les bases de données clé-valeur comptent parmi les bases de données NoSQL les moins complexes, car toutes leurs données sont constituées d’une clé indexée et d’une valeur. Elles utilisent un mécanisme de hachage de sorte que, sur la base d’une clé, la base de données peut récupérer rapidement une valeur associée. Les mécanismes de hachage offrent un accès constant, ce qui signifie qu’un haut de niveau de performance est maintenu même à large échelle. Les clés peuvent être n’importe quel type d’objet, mais ce sont habituellement une chaîne. Les valeurs sont généralement des blobs opaques (c’est-à-dire une séquence d’octets que la base de données n’interprète pas). Elles facilitent le stockage de gros volumes de données et l’exécution de requêtes rapides.
Exemples
Certaines bases de données tabulaires NoSQL, comme Cassandra, peuvent aussi répondre aux besoins de type clé-valeur.
Bases de données documentaires
Les bases de données documentaires développent l’idée de base des systèmes de stockage clé-valeur, les documents étant plus complexes dans le sens où ils contiennent des données et à chaque document est attribuée une clé unique utilisée pour récupérer le document. Elles sont conçues pour stocker, récupérer et gérer des informations orientées document, souvent stockées sous JSON. Chaque document peut contenir différents types de données. Des groupes de documents s’appellent des collections. Chaque document d’une collection peut avoir une structure différente.
Comme la base de données documentaire peut inspecter les contenus des documents, elle peut exécuter des processus de récupération supplémentaires. Contrairement aux SDGBR qui nécessitent un schéma statique, les bases de données documentaires ont un schéma flexible défini par les contenus des documents.
Exemples
Notez que certains SDGBR et bases de données NoSQL en dehors du stockage documentaire pur peuvent stocker et interroger des documents JSON, Cassandra inclus.
Bases de données tabulaires
Les bases de données tabulaires organisent les données en lignes et en colonnes avec un petit plus des SDGBR traditionnels. Aussi appelées « wide-column stores » ou « partitioned row stores », elles offrent l’option d’organiser les lignes liées en partitions stockées ensemble sur les mêmes réplicas pour permettre des requêtes plus rapides.
Contrairement au SDGBR, le format tabulaire n’est pas nécessairement strict. Par exemple, Apache Cassandra™ n’exige pas que toutes les lignes contiennent des valeurs pour toutes les colonnes de la table. Comme les bases de données clé-valeur et documentaires, les bases de données tabulaires utilisent le hachage pour récupérer des lignes de la table.
Exemples
Bases de données orientées graphe
Les bases de données orientées graphe stockent leurs données en utilisant une métaphore de graphe pour exploiter les relations entre les données. Les nœuds dans le graphe représentent des éléments de données et les liens représentent les relations entre les éléments. Les bases de données orientées graphe sont conçues pour les données hautement complexes et connectées qui dépassent les capacités d’un SDGBR en termes de relations et de jointures. Les bases de données orientées graphe sont souvent exceptionnellement aptes à identifier les points communs et les anomalies sur de vastes ensembles de données.
Exemples
Bases de données multimodèles
Les bases de données multimodèles constituent une tendance émergente sur les marchés NoSQL et SDGBR. Elles sont conçues pour prendre en charge plusieurs modèles de données avec un seul back-end intégré. La plupart des systèmes de gestion de bases de données sont organisés autour d’un modèle de données unique qui détermine la manière dont les données peuvent être organisées, stockées et manipulées. À l’inverse, une base de données multimodèle permet à une entreprise de stocker des parties des données du système dans différents modèles, ce qui simplifie le développement d’applications.
Les bases de données NoSQL sont principalement conçues pour prendre en charge des systèmes décentralisés qui visent les applications cloud. Une base de données NoSQL comme Cassandra offre généralement les avantages suivants par rapport aux autres systèmes de gestion de bases de données :
Ne nécessite pas de schéma prédéfini. De nouveaux types de données et champs peuvent être ajoutés à la volée.
Une base de données qui reste en ligne même en cas de panne d’infrastructure extrêmement dévastatrice.
Des données entièrement actives, partout où vous en avez besoin.
Des délais de réponse suffisamment rapides pour vos applications cloud opérationnelles les plus intenses.
Effectuez des scale-out et scale-in de manière prévisible pour satisfaire les besoins en données actuels et futurs des applications cloud.
Une intégration cohérente et interopérabilité des charges de travail mixtes et des modèles de données multiples.
Gestion des données professionnelle pour les applications cloud.
Ne nécessite pas de matériel spécialisé ou de logiciel supplémentaire.
Il existe une grande diversité de bases de données NoSQL sur le marché qui diffèrent principalement les unes des autres via les éléments clés suivants :
Nous pouvons classer les bases de données NoSQL en fonction de leur modèle de données. Certaines prennent en charge un magasin tabulaire « wide-row », tandis que d’autres prennent en charge un modèle qui peut être orienté documents, clé-valeur ou graphe. Voir plus loin.
NoSQL est apprécié des développeurs pour sa flexibilité et de sa facilité d’utilisation. Un des exemples en la matière est son approche des interfaces de programmation (API). NoSQL offre aux développeurs un large éventail d’API, ce qui facilite l’interaction avec les données et leur modification. Chaque modèle de données NoSQL (clé-valeur, documents, tabulaire et graphe) a son propre ensemble d’API. Le choix est encore plus vaste grâce aux différentes bases de données NoSQL offrant différentes API de développement. Cassandra prend en charge le langage de requête Cassandra, un langage similaire à SQL, et d’autres API comme REST et GraphQL, sont en développement.
Les bases de données NoSQL garantissent que les données sont toujours disponibles en répliquant des copies sur plusieurs serveurs. Cela protège de la perte de données si l’un des serveurs de la base de données tombe en panne. Deux architectures de réplication différentes sont utilisées dans les bases de données NoSQL : primaire/secondaire et peer-to-peer.
Avec l’approche primaire/secondaire, notamment utilisée par MongoDB, un ensemble de réplicas est créé qui contient un nœud de réplication primaire et plusieurs copies secondaires. Seul le réplica primaire peut gérer les mises à jour de données et les requêtes d’écriture. Les modifications sur le nœud primaire sont ensuite dupliquées sur les secondaires. Le primaire peut ralentir le processus puisqu’il doit gérer et transmettre toutes les mises à jour. En cas de problème avec le primaire, l’un des secondaires peut prendre sa place. Ce processus peut toutefois prendre plus de 10 secondes.
Cassandra, Couchbase et d’autres utilisent une architecture de réplication peer-to-peer. Avec cette approche, tous les nœuds d’un cluster de bases de données possèdent un poids équivalent. Ils peuvent tous lire et écrire des données. La perte de l’un d’entre eux n’occasionne aucune interruption parce que les requêtes peuvent être gérées par n’importe quel nœud. La performance peut être améliorée par le simple ajout de nœuds supplémentaires. Le manque de cohérence est l’inconvénient majeur de la réplication peer-to-peer. Comme les changements sont diffusés sur tous les nœuds, il peut y avoir des données divergentes sur ceux qui n’ont pas encore été mis à jour. De plus, un conflit peut survenir si le même enregistrement reçoit une mise à jour d’écriture en même temps sur deux nœuds différents ou plus.
Étant donné leurs différences d’architecture, les bases de données NoSQL diffèrent sur la manière dont elles prennent en charge la lecture, l’écriture et la distribution des données. Les plateformes NoSQL comme Cassandra prennent en charge l’écriture et la lecture sur chaque nœud d’un cluster et peuvent répliquer ou synchroniser les données pour de nombreux datacenters et fournisseurs cloud.
Il convient aussi de noter qu’un ensemble de bases de données appelées « bases de données NewSQL » ont émergé, elles adoptent de nombreux principes d’architecture de système distribuée introduits par les bases de données NoSQL tout en essayant de fournir toute la sémantique relationnelle des SGBDR traditionnels. Ces bases de données incluent Google Cloud Spanner et Cockroach DB et offrent une série de contreparties différentes de Cassandra et autres bases de données NoSQL.
Découvrez comment comparer les bases de données NoSQLComment, concrètement, opérer la transition NoSQL et mettre en œuvre votre première application ? En général, il existe trois méthodes pour mettre en œuvre une base de données NoSQL :
Beaucoup se lancent dans NoSQL en l’appliquant à de nouvelles applications cloud et partent de zéro. Cette approche évite les soucis liés aux réécritures d’applications et aux migrations de données.
Certaines choisissent d’étendre un système existant en y ajoutant un composant NoSQL. Cela est fréquent avec les applications devenues trop encombrantes pour un SGBDR suite à des exigences d’évolutivité ou de plus grande disponibilité.
Pour les systèmes qui deviennent trop onéreux ou qui montrent de nombreux signes de faiblesse, par exemple en termes de nombre d’utilisateurs simultanés, de vitesse ou de volume des données, il convient de remplacer intégralement le système par une base de données NoSQL.
Les bases de données NoSQL présentent de nombreux avantages : rentabilité, évolutivité horizontale, indisponibilité zéro, la flexibilité de gérer tous les types de données et de faire des changements à la volée, plusieurs types de bases de données pour faire face à différents cas d’utilisation. Sont-elles adaptées à votre environnement de données et à vos objectifs organisationnels ?