

柔軟性
あらかじめスキーマを定義する必要はなく、新しいデータタイプ、フィールドを即座に追加することが可能。
NoSQLデータベースは、クラウドアプリケーションの要件を満たし、従来のリレーショナル・データベース(RDBMS)の拡張性、パフォーマンス、データモデル、データ・ディストリビューションに対する制限という課題を克服するために設計されています。
NoSQLをより深く理解するために、まずはリレーショナル・データベースについて確認しておきましょう。SQLというプログラミング言語は、リレーショナル・データベースを簡単に照会・変更することを目的に設計されました。このSQLを使って書き込み・読み取りをするリレーショナル・データベースを、”SQLデータベース” と呼びます。”SQLデータベース”が使われるようになったのは、1970年代初頭、データ・ストレージが高価だった時代にさかのぼります。データの保存量を少なくするため、リレーショナル・データベースは、テーブル間のデータの重複を最小限に抑え、テーブル間のデータを整理整頓し、アクセスを高速にしています。その反面、柔軟性に欠け、変更が難しくなっています。データベースを構築する前に、その設計にかなりの時間と思考を費やす必要があるのです。
その後、ストレージのコストが急速に下がり、データの重複と排除に時間とリソースを費やすことの重要性が激減しました。その代わり、開発者の人件費は劇的に増加しました。このような背景から、NoSQLデータベースは、開発者の生産性を最大限に高めるために、柔軟性と開発の容易性を重視して設計されました。テーブルアプローチに限定されず、すべてのデータ型を同じデータ構造にまとめて保存し、アクセスすることを可能にしたのです。
NoSQLが発展し、採用されたもう一つの大きな理由は、処理しなければならないデータの量と種類の爆発的な増加にあります。1990年代のインターネットの台頭以来、データは増え続け、あらゆるところから、あらゆる形や大きさで集まってきています。インターネット、モバイル機器、電子商取引、ソーシャルメディア、ビデオ、オーディオ、デジタル画像、IoTセンサー、分析、気象観測、AI、機械学習など、拡大し続けるデータソースに対して、表形式のデータでなければ扱えないリレーショナル・データベースでは対応しきれなくなってきているのです。構造化、非構造化を問わず、あらゆる種類のデータを扱える柔軟性と、どんなにデータが膨大になったとしても、そのすべてを確実に保存できる、コスト効率の良い拡張性。これらを備えたソリューションが、SQLに代わる新しい技術として企業に求められるようになったのです。
Amazon、Google、Facebookといったインターネット界のリーダーたちが今世紀に入ったころから最初にこの痛みを感じていました。そして、リレーショナル・データベースに依存しない、新しいデータ保存・アクセス方法、NoSQL(not-only-SQL、非SQL)を作り出しました。これらの巨大テック企業は、世界のどこにいてもデータの書き込みと読み出しが可能で、しかも何十億人ものユーザーに十分なパフォーマンスと可用性を提供できる、大規模なスケーラブル・データベース管理システムを必要としていたのです。クラウドコンピューティングとビッグデータの継続的な増加に伴い、各企業は顧客エクスペリエンスをパーソナライズする大規模なアプリケーションが求められています。NoSQLは、このようなシステムを強化するためのデータベース技術として選ばれています。
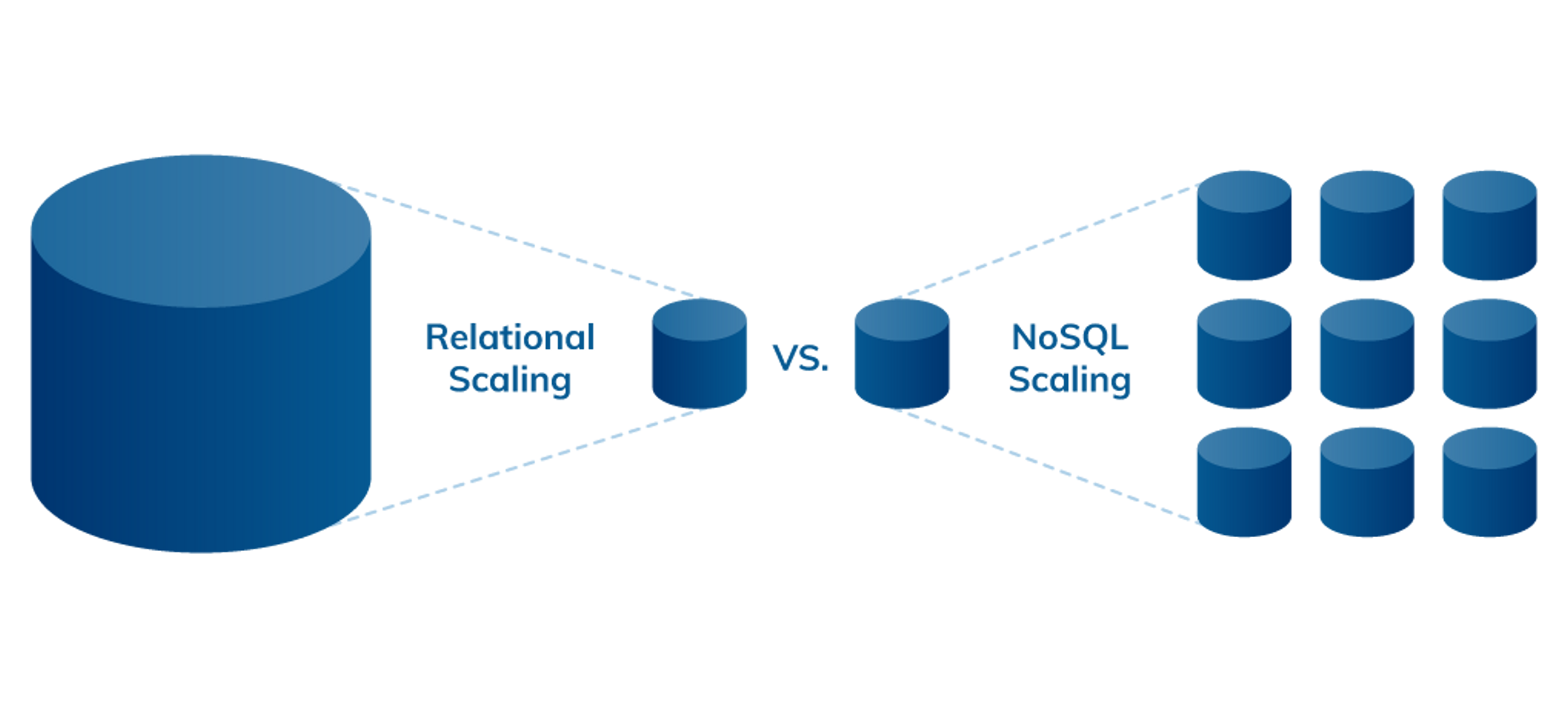
下図に示すように、リレーショナルデータベースとNoSQLデータベースの大きな違いの1つは、スケーラビリティ(拡張性)です。リレーショナルデータベースは垂直方向にスケールアップするのが一般的で、既存のサーバーのRAM、CPU、SSDなどの性能を上げるか、より大規模で高価なサーバーに移行することなどでキャパシティを拡張します。一方、NoSQLデータベースは水平方向にスケールアウトします。このため、高価なハードウェアにアップグレードするのではなく、一般的なサーバーやクラウドインスタンスを追加するだけの、安価に拡張が可能なのです。
NoSQLとリレーショナル・データベース(SQLなど)は、異なるアプリケーション要件をサポートしています。そのため企業内では、双方を採用し、それぞれに異なるユースケースをサポートさせることがよくあります。どちらをどのアプリケーションで採用するか、主な技術的判断基準としては以下のようなものがあります。
リレーショナル・データベース | NoSQL | |
|---|---|---|
ユースケース | 中央集中型、モノリシック・アプリケーション | 分散型(高スケーラブル)、マイクロサービス・アプリケーション |
可用性 | 中位から高位までの可用性 | 継続性、ゼロ・ダウンタイム |
速度 | 中速データ | 高速データ(デバイス、センサーなど) |
データ・タイプ | 主として構造化データ | 構造化、準構造化、非構造化データ |
トランザクション | 複雑/構造化されたトランザクションとジョイン | シンプルなトランザクションとクエリ |
読み取り+書き込み | 読み取りのスケーリング | 書き込み、読み取り双方のスケーリング |
スケーラビリティ | スケールアップ (`別名:垂直スケーラビリティ) | スケールアウト(別名:水平スケーラビリティ) |
また、NoSQLにはいくつかのデータベース・タイプがあり、データや目的に応じて最適なものを柔軟に選択することが可能です。主なタイプは以下の通りです。
キー・バリュー型データベース
キー・バリュー型データベースは、NoSQLデータベースの中でも最も複雑度の低いデータベースであり、すべてのデータがインデックス付きのキーと値(バリュー)で構成されています。キーはハッシング・メカニズムによって作成され、そのキーを使ってデータベースは関連する値を素早く取得することができるのです。ハッシング・メカニズムにより、データへの定常的なアクセス、大規模なデータベース・システムでの高いパフォーマンスの維持が可能になります。キーはどのようなタイプのオブジェクトでも作成できますが、通常は文字列です。値は一般に不透明なブロブ(データベースが解釈できないバイト列)となっています。これにより、大量のデータの保存や、検索クエリーの実行が容易になります。
データベース例
Cassandraのような表形式のNoSQLデータベースは、キー・バリュー型のニーズにも応えることができます。
ドキュメント型データベース
ドキュメント型データベースは、キー・バリュー型の基本的な考え方を発展させたもので、「ドキュメント(文書)」がデータを含み、各ドキュメントには一意のキーが割り当てられ、データベースはそのキーを使ってドキュメントを検索します。このデータベースは、ドキュメント指向の情報を保存、検索、管理するために設計されており、情報のほとんどがJSON (JavaScript Object Notation) として保存されます。各文書はさまざまな種類のデータを含むことができます。ドキュメントをグループ化したものはコレクションと呼ばれ、コレクション内の各文書は異なる構造を持つことができます。
ドキュメント型データベースは、ドキュメントに含まれるコンテンツを調査することができるため、検索処理の追加が可能です。静的なスキーマを必要とするリレーショナル・データベースとは異なり、ドキュメント型データベースは、ドキュメントのコンテンツによって定義される、柔軟、動的なスキーマを利用することができます。
データベース例
注:ドキュメント型に特化したデータベース以外のリレーショナル・データベースやNoSQLデータベースにも、Cassandraなど、JSONドキュメントの保存とクエリーが可能なものがあります。
テーブル型データベース
テーブル型データベースは、行と列でデータを整理するデータベースですが、従来のリレーショナル・データベースとは一味違います。ワイド・カラム・ストアや、パーティションド・ロー・ストアとも呼ばれ、関連する行(row) をパーティションで整理し、同じレプリカにまとめて格納することで、高速な検索を可能にします。
リレーショナル・データベースとは異なり、表の形式は厳密ではありません。たとえば、Apache Cassandra™の場合、すべての行がテーブルのすべての列の値を含んでいる必要はありません。キー・バリュー型データベースや、ドキュメント型データベースと同様に、テーブル型データベースは、テーブルから行を取得する際にハッシュのメカニズムを使用します。
データベース例
グラフ型データベース
グラフ型データベースは、データ間の関係を、グラフの形で保存します。グラフのノードはデータ項目を表し、エッジはデータ項目間の関係を表します。グラフ型データベースは、複雑な結びつきの強いデータ向けに設計されており、リレーショナル・データベースの関係性や結合性をはるかに超える能力を有しています。グラフ型データベースは、大規模なデータセットの中から共通点や異常値を見つけ出すことに優れています。
データベース例
マルチモデル・データベース
マルチモデル・データベースは、NoSQLとリレーショナル・データベースの両市場において新たなトレンドとなっています。このデータベースは、単一の統合されたバックエンドに対して、複数のデータ・モデルをサポートするように設計されています。ほとんどのデータベース管理システムは、データの編成、保存、操作の方法は単一のデータ・モデルを中心に設計・構成されています。これに対し、マルチモデル・データベースでは、システムのデータの一部を異なるデータ・モデルに格納し、アプリケーションの開発を簡素化することが可能です。
NoSQLデータベースは、主にクラウドアプリケーションを対象とした分散型システムをサポートするために設計されています。CassandraのようなNoSQLデータベースには、他のデータベース管理システムと比べて以下のようなメリットがあります。
あらかじめスキーマを定義する必要はなく、新しいデータタイプ、フィールドを即座に追加することが可能。
インフラの障害においても、データベースはオンラインのままで稼働を継続。
分散した地点のどこからでも、アクティブなデータにアクセスすることが可能。
高い負荷のかかるクラウドアプリケーションに対しても、低レイテンシーと高速なレスポンスを維持。
拡張を続けるクラウドアプリケーションの現在のデータニーズだけではなく、将来のデータニーズにも応えるために、予測可能なスケールアウトとスケールインを実現。
混在するワークロードと複数のデータモデルに対して首尾一貫した統合性と相互運用性を提供。
クラウドアプリケーションのためのEnterprise-readyなデータ管理を実現。
専用のハードウェアやソフトウェアを必要とせず、運用コストを抑えることが可能。
市場には、さまざまなNoSQLがあります。その違いについて、下記にまとめました。
NoSQLデータベースは、サポートするデータモデルによって分類することができます。表形式をサポートするものもあれば、ドキュメント型、キーバリュー型、グラフ型といったモデルをサポートするものもあります。こちらについては、後述します。
NoSQLは、その柔軟性と使い易さから、開発者の間で人気があります。その一例が、アプリケーション・プログラミング・インターフェース(API)に対するアプローチです。NoSQLは開発者に幅広いAPIを提供し、データの操作や変更を容易にしています。NoSQLのデータモデル(キーバリュー型、ドキュメント型、表形式、グラフ型)は、それぞれ独自のAPIを備えています。さらに、さまざまなNoSQLデータベースが異なる開発用APIを提供しているため、選択肢はさらに広がります。CassandraはSQLに似たCassandra Query Languageをサポートしており、RESTやGraphQLといった他のAPIも開発中です。
NoSQLデータベースは、複数のサーバーにデータを複製し、いつでも利用可能な状態にしています。これにより、データベース・サーバーのいずれかに障害が発生した場合でも、データの損失を防ぐことができます。NoSQLデータベースには、プライマリー/セカンダリー方式とピアツーピア方式の2種類のレプリケーション・アーキテクチャが使用されています。
MongoDBで主に使われているプライマリー/セカンダリー方式では、1つのプライマリー・レプリカノードと複数のセカンダリー・コピーを含むレプリカセットが作成されます。データの更新や書き込みができるのはプライマリー・レプリカだけです。プライマリー・レプリカへの変更は、セカンダリー・レプリカに複製されます。この方式の欠点は、プライマリー・レプリカがすべての更新を処理し、セカンダリー・レプリカに受け渡さなければならないため、処理を滞らせる可能性があることです。また、もしプライマリー・レプリカに何か問題が発生した場合は、セカンダリー・レプリカの1つがその代わりを務めますが、この処理には10秒以上かかることがあります。
Cassandra、Couchbaseなどは、ピア・ツー・ピア方式のレプリケーション・アーキテクチャを採用しています。このアプローチでは、データベース・クラスター内のすべてのノードが同じ役割を持ち、すべてのノードがデータの読み取りと書き込みを行います。この方式の利点は、どのノードでもリクエストを処理できるため、どれか1つが欠けてもダウンタイムが発生しないことです。また、ノードを追加するだけで、パフォーマンスを向上させることが可能です。この方式の欠点は、非同期性です。変更が全ノードに及ぶと、まだ更新されていないノードとの間でデータの一貫性が失われる可能性があります。また、同じレコードが2つ以上の異なるノードで同時に書き込み更新を受けると、データの競合が発生する可能性があります。
NoSQLデータベースは、そのアーキテクチャの違いから、利用できるデータの読み取り、書き込み、および配布の方式に違いがあります。CassandraのようなNoSQLプラットフォームは、クラスタ内のすべてのノードで書き込みと読み取りをサポートし、多くのデータセンターやクラウドプロバイダー間でデータの複製や同期を行うことが可能です。
また、”NewSQL” データベースと呼ばれる一連のデータベースも登場しました。従来のRDBMSの完全なリレーショナル・セマンティックスを提供しようとしながら、NoSQLデータベースが導入した分散システム・アーキテクチャの原理の多くを採用していることが注目に値すると言えます。これらのデータベースには、Google Cloud SpannerやCockroach DBなどがあり、Cassandraやその他のNoSQLデータベースとは異なるトレードオフ・セットを提供しています。
NoSQLデータベースのベンチマークについて学ぶ具体的に、実際にNoSQLに移行して最初のアプリケーションを実装するためには、どのように進めればよいのでしょうか?一般的に、NoSQLデータベースの導入には3つのアプローチがあります。
ほとんどの場合、新しいクラウド・アプリケーションにNoSQLを適用して、最初から構築することになります。このアプローチの場合は、アプリケーションの書き換えや、データ移行に伴う厄介な作業を回避することが可能です。
既存のシステムにNoSQLのコンポーネントを追加してシステムを増強する、という選択もあります。これは、規模の拡大や可用性を高める必要が生じ、RDBMSでは対処しきれなくなったアプリケーションに対してよく行われる対策です。
コストの増大や、並行処理、データ速度、データ量の増加により既存のシステムでのこれ以上の継続が難しい場合は、NoSQLデータベースへの全面的な置き換え(システム・リプレース)を実施します。
費用対効果の高い水平スケーリング。ゼロ・ダウンタイム。あらゆるデータ型に対応し、オンザフライで変更を加えることができる柔軟性。様々なユースケースに対応するための複数のデータベースタイプ。NoSQLデータベースには、多くの魅力があります。御社のデータ環境と組織の目標に合っているのではないでしょうか?