Webinar: Streaming Big Data with Spark, Spark Streaming, Kafka, Cassandra and Akka

Helena Edelson

About The Presenter: Helena Edelson is a committer on several open source projects including the Spark Cassandra Connector, Akka and previously Spring Integration and Spring AMQP. She is a Senior Software Engineer on the Analytics team at DataStax, a Scala and Big Data conference speaker, and has presented at various Scala, Spark and Machine Learning Meetups.
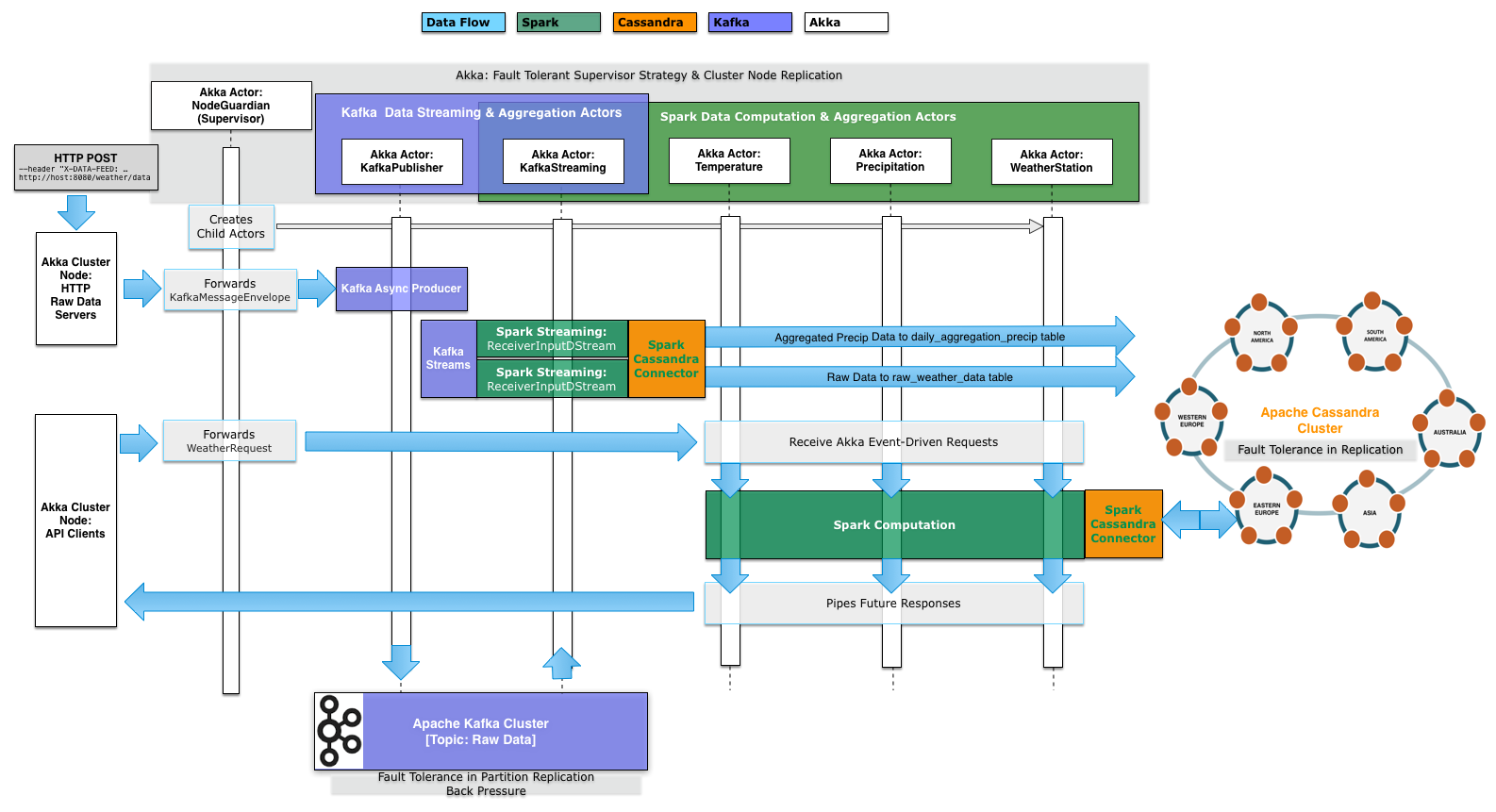
On Tuesday, January 13 I gave a webinar on Apache Spark™, Spark Streaming and Apache Cassandra™. Over 1700 registrants from around the world signed up. This is a follow-up post to that webinar, answering everyone’s questions. In the talk I introduced Spark, Spark Streaming and Cassandra with Kafka and Akka and discussed why these particular technologies are a great fit for lambda architecture due to some key features and strategies they all have in common, and their elegant integration together. We walked through an introduction to implementing each, then showed how to integrate them into one clean streaming data platform for real-time delivery of meaning at high velocity. All this in a highly distributed, asynchronous, parallel, fault-tolerant system.
Video | Slides | Code | Diagram
Q: If I have basic query with a where condition to query Hadoop data, would Hive or Spark work faster when using BYOH?
Spark works faster compared to Hive. We don't support Spark with BYOH. Although I can't imagine many cases where Hive would be faster. Depending on how “Hadoop Data” is actually stored the answer may be different though.
Q: If I have HDFS with 100 TB data, how would you size memory requirements for Spark cluster to query HDFS?
It depends on what you mean by "query". If just filtering, then memory needed would be very low. If you want to do some joins, then you need enough memory for a single partition of the smaller join-side to fit in memory.
Q: What is the status of Spark R?
Alpha. Find out more.
Q: Does the solution have a user friend UI? The API would not work for a standard User, and would require technical knowledge/training. Is there an interface with click and drag?
No this is not for a UI, users would be other cloud distributed applications or processes, it would have a Scala and Akka-based REST interface. As time allows we will add one.
Q: Is it possible to implement moving / sliding windows with spark streaming?
Sliding windows are built into Spark Streaming, which I covered during the Spark Streaming portion of the webinar, but only briefly. Here are some resources to find out more:
- Scroll down to the Window Operations section for an introduction
- Examples
Q: Can we use Spark Streaming from HDFS?
Yes, there are several operations for streaming from and to any HDFS-compatible sources and sinks:
- From the webinar: n the stream, read from any HDFS-compatible file, do your spark computation, and output to Hadoop SequenceFile(s)
- Spark Streaming File Streams are for reading data from files on any file system compatible with the HDFS API (HDFS, S3, NFS, etc.):
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
Q: Elasticity of scale is only valid if VNodes is switched on?
Scaling Cassandra is easiest with VNodes enabled but VNodes are not required. With VNodes enabled it’s easy to add single nodes without major movements in data within the cluster to rebalance the ring. Without VNodes enabled it’s recommend that you add nodes to split existing ranges so there is a minimal amount of movement during rebalancing.
Q: Is this solution good at real time data calculation?
The in-memory capabilities of Spark make it excellent for interactive analysis of data and a good solution for near real-time analysis.
Q: Which Datastax version is the Spark Cassandra Connector available? Is it available publicly yet?
The connector is present in DSE 4.5 and greater. It is publicly available with 4.6 being the most recent Datastax Enterprise Release.
Q: How does Cassandra do splits if VNodes are on? Won't a split cross many Cassandra nodes?
With VNodes on, a single spark partition will still only query data that resides on a single Cassandra node. It will do this by issuing multiple queries for targeting the various ranges available on the Cassandra node.
Q: What are some common deployment patterns for Kafka -> Spark -> Cassandra?
For Spark and Cassandra, co-located nodes are advised, with Kafka deployed to separate nodes. If you are using Cassandra you likely are deploying across DataCenters, in which case the recommended pattern is to deploy a local Kafka cluster in each DataCenter with application instances in each datacenter interacting only with their local cluster and mirroring between clusters.
Q: I understand that Kafka is geared towards minimizing producer blocking as much as possible, but how does it manage keeping consumers from being overwhelmed? Does it implement producer flow control, slow consumer handling, etc?
Unlike how log aggregation and messaging systems push data to their consumers, in Kafka, consumers are responsible for fetching data from Brokers themselves. Along with pulling the data from Brokers, Consumers are also responsible for their own state of where in the stream they are reading from. In other systems that state is managed by the Broker. Consumers not only benefit from these architecture design principal differences but so do the Brokers. Replication is handled this way too as Replica Brokers are just Consumers of the partition they are following. With Kafka messages are Consumed at a rate that approaches the limit of the network connection. You can read more about other efficiencies that have been put into Kafka here http://kafka.apache.org/documentation.html#maximizingefficiency
Q: How does Spark differ from Logstash and Kibana?
Kibana is a UI (Elastic Search), it does not do data computation. Logstash is a tool for aggregating and processing text logs. These two are incredibly different and siloed compared to Spark.
Apache Spark is an incredibly fast cluster computing framework for large-scale data processing. It offers functionality from its core API, as well as its other APIs for streaming, machine learning (+in the stream), graph computations, SQL, and soon R integration.
Q: Does Spark support interacting with JDBC datasources?
Apache Spark has a JDBC-compliant driver via JdbcRDD.
Q: How well does Cassandra handle transactions?
Cassandra uses PAXOS to implement a quorum based “lightweight” transactional system. This provides for Compare and Set queries which are helpful for stateful data. These queries are much more expensive than inserts and reads and should be used sparingly in a Cassandra application.
Q: Can we use any column in a WHERE clause in SparkSQL? I tried to use other than partition key column getting exception?
Yes. There was a bug (now fixed) in some previous versions of the Spark Cassandra Connector which prevented some queries from being properly being executed, now all columns are supported in SparkSQL.
Q: How can we overcome flushwriter blocking issues using this methodology?
I'm not sure which flushwriter you mean specifically, but they all block for the same reason. With Cassandra, the flush writer can block if Cassandra is overwhelmed by writes, so we need to throttle writes before the Memtables get full in order to avoid a timeout. We have a ticket you can vote on open to implement a better solution. In the meantime: reduce the cores (parallelism), don't use batch size in rows = 1.
Q: It would be great to go a bit deeper regarding stateful streaming application in the future (checkpointing, recreate streaming context from checkpoint…). Stateful realtime data processing is quite a common use case.
That is a great suggestion. I can put that on the road map for a new KillrWeather use case to implement and document.
Further Information and Resources:
More Company
View All

The Top 5 DataStax Stories from 2023


{kind=link}
{kind=link}