Performance doubling with message coalescing

Ariel Weisberg

Why not Nagle?
One of the first things most performance-sensitive applications that use TCP do is disable Nagle's algorithm on every socket. Nagle's algorithm was originally intended as a workaround for misbehaving applications that would write many small messages to a socket at once, such as a Telnet session where every key press would be immediately written to a socket. Nagle's algorithm works by coalescing multiple socket writes into a smaller number of packets by only emitting a packet once enough data has been written or by waiting for an acknowledgement for packets that have already been sent.
Unfortunately, Nagle's algorithm can result in large messages being fragmented, with the end of the message not emitted as a packet promptly. Additionally, some patterns of reads and writes can result in additional delays based on fixed timers instead of network conditions. This makes disabling Nagle a requirement for some applications in order to get predictable message latency with fewer outliers.
Why coalesce?
While Nagle's algorithm's purpose is to compensate for misbehaving applications, it happens to coalesce multiple network messages into a single packet as part of its implementation. Coalescing multiples messages turns out to significantly boost message processing throughput (think doubling or more). Disabling Nagle's algorithm to get consistent performance also means that the coalescing is no longer performed, which may or may not matter depending on the workload and how much messaging throughput you need to saturate your application with load.
On bare metal, the floor for packet processing throughput is high enough that many applications won't notice, but in virtualized environments, the point at which an application can be bound by network packet processing can be surprisingly low compared to the throughput of task processing that is possible inside a VM. It's not that bare metal doesn't benefit from coalescing messages, it's that the number of packets a bare metal network interface can process is sufficient for many applications such that no load starvation is experienced even without coalescing.
There are other benefits to coalescing network messages that are harder to isolate with a simple metric like messages per second. By coalescing multiple tasks together, a network thread can process multiple messages for the cost of one trip to read from a socket, and all the task submission work can be done at the same time reducing context switching and increasing cache friendliness of network message processing.
Coalescing messages in Cassandra
The good news is that you can get the benefits of coalescing network messages without using Nagle's algorithm by coalescing at the application level, and it appears to work quite well, even beating Nagle's algorithm in performance in some cases.
Coalescing network messages for responses to clients was introduced in 2.1 as part of CASSANDRA-5663. Coalescing network message between Cassandra nodes has been introduced as part of CASSANDRA-8692 in 2.1 as a disabled by default option, and as an enabled by default in 2.2 Coalescing messages going from the client to the server was introduced into the Datastax Java driver as part of JAVA-562.
You can see how coalescing messages going back to clients is implemented in org.apache.cassandra.transport.Message.Dispatcher. It coalesces messages back to the client that arrive within 10 microseconds of the first message to arrive at the connection, and wakes up 5 times 10 microseconds apart to check for new messages to send to the client. The Java driver implementation is almost identical.
You can see how coalescing messages intra-cluster is implemented by looking at org.apache.cassandra.util.CoalescingStrategies. A coalescing strategy is provided with a blocking queue of pending messages and an output collection for messages to send. The strategy is expected to either spin or block on the queue in order to produce multiple messages into the output collection based on its configuration and analysis of traffic history. Strategies are instantiated per connection so they can detect differences in load across connections and avoid unhelpful coalescing overhead on connections with insufficient load to benefit from coalescing.
You can configure coalescing from cassandra.yaml using the "otc_coalescing_strategy" and "otc_coalescing_window_us." otc_coalescing_strategy can be the name of the class, or it can be one of DISABLED, FIXED, MOVINGAVERAGE, and TIMEHORIZON. The default coalescing strategy in 2.2 is TIMEHORIZON.
otc_coalescing_window_us is a hint to the strategy specifying the maximum amount of time the strategy should wait for additional messages. In practice, the strategy may end up waiting more than the requested amount of time because it does not attempt to account for the difference between requested thread sleep time and observed thread sleep time. The default value for otc_coalescing_window_us is 200 microseconds.
Coalescing strategies
Time horizon
The default strategy in 2.2. Time horizon tracks the number of messages sent in the last sixteen 64 millisecond periods. The moving average is calculated by dividing the length of 15 periods divided by the count of messages sent in the last 15 periods. This yields an average gap between messages. Messages are coalesced by doubling the amount of time waited, up to otc_coalescing_window_us if that would potentially double the number of messages coalesced based on the average gap.
Moving average
A relatively simple coalescing strategy that maintains a moving average of the last 16 gaps between messages. Once the average gap has been calculated, the same doubling strategy that is used in Time Horizon is employed.
Disabled
Unsurprisingly this strategy makes no attempt to wait for additional messages. We did fix a bug where coalescing was essentially impossible even if messages arrived at the same time and the pending message queue had multiple pending messages. This fix was applied to 2.1 as well as 2.2.
Fixed
This strategy always waits the fixed number of microseconds specified by otc_coalescing_window_us. Mostly useful for testing and experimentation. This strategy doesn't adapt to variable load across different connections.
Some other useful properties
If you are interested in learning more about how coalescing is working in practice, you can set the property "cassandra.coalescing_debug" and "cassandra.coalescing_debug_path." This will result in additional log output describing what the calculated average gap is as well as a binary log file of message times allowing post-hoc analysis of message timing. This option is not viable for production usage because the binary logging only works for a limited time, due to the use of a fixed size memory mapped file segment.
Additional changes and concerns
Another change that pairs well with message coalescing is CASSANDRA-8789, which changes how messages are routed between nodes. Cassandra maintains 4 sockets between every node: 2 sockets to send messages and 2 sockets to receive them. Sockets are not used bi-directionally outside of some connection setup intra-cluster. Originally, messages were somewhat arbitrarily mapped to different sockets in ways that could result in high priority messages being mixed with large congested message flows on the same socket. 8789 was not backported to 2.1 so you will want to re-evaluate the impact of coalescing when you move from 2.1 to > 2.1.
After 8789, messages are routed by size with messages larger than 64k placed on their own socket. The advantage of this change is that small messages always end up on the same socket. In practice, this doubles the number of messages that can be coalesced.
Another concern with coalescing is that it may not be possible in cluster configurations where nodes aren't communicating with each other frequently enough. A 100 node cluster with vnodes (even a small number of vnodes) will require every node to communicate with every other node on a regular basis. A 100 node cluster without vnodes will only require every node to communicate with a set of nodes that is a function of replication factor (a much lower number) rather than a factor of # of vnodes * replication factor on a regular basis. I am assuming that smart clients are routing requests to the correct node in this estimation. Without smart clients it's always every node talking to every other node.
If coalescing would not provide a benefit, then the default time horizon strategy will have no problem detecting that and staying out of the way, so there is nothing you need to do if you are using a configuration where coalescing would not help.
Hardware concerns
The impetus for implementing coalescing at the application level comes from utilization issues we discovered in some virtualized environments. Specifically, in EC2 we found that Elastic Network Interfaces (ENIs) only present a single interrupt vector to guest instances even with enhanced networking. A single ENI doesn't have enough discrete packet processing capacity to keep up with Cassandra even with enhanced networking. GCE doesn't seem to have the same issue although it still benefits from coalescing to the same degree that enabling Nagle's algorithm helps (however, coalescing doesn't have Nagle's downsides).
Cassandra supports a separate network interface for clients and servers so you may be able to gain extra capacity by using separate ENIs, but I have not tested this yet.
There are a few Linux configuration options you can use to try and stretch out the capacity of a single ENI.
isolcpus boot option
If you prevent all other threads from running on the first two cores (hyperthreading), you can guarantee a little more capacity will be provided to interrupt handlers. isolcpus does a "good" job of keeping things off the isolated cores and sidesteps issues like taskset silently having no impact on NUMA systems with no notes about that in the man page.
/sys/devices/system/clocksource/clocksource0/current_clocksource
Set to tsc instead of xen. Everything everywhere is grabbing the current time frequently, so going out to the hypervisor to get it is not great. You can run with perf top to see how much time is spent going to the hypervisor to get the current time.
Receive Packet Steering, Receive Flow Steering
RPS and RFS try to reduce the amount of work done on a single not parallelizable network interrupt vector. RPS pushes packet processing away from the core that is handling the interrupt vector to other cores, and RFS attempts to one up RPS by mapping message flows to specific cores to enable cache affinity.
RPS and RFS are very much a your-mileage-may-vary sort of thing. Try one and then both and let your benchmarks do the talking.
Performance impact
You can read about the various benchmarks and measurements I did in the comments of CASSANDRA-8692 and CASSANDRA-8457. I will summarize some of it here, but the impact of coalescing is so configuration and workload dependent that you should do your own measurements.
In this comment I noted the impact of enabling/disabling Nagle's algorithm when testing EC2. I also tested with a fixed window for coalescing to see how coalescing at the application level compares to Nagle's algorithm.
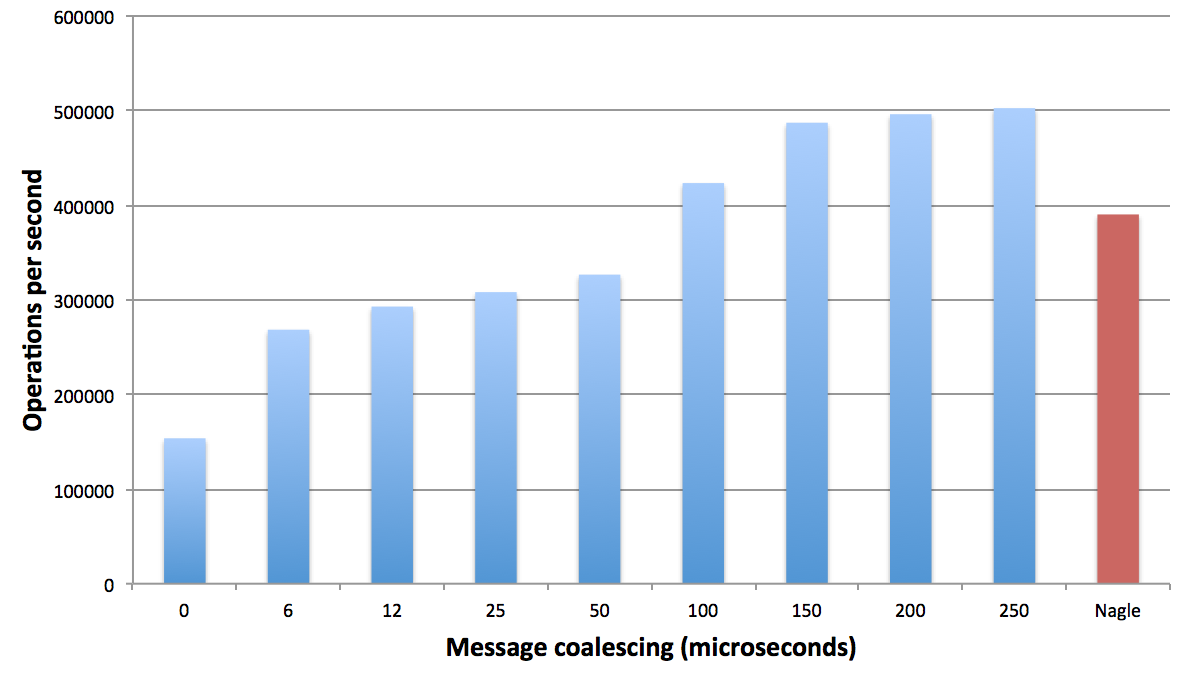
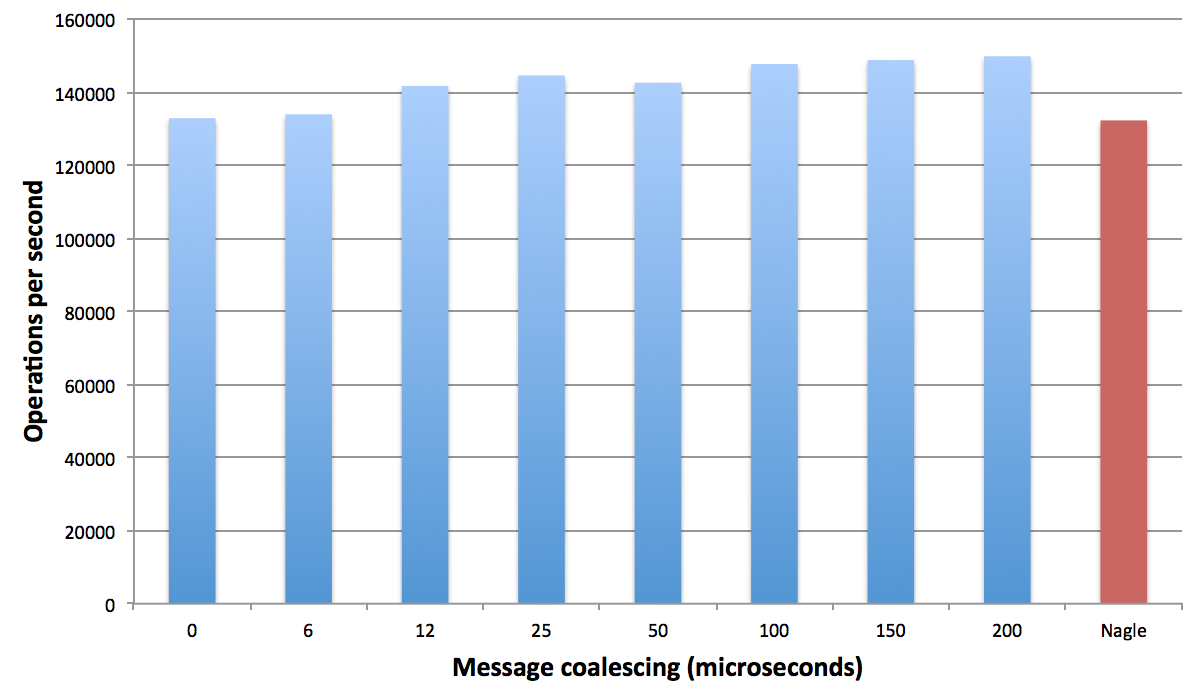
I ran a similar test in GCE and found similar but less extreme results for enabling/disabling Nagle's algorithm. Testing with a fixed coalescing window I saw results that were not as dramatic as the EC2 results, but still better than turning TCP no delay off.
Comparing EC2 and GCE
Comparing the results directly is definitely an apples to oranges exercise especially when it comes to throughput. So don't do it unless you are also going account for the price disparity between the two configurations. But there are some important things to glean. To start you have to compare the instance sizes under test.
In EC2 I used c3.8xlarge instances in a placement group without enhanced networking. We have done other tests with enhanced networking, and having found that it doesn't fully address the issues around have a single ENI, there are still benefits from coalescing.
In GCE I used n1-standard-16 instances which only have 16 threads and it's not clear if that is 8 cores with 16 threads, 16 cores with multi-tenant hyperthreads, or some other configuration.
Right off the bat the c3.8xlarge is a much bigger chunk of compute that will need to perform more messaging and scheduling to reach saturation and peak throughput. Compounding this is the fact that GCE doesn't route all interrupts to a single vector, but instead provides an interrupt vector per core for network interfaces which is a configuration that is expected to behave better with respect to packet processing throughput.
In light of the difference in interrupt handling and instance size, it's not surprising that coalescing doesn't have as big of an impact in GCE as it does in EC2.
Wrapping up
Delaying tasks in order to do more of them is counter intuitive, but we aren't the only ones to discover that manipulating how tasks and network messages are distributed can have an impact on performance. Mikael Ronstrom blogged about a new configuration parameter called MaxSendDelay (similar to otc_coalescing_window_us) in MySQL Cluster which yielded improvements on Infiniband.
There is still room to improve Cassandra's approach to coalescing network messages. The coalescing implementation for client connections might benefit from being adaptive, like the intra-cluster implementation. CASSANDRA-9030 covers automatically detecting the best value for otc_coalescing_window_us. Coalescing strategies don't track how many messages or message bytes have arrived and try to flush early once a sufficient amount of data has been accumulated (which isn't necessarily a good idea). It's quite possible that much smaller coalescing windows would suffice if the decision to flush messages were made using more information, but tracking that information could also introduce additional overhead.
If you are upgrading to 2.1.5 or 2.2 you should consider whether coalescing is something you can use to get better performance either by enabling it or changing otc_coalescing_window_us to suit your workload and configuration.
Why not Nagle?
Why coalesce?
Coalescing messages in Cassandra
Coalescing strategies
Time horizon
Moving average
Disabled
Fixed
Some other useful properties
Additional changes and concerns
Hardware concerns
isolcpus boot option
/sys/devices/system/clocksource/clocksource0/current_clocksource
Receive Packet Steering, Receive Flow Steering
Performance impact
Comparing EC2 and GCE
Wrapping up
More Technology
View All
How to Build a Crystal Image Search App with Vector Search

Knowledge Graphs for RAG without a GraphDB

