QA starter’s guide to Cassandra

Cathy Daw

Since the beginning of 2013, we've done a lot of hiring for the Test Engineering organization here at DataStax. During the on-boarding process, I've found myself giving the following primer to our new hires, so I thought I would share the same with you. For many this will be extremely basic, but for newbies my hope is that you will be able to conceptualize and see tangible behavior behind concepts explained in C* documentation. For me, I feel the best way to figure out answers to my C* questions is to run small isolated tests and see how the system reacts.
This was tested on my MacbookPro using the DataStax Community 1.2.6 tarball distribution.
Tips:
- You can follow along as you read this and replicate the same behavior.
- Tail the /var/log/cassandra/system.log and pay attention to what happens when you execute each step of this tutorial.
- Use this as a guide for how to get the most out of C* documentation.
Step 1: Create some data
Reference: CQL3 music playlist example
CREATE KEYSPACE test1 WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
USE test1;
CREATE TABLE playlists (
id uuid,
song_order int,
song_id uuid,
title text,
album text,
artist text,
PRIMARY KEY (id, song_order) );
INSERT INTO playlists (id, song_order, song_id, title, artist, album)
VALUES (62c36092-82a1-3a00-93d1-46196ee77204, 1, a3e64f8f-bd44-4f28-b8d9-6938726e34d4, 'La Grange', 'ZZ Top', 'Tres Hombres');
SELECT id, song_order, album, artist, title FROM playlists;
id | song_order | album | artist | title
----------------------------+------------+--------------+----------+-----------
62c36092-....-46196ee77204 | 1 | Tres Hombres | ZZ Top | La Grange
Step 2: Look at the data directories for test1.playlists
Reference: Cassandra Writes
$ ls /var/lib/cassandra commitlog data saved_caches $ ls /var/lib/cassandra/data/test1 playlists $ ls /var/lib/cassandra/data/test1/playlists ... No files, why? ...
Step 3: Flush the data and look at data again
Reference: nodetool documentation
$ bin/nodetool flush test1 $ ls /var/lib/cassandra/data/test1/playlists test1-playlists-ic-1-CompressionInfo.db test1-playlists-ic-1-Filter.db test1-playlists-ic-1-Statistics.db test1-playlists-ic-1-TOC.txt test1-playlists-ic-1-Data.db test1-playlists-ic-1-Index.db test1-playlists-ic-1-Summary.db
Step 4: Use sstable2json to look at the sstable generated
Reference: How Cassandra Stores Data
Reference: sstable2json documentation
$ bin/sstable2json /var/lib/cassandra/data/test1/playlists/test1-playlists-ic-1-Data.db
[
{"key": "62c3609282a13a0093d146196ee77204","columns": [["1:","",1373439361510000],
["1:album","Tres Hombres",1373439361510000],
["1:artist","ZZ Top",1373439361510000],
["1:song_id","a3e64f8f-bd44-4f28-b8d9-6938726e34d4",1373439361510000],
["1:title","La Grange",1373439361510000]]}
]
Step 5: Delete the artist column from the row you inserted
Reference: Cassandra Deletes
DELETE artist FROM playlists WHERE id = 62c36092-82a1-3a00-93d1-46196ee77204 and song_order = 1; SELECT id, song_order, album, artist, title FROM playlists; id | song_order | album | artist | title ----------------------------+------------+--------------+--------+----------- 62c36092-....-46196ee77204 | 1 | Tres Hombres | null | La Grange
Step 6: Run flush to write sstable
$ bin/nodetool flush test1 $ ls /var/lib/cassandra/data/test1/playlists test1-playlists-ic-1-CompressionInfo.db test1-playlists-ic-1-Data.db test1-playlists-ic-1-Filter.db test1-playlists-ic-1-Index.db test1-playlists-ic-1-Statistics.db test1-playlists-ic-1-Summary.db test1-playlists-ic-1-TOC.txt test1-playlists-ic-2-CompressionInfo.db test1-playlists-ic-2-Data.db test1-playlists-ic-2-Filter.db test1-playlists-ic-2-Index.db test1-playlists-ic-2-Statistics.db test1-playlists-ic-2-Summary.db test1-playlists-ic-2-TOC.txt
Step 7: Use sstable2json to look at the sstables generated
Note: The version -1 file was not touched since sstables are immutable.
$ bin/sstable2json /var/lib/cassandra/data/test1/playlists/test1-playlists-ic-1-Data.db
[
{"key": "62c3609282a13a0093d146196ee77204","columns": [["1:","",1373439361510000],
["1:album","Tres Hombres",1373439361510000],
["1:artist","ZZ Top",1373439361510000],
["1:song_id","a3e64f8f-bd44-4f28-b8d9-6938726e34d4",1373439361510000],
["1:title","La Grange",1373439361510000]]}
]
Note: -2 files were created to reflect the deleted column.
$ bin/sstable2json /var/lib/cassandra/data/test1/playlists/test1-playlists-ic-2-Data.db
[
{"key": "62c3609282a13a0093d146196ee77204","columns": [["1:artist","51dd0bc4",1373440964374000,"d"]]}
]
Step 8: Compact the data and see what happens
Note: File versions 1 and 2 were merged to a version 3 file.
$ bin/nodetool compact test1
$ ls /var/lib/cassandra/data/Keyspace1/Standard1
test1-playlists-ic-3-CompressionInfo.db
test1-playlists-ic-3-Data.db
test1-playlists-ic-3-Filter.db
test1-playlists-ic-3-Index.db
test1-playlists-ic-3-Statistics.db
test1-playlists-ic-3-Summary.db
test1-playlists-ic-3-TOC.txt
$ bin/sstable2json /var/lib/cassandra/data/test1/playlists/test1-playlists-ic-3-Data.db
[
{"key": "62c3609282a13a0093d146196ee77204","columns": [["1:","",1373440786217000],
["1:album","Tres Hombres",1373440786217000],
["1:artist","51dd0bc4",1373440964374000,"d"],
["1:song_id","a3e64f8f-bd44-4f28-b8d9-6938726e34d4",1373440786217000],
["1:title","La Grange",1373440786217000]]}
]
Step 9: Delete the row, flush the data and look at data again
delete from playlists where id = 62c36092-82a1-3a00-93d1-46196ee77204 and song_order = 1; select * from playlists; [no rows returned]
Note: Now there are file versions -3 and -4.
$ bin/nodetool flush test1 $ ls /var/lib/cassandra/data/test1/playlists test1-playlists-ic-3-CompressionInfo.db test1-playlists-ic-3-Data.db test1-playlists-ic-3-Filter.db test1-playlists-ic-3-Index.db test1-playlists-ic-3-Statistics.db test1-playlists-ic-3-Summary.db test1-playlists-ic-3-TOC.txt test1-playlists-ic-4-CompressionInfo.db test1-playlists-ic-4-Data.db test1-playlists-ic-4-Filter.db test1-playlists-ic-4-Index.db test1-playlists-ic-4-Statistics.db test1-playlists-ic-4-Summary.db test1-playlists-ic-4-TOC.txt
Note: Contents of the new file version -4 reflects deleted row.
$ bin/sstable2json /var/lib/cassandra/data/test1/playlists/test1-playlists-ic-4-Data.db
[
{"key": "62c3609282a13a0093d146196ee77204","columns": [["1","1:!",1373441493485000,"t",1373441493]]}
]
Step 10: Compact the data and see what happens
Note: Now we have file version -5 after we compact the sstables.
$ bin/nodetool compact test1 $ ls /var/lib/cassandra/data/test1/playlists test1-playlists-ic-5-CompressionInfo.db test1-playlists-ic-5-Data.db test1-playlists-ic-5-Filter.db test1-playlists-ic-5-Index.db test1-playlists-ic-5-Statistics.db test1-playlists-ic-5-Summary.db test1-playlists-ic-5-TOC.txt
Note: Contents of the new file version -5 look like the -4 file.
$ bin/sstable2json /var/lib/cassandra/data/test1/playlists/test1-playlists-ic-5-Data.db
[
{"key": "62c3609282a13a0093d146196ee77204","columns": [["1","1:!",1373441493485000,"t",1373441493]]}
]
Step 11: Change gc_grace_seconds so that we may remove the tombstone
Reference: Deletes
The purpose of this section is highlight gc_grace_seconds. Newer versions of Cassandra filter out range ghosts so that you won't see tombstone records after delete (a row key with no columns).
One of my favorite blog posts is related to tombstones and data modeling: Cassandra anti-patterns: Queues and queue-like datasets
use test1; cqlsh:test1> alter table playlists with gc_grace_seconds = 1;
Note: After compaction all files are gone because we removed the tombstones.
$ bin/nodetool compact test1 $ ls /var/lib/cassandra/data/test1/playlists ... no files found ....
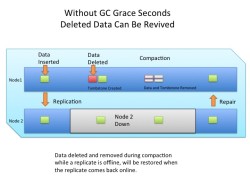
WARNING: Never set gc_grace_seconds this low or else previously deleted data may reappear via repair if a node was down while tombstones are removed.

Step 12: Create an index, flush the data and look at data again
Generate another row of data in cqlsh:
INSERT INTO playlists (id, song_order, song_id, title, artist, album)
VALUES (72c36092-82a1-3a00-93d1-46196ee77204, 1, c7e64f8f-bd44-4f28-b8d9-6938726e34d4,
'Brews', 'Branford Marsalis', 'Four MFs Playing Tunes');
CREATE INDEX ON playlists(artist);
SELECT song_order, album, artist, title
FROM playlists
WHERE artist = 'Branford Marsalis';
song_order | album | artist | title
-------------+------------------------+-------------------+-------
1 | Four MFs Playing Tunes | Branford Marsalis | Brews
Note: There are now *_idx-* in the data directory.
$ ls /var/lib/cassandra/data/test1/playlists test1-playlists-ic-7-CompressionInfo.db test1-playlists-ic-7-Data.db test1-playlists-ic-7-Filter.db test1-playlists-ic-7-Index.db test1-playlists-ic-7-Statistics.db test1-playlists-ic-7-Summary.db test1-playlists-ic-7-TOC.txt test1-playlists.playlists_artist_idx-ic-1-CompressionInfo.db test1-playlists.playlists_artist_idx-ic-1-Data.db test1-playlists.playlists_artist_idx-ic-1-Filter.db test1-playlists.playlists_artist_idx-ic-1-Index.db test1-playlists.playlists_artist_idx-ic-1-Statistics.db test1-playlists.playlists_artist_idx-ic-1-Summary.db test1-playlists.playlists_artist_idx-ic-1-TOC.txt
Look at the secondary index -Data file:
$ bin/sstable2json /var/lib/cassandra/data/test1/playlists/test1-playlists.playlists_artist_idx-ic-1-Data.db
[
{"key": "4272616e666f7264204d617273616c6973","columns": [["72c3609282a13a0093d146196ee77204:1","",1373442382363000]]}
]
Look at the secondary index -Index file:
$ bin/sstable2json /var/lib/cassandra/data/test1/playlists/test1-playlists.playlists_artist_idx-ic-1-Index.db
[
{"key": "4272616e666f7264204d617273616c6973","columns": [["72c3609282a13a0093d146196ee77204:1","",1373442382363000]]}
]
Look at the data file:
$ bin/sstable2json /var/lib/cassandra/data/test1/playlists/test1-playlists-ic-7-Data.db
[
{"key": "72c3609282a13a0093d146196ee77204","columns": [["1:","",1373442382363000],
["1:album","Four MFs Playing Tunes",1373442382363000],
["1:artist","Branford Marsalis",1373442382363000],
["1:song_id","c7e64f8f-bd44-4f28-b8d9-6938726e34d4",1373442382363000],
["1:title","Brews",1373442382363000]]}
]
Step 13: Drop the Keyspace - notice we generate a snapshot and leave the directory in place
Note: if you delete a Keyspace and then recreate the same keyspace and column family, you may notice your data come back. You may want to truncate first if you really want to be squeaky clean.
drop keyspace test1;
Check data directory:
$ ls /var/lib/cassandra/data/test1/playlists snapshots
It's ok to remove the directory and snapshot. Restart server and see for yourself: :)
$ rm -rf /var/lib/cassandra/data/test1/playlists
Step 14: Change memtable_total_space_in_mb to force flushing of memtables
We will use cassandra-stress to illustrate this example since it is very easy to create a large sized column that will flush automatically.
Reference: Cassandra Operations
Change cassandra.yaml:
memtable_total_space_in_mb: 1
WARNING: Never set this value so low, it is only meant for illustration purposes.
Run stress with 1MB column size:
$ tools/bin/cassandra-stress -n 1 -S 1048576 Created keyspaces. Sleeping 1s for propagation. total,interval_op_rate,interval_key_rate,latency/95th/99th,elapsed_time 1,0,0,39.6,39.6,39.6,0 END $ ls /var/lib/cassandra/data/Keyspace1/Standard1 Keyspace1-Standard1-ic-1-Data.db Keyspace1-Standard1-ic-1-Digest.sha1 Keyspace1-Standard1-ic-1-Filter.db Keyspace1-Standard1-ic-1-Index.db Keyspace1-Standard1-ic-1-Statistics.db Keyspace1-Standard1-ic-1-Summary.db Keyspace1-Standard1-ic-1-TOC.txt
Note: This file is huge, so run sstablekeys to get a list of keys in the file instead of sstable2json.
$ bin/sstablekeys /var/lib/cassandra/data/Keyspace1/Standard1/Keyspace1-Standard1-ic-1-Data.db 30
Summary
I hope this was helpful for those new to Cassandra, and provided a small tour of key concepts. This was illustrated using a single row of data, but imagine how dynamic the system becomes under heavy writes that generate many sstables and triggers lots of compaction activity.
Step 1: Create some data
Step 2: Look at the data directories for test1.playlists
Step 3: Flush the data and look at data again
Step 4: Use sstable2json to look at the sstable generated
Step 5: Delete the artist column from the row you inserted
Step 6: Run flush to write sstable
Step 7: Use sstable2json to look at the sstables generated
Step 8: Compact the data and see what happens
Step 9: Delete the row, flush the data and look at data again
Step 10: Compact the data and see what happens
Step 11: Change gc_grace_seconds so that we may remove the tombstone
Step 12: Create an index, flush the data and look at data again
Step 13: Drop the Keyspace - notice we generate a snapshot and leave the directory in place
Step 14: Change memtable_total_space_in_mb to force flushing of memtables
Summary
More Technology
View All
How to Build a Crystal Image Search App with Vector Search

Knowledge Graphs for RAG without a GraphDB

