2012 in review: Performance

Jonathan EllisTechnology

Four years ago, well before starting DataStax, I evaluated the then-current crop of distributed databases and explained why I chose Cassandra. In a lot of ways, Cassandra was the least mature of the options, but I chose to take a long view and wanted to work on a project that got the fundamentals right; things like documentation and distributed tests could come later.
2012 saw that validated in a big way, as the most comprehensive NoSQL benchmark to date was published at the VLDB conference by researchers at the University of Toronto. They concluded,
In terms of scalability, there is a clear winner throughout our experiments. Cassandra achieves the highest throughput for the maximum number of nodes in all experiments with a linear in- creasing throughput from 1 to 12 nodes.
As a sample, here's the throughput results from the mixed reads, writes, and (sequential) scans:
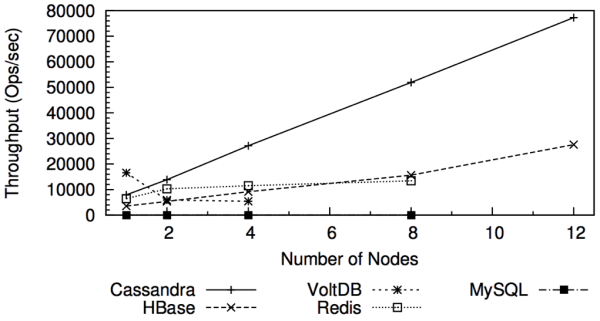
I encourage you to take a few minutes to skim the full results.
There are both architectural and implentation reasons for Cassandra's dominating performance here. Let's get down into the weeds and see what those are.
Architecture
Cassandra incorporates a number of architectural best practices that affect performance. None are unique to Cassandra, but Cassandra is the only NoSQL system that incorporates all of them.
Fully distributed: Every Cassandra machine handles a proportionate share of every activity in the system. There are no special cases like the HDFS namenode or MongoDB mongos that require special treatment or special hardware to avoid becoming a bottleneck. And with every node the same, Cassandra is far simpler to install and operate, which has long-term implications for troubleshooting.
Log-structured storage engine: A log-structured engine that avoids overwrites to turn updates into sequential i/o is essential both on hard disks (HDD) and solid-state disks (SSD). On HDD, because the seek penalty is so high; on SSD, to avoid write amplification and disk failure. This is why you see mongodb performance go through the floor as the dataset size exceeds RAM.
Tight integration with its storage engine: Voldemort and Riak support pluggable storage engines, which both limits them to a lowest-common-denominator of key/value pairs, and limits the optimizations that can be done with the distributed replication engine.
Locally-managed storage: HBase has an integrated, log-structured storage engine, but relies on HDFS for replication instead of managing storage locally. This means HBase is architecturally incapable of supporting Cassandra-style optimizations like putting the commitlog on a separate disk, or mixing SSD and HDD in a single cluster with appropriate data pinned to each.
Implementation
An architecture is only as good as its implementation. For the first years after Cassandra's open-sourcing as an Apache project, every release was a learning experience. 0.3, 0.4, 0.5, 0.6, each attracted a new wave of users that exposed some previously unimportant weakness. Today, we estimate there are over a thousand production deployments of Cassandra, the most for any scalable database. Some are listed here. To paraphrase ESR, "With enough eyes, all performance problems are obvious."
What are some implementation details relevant to performance? Let's have a look at some of the options.
MongoDB
MongoDB can be a great alternative to MySQL, but it's not really appropriate for the scale-out applications targeted by Cassandra. Still, as early members of the NoSQL category, the two do draw comparisons.
One important limitation in MongoDB is database-level locking. That is, only one writer may modify a given database at a time. Support for collection-level (a set of documents, analogous to a relational table) locking is planned. With either database- or collection-level locking, other writers or readers are locked out. Even a small number of writes can produce stalls in read performance.
Cassandra uses advanced concurrent structures to provide row-level isolation without locking. Cassandra even eliminated the need for row-level locks for index updates in the recent 1.2 release.
A more subtle MongoDB limitation is that when adding or updating a field in a document, the entire document must be re-written. If you pre-allocate space for each document, you can avoid the associated fragmentation, but even with pre-allocation updating your document gets slower as it grows.
Cassandra's storage engine only appends updated data, it never has to re-write or re-read existing data. Thus, updates to a Cassandra row or partition stay fast as your dataset grows.
Riak
Riak presents a document-based data model to the end user, but under the hood it maps everything to a key/value storage API. Thus, like MongoDB, updating any field in a document requires rewriting the whole thing.
However, Riak does emphasize the use of log-structured storage engines. Both the default BitCask backend and LevelDB are log-structured. Riak increasingly emphasizes LevelDB since BitCask does not support scan operations (which are required for indexes), but this brings its own set of problems.
LevelDB is a log-structured storage engine with a different approach to compaction than the one introduced by Bigtable. LevelDB trades more compaction i/o for less i/o at read time, which can be a good tradeoff for many workloads, but not all. Cassandra added support for leveldb-style compaction about a year ago.
LevelDB itself is designed to be an embedded database for the likes of Chrome, and clear growing pains are evident when pressed into service as a multi-user backend for Riak. (A LevelDB configuration for Voldemort also exists.) Basho cites "one stall every 2 hours for 10 to 30 seconds", "cases that can still cause [compaction] infinite loops," and no way to create snapshots or backups as of the recently released Riak 1.2.
HBase
HBase's storage engine is the most similar to Cassandra's; both drew on Bigtable's design early on.
But despite a later start, Cassandra's storage engine is far ahead of HBase's today, in large part because building on HDFS instead of locally-managed storage makes everything harder for HBase. Cassandra added online snapshots almost four years ago; HBase still has a long ways to go.
HDFS also makes SSD support problematic for HBase, which is becoming increasingly relevant as SSD price/performance improves. Cassandra has excellent SSD support and even support for mixed SSD and HDD within the same cluster, with data pinned to the medium that makes the most sense for it.
Other differences that may not show up at benchmark time, but you would definitely notice in production:
HBase can't delete data during minor compactions -- you have to rewrite all the data in a region to reclaim disk space. Cassandra has deleted tombstones during minor compactions for over two years.
While you are running that major compaction, HBase gives you no way to throttle it and limit its impact on your application workload. Cassandra introduced this two years ago and continues to improve it. Dealing with local storage also lets Cassandra avoid polluting the page cache with sequential scans from compaction.
Compaction might seem like bookkeeping details, but it does impact the rest of the system. HBase limits you to two or three column families because of compaction and flushing limitations, forcing you to do sub-optimal things to your data model as a workaround.
Cassandra
I honestly think Cassandra is one to two years ahead of the competition, but I'm under no illusions that Cassandra itself is perfect. We have plenty of improvements to make still; from the recently released Cassandra 1.2 to our ticket backlog, there is no shortage of work to do.
Here are some of the areas I'd like to see Cassandra improve this year:
- Latency. Cassandra's SEDA-based architecture means that a request has to hop between multiple threadpools during processing, increasing latency. Fixing this could include lightweight threads like Kilim, a more-efficient executor service, or a new approach entirely.
- A new design for distributed counters.
- Trigger development is underway, but there's a lot to do still before we can ship it. What would a Trigger dialect of CQL look like?
- More low-level optimization like reducing object allocations on reads.
- CAS support
- Making Cassandra more resilient to GC pauses or network hiccups by aggressively doing redundant work to avoid timing out
If working on an industry-leading, open-source database doing cutting edge performance work on the JVM sounds interesting to you, please get in touch.
More Technology
View All
Introducing the DataStax AI Terraform Module


