Advanced Time Series with Cassandra

Tyler Hobbs

Cassandra is an excellent fit for time series data, and it's widely used for storing many types of data that follow the time series pattern: performance metrics, fleet tracking, sensor data, logs, financial data (pricing and ratings histories), user activity, and so on.
A great introduction to this topic is Kelley Reynolds' Basic Time Series with Cassandra. If you haven't read that yet, I highly recommend starting with it. This post builds on that material, covering a few more details, corner cases, and
advanced techniques.
Indexes vs Materialized Views
When working with time series data, one of two strategies is typically employed: either the column values contain row keys pointing to a separate column family which contains the actual data for events, or the complete set of data for each event is stored in the timeline itself. The latter strategy can be implemented by serializing the entire event into a single column value or by using composite column names of the form <timestamp>:<event_field>.
With the first strategy, which is similar to building an index, you first fetch a set of row keys from a timeline and then multiget the matching data rows from a separate column family. This approach is appealing to many at first because it is more normalized; it allows for easy updates of events, doesn't require you to repeat the same data in multiple timelines, and lets you easily add built-in secondary indexes to your main data column family. However, the second step of the data fetching process, the multiget, is fairly expensive and slow. It requires querying many nodes where each node will need to perform many disk seeks to fetch the rows if they aren't well cached. This approach will not scale well with large data sets.


The top column family contains only a timeline index; the bottom, the actual data for the events.
The second strategy, which resembles maintaining a materialized view, provides much more efficient reads. Fetching a time slice of events only requires reading a contiguous portion of a row on one set of replicas. If the same event is tracked in multiple timelines, it's okay to denormalize and store all of the event data in each of those timelines. One of the main principles that Cassandra was built on is that disk space is very cheap resource; minimizing disk seeks at the cost of higher space consumption is a good tradeoff. Unless the data for each event is very large, I always prefer this strategy over the index strategy.

All event data is serialized as JSON in the column values.
Reversed Column Comparators
Since Cassandra 0.8, column comparators can easily be reversed. This means that if you're using timestamps or TimeUUIDs as column names, you can choose to have them sorted in reverse chronological order.
If the majority of your queries ask for the N most recent events in a timeline or N events immediately before a point in time, using a reversed comparator will give you a small performance boost over always setting reversed=True when fetching row slices from the timeline.
Timeline Starting Points
To support queries that ask for all events before a given time, your application usually needs to know when the timeline was first started. Otherwise, if you aren't guarenteed to have events in every bucket, you cannot just fetch buckets further and further back in time until you get back an empty row; there's no way to distinguish between a bucket that just happens to contain no events and one that falls before the timeline even began.
To prevent uneccessary searching through empty rows, we can keep track of when the earliest event was inserted for a given timeline using a metadata row. When an application writes to a timeline for the first time after starting up, it can read the metadata row, find out the current earliest timestamp, and write a new timestamp if it ever inserts an earlier event. To avoid race conditions, add a new column to the metadata row each time a new earliest event is inserted. I suggest using TimeUUIDs with a timestamp matching the event's timestamp for the column name so that the earliest timestamp will always be at the beginning of the metadata row.
After reading only the first column from the metadata row (either on startup or the first time it's required, refreshing periodically), the application can know exactly how far in the past it should look for events in a given timeline.
High Throughput Timelines
Each row in a timeline will be handled by a single set of replicas, so they may become hotspots while the row holding the current time bucket falls in their range. It's not very common, but occasionally a single timeline may grow at such a rate that a single node cannot easily handle it. This may happen if tens of thousands of events are being inserted per second or at a lower rate if the column values are large. Sometimes, by reducing the size of the time bucket enough, a single set of replicas will only have to ingest writes for a short enough period of time that the throughput is sustainable, but this isn't always a feasible option.
In order to spread the write load among more nodes in the cluster, we can split each time bucket into multiple rows. We can use row keys of the form <timeline>:<bucket>:<partition>, where partition is a number between 1 and the number of rows we want to split the bucket across. When writing, clients should append new events to each of the partitions in round robin fashion so that all partitions grow at a similar rate. When reading, clients should fetch slices from all of the partition rows for the time bucket they are interested in and merge the results client-side, similar to the merge step of merge-sort.
If some timelines require splitting while others do not, or if you need to be able to adjust the number of rows a timeline is split across periodically, I suggest storing info about the splits in a metadata row for the timeline in a separate column family (see the notes at the end of this post). The metadata row might have one column for each time the splitting factor is adjusted, something like {<timestamp>: <splitting_factor>}, where timestamp should align with the beginning of a time bucket after which clients should use the new splitting factor. When reading a time slice, clients can know how many partition rows to ask for during a given range of time based on this metadata.

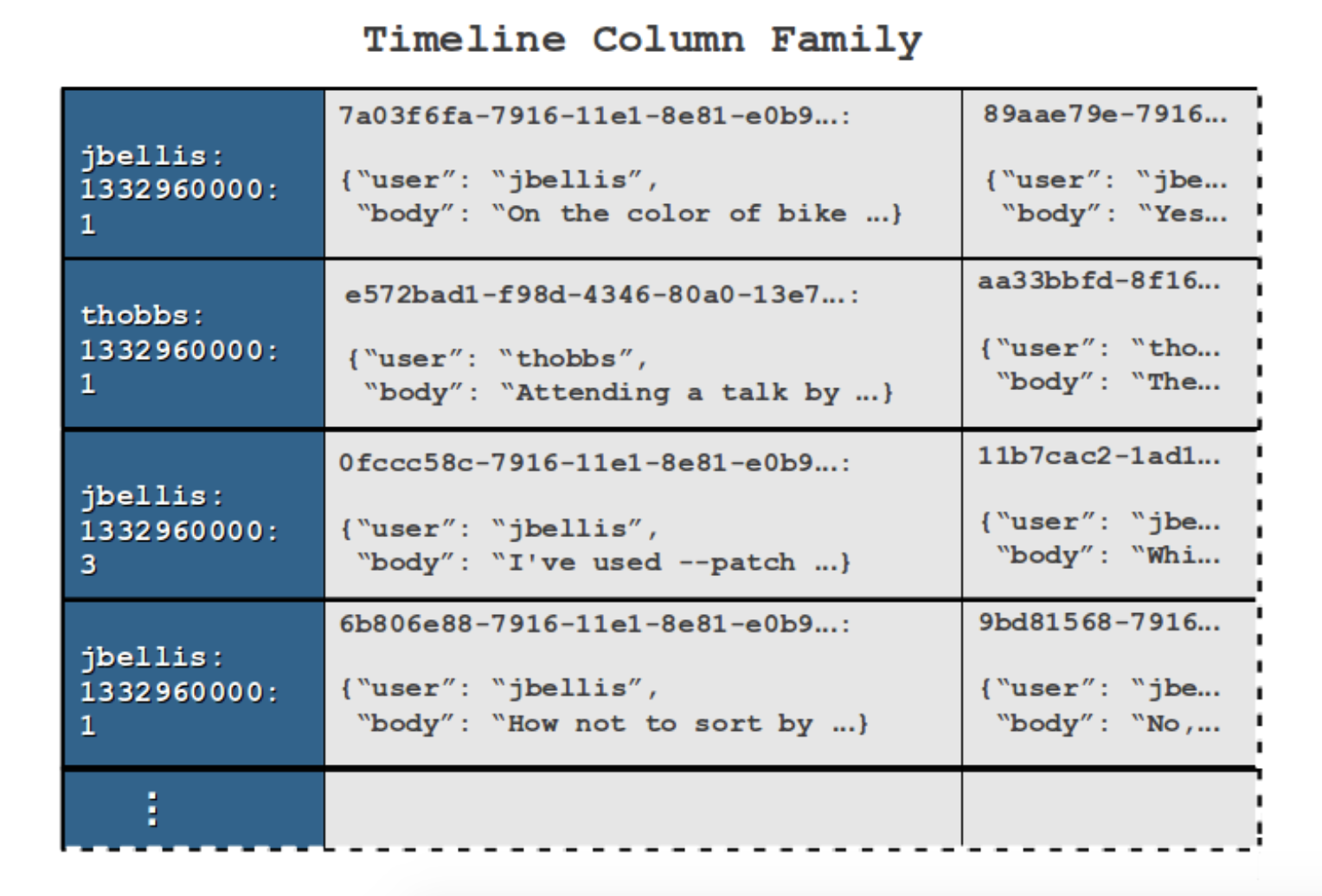
The "jbellis" timeline has increased its splitting factor over time; it currently spans three rows for each time bucket.
Variable Time Bucket Sizes
For some applications, the rate of events for different timelines may differ drastically. If some timelines have an incoming event rate that is 100x or 1000x higher than other timelines, you may want to use a different time bucket size for different timelines to prevent extremely wide rows for the busy timelines or a very sparse set of rows for the slow timelines. In other cases, a single timeline may increase or decrease its rate of events over time; eventually, this timeline may need to change its bucket size to keep rows from growing too wide or too sparse.
Similar to the timeline metadata suggestion for high throughput timelines (above), we can track time bucket sizes and their changes for individual timelines with a metadata row. Use a column of the form {<timestamp>: <bucket_size>}, where timestamp aligns with the start of a time bucket, and bucket_size is the bucket size to use after that point in time, measured in a number of seconds. When reading a time slice of events, calculate the appropriate set of row keys based on the bucket size during that time period.


At time 1332959000, the "jbellis" timeline switched from using 1000 second time buckets to 10 second buckets.
Notes on Timeline Metadata
When using timeline metadata for high throughput timelines or variable bucket size timelines, the metadata rows should typically be stored in a separate column family to allow for cache tuning. I suggest using a fair amount of key cache on the metadata column family if it will be queried frequently.
The timeline metadata should generally be written by a process external to the application to avoid race conditions, unless the application operates in such a fashion that this isn't a concern. The application can read the metadata row on startup or on demand for a particular timeline; if the application is long lived, it should periodically poll the metadata row for updates. If this is done, a new splitting factor or bucket size can safely be set to start with a new time bucket that begins shortly in the future; the application processes should see the updated metadata in advance, before the new bucket begins, allowing them to change their behavior right on time.
Further Data Modeling Advice
If you want to learn more about data modeling, check out: Cassandra Data Modeling.
More Technology
View All
Introducing the DataStax AI Terraform Module


