Building Fast and Scalable Microservices with Apache Cassandra and Pulsar

Jonathan LacefieldProduct

Microservices are everywhere in enterprise digital portfolios these days. They are a software architecture technique comprising standard design patterns that break large, monolithic applications down into smaller, business domain aligned services. This architecture enables large enterprises to compete in today’s fast-paced, disruption based, digital economy. With a microservices architecture, enterprises are able to deliver critical, revenue generating apps and digital experiences to market as fast and innovative as today’s small, lightweight, disruptive startups.
Choosing the right design pattern and messaging service
Arguably, the most common and important design pattern leading to the massive adoption of microservices is the database per service design pattern. This design pattern helps enterprises break-out of traditional development cycle bottlenecks associated with monolithic relational database management systems (RDBMS) by affording each domain service team the opportunity to choose the right data model and database for their domain service.
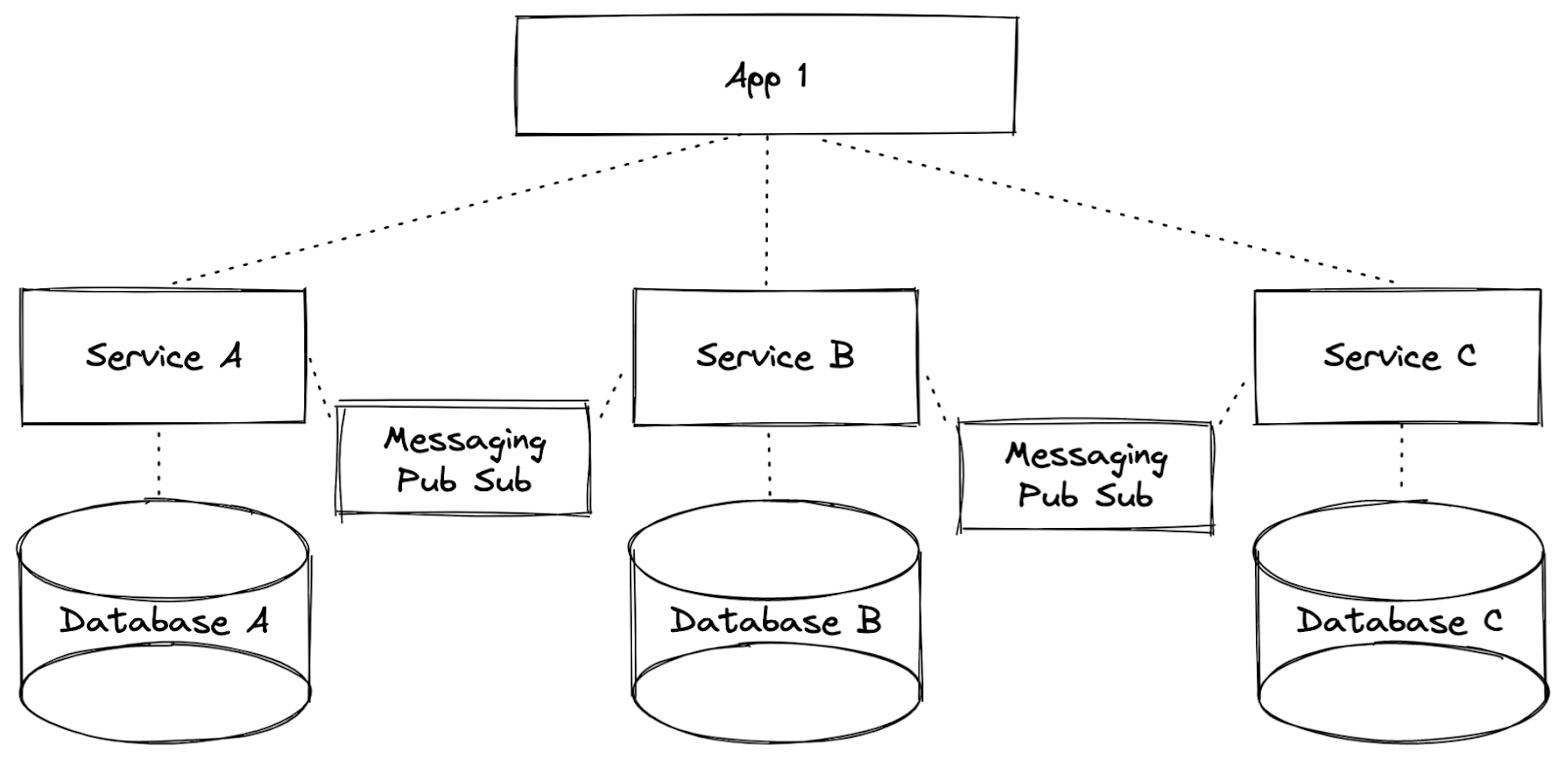
Figure 1. Common view of the database per service pattern.
Microservices-based applications are built upon asynchronous architectures in which communication is handled via network calls. When adding a cloud-native solution for the message-based, cross-service communication components of a microservices architecture, one need look no further than to Apache Pulsar. According to the community-led 2021 Pulsar user’s survey, the second highest use of Apache Pulsar is within asynchronous architectures to support microservices-based applications.
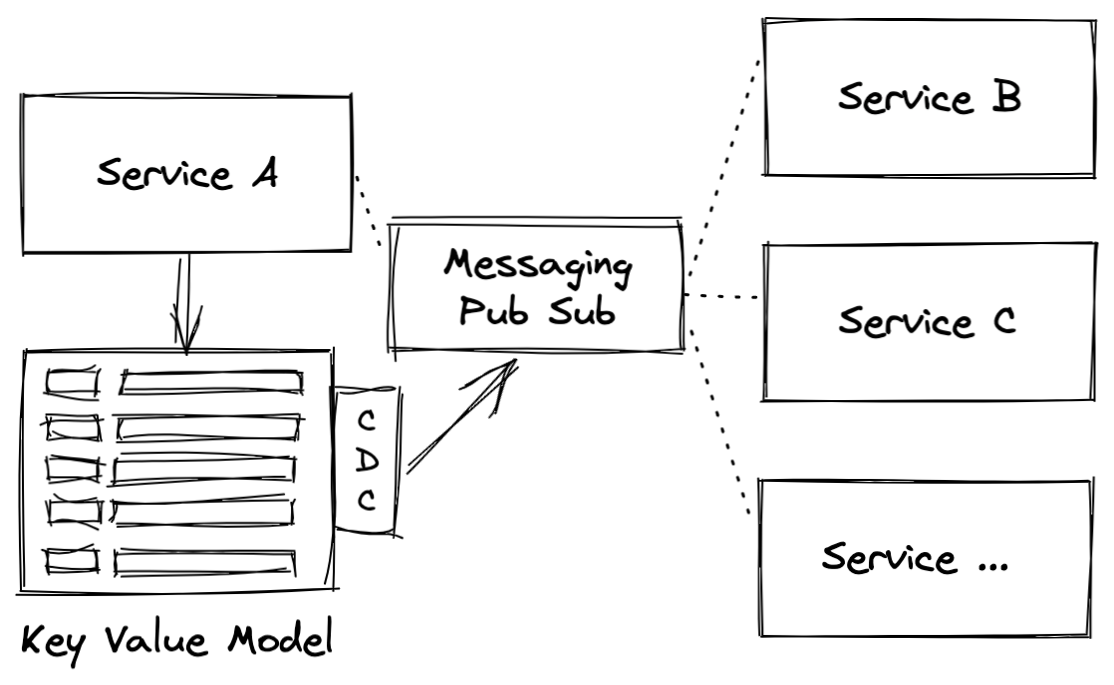
Figure 2. Asynchronous architecture with messaging as communication between services.
The benefits of Microservices are that they make enterprises more agile and competitive. But, they also introduce challenges as application logic becomes spread out across many different services, each with their own database. These benefits and challenges have a lot to do with the coordination of data access, movement and storage throughout microservices architectures which is often referred to as managing microservices data consistency.
All microservices systems start with a database per service design pattern, which is necessary to support the loose coupling of services that characterize these systems. In a microservices system, every service requires its own database accessible only via a REST API. This design pattern ensures that changes to one database do not impact any of the other microservices in the system. Without this pattern, most other microservices principles fall apart.
The database per service pattern also allows every microservice in the system to use the type of database best suited to its needs. Apache Cassandra® is a proven database choice for the database per service design pattern because, with microservices, scale matters. And when scale matters, Cassandra is the logical choice.
A different way to think about the database per service pattern
The database per service pattern is a bit of a misnomer because the database itself is actually less important than the data model when it comes to microservices. Thinking of the database per service pattern as a “data model per service” instead recognizes the importance of selecting the right data model to ensure the scalability such as that which can be achieved with Cassandra.
Stargate is an open source gateway that provides C* with GraphQL support. Using Stargate with Cassandra, access to data models can be made using model specific protocols like REST, GraphQL, and gRPC.
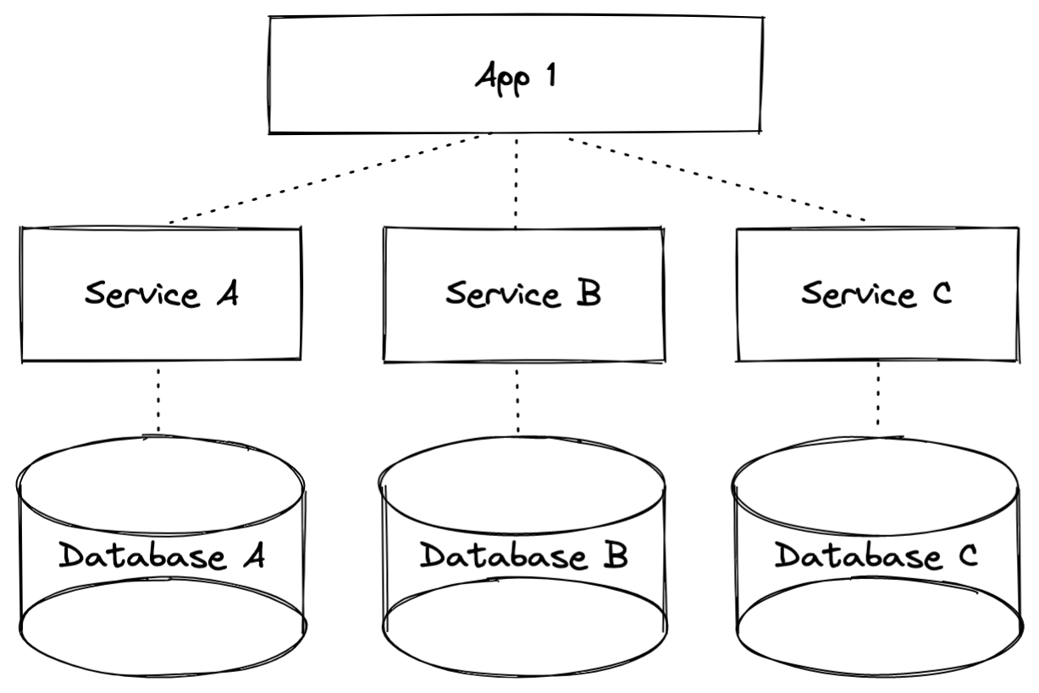
Figure 3. Asynchronous architecture showing a data model per service design
Most microservices implementations use “data model per service” which is what allows them to scale quickly. The intelligence layer in microservices systems is provided by the “data flow” design patterns, which pertain to how data flows into, out of, and across services. For this, microservices teams use messaging or remote procedure calls to implement distributed transaction (data consistency and atomicity) logic and use domain objects or data federation for cross-service data retrieval. Unlike “data model per service”, the choice of “data flow” design patterns is typically made not just for one service but for the full microservices system.
The common distributed transaction design patterns are Saga, Command and Query Responsibility Segregation (CQRS), Domain Event, Event Sourcing, and Transactional Outbox. For cross-service data retrieval, federation is the clear winner thanks to GraphQL. We do see implementations of composition design patterns like Domain Events and Aggregates being used over GraphQL.
Here at DataStax, we combine Pulsar and Cassandra in a single data platform as our data solution for all microservices “data flow” design patterns. This is because Atomicity is key to the design patterns associated with distributed transaction processing. Several different design patterns require atomic guarantees within a single service to ensure data changes are persisted to a database and published to other services as a single operation. This is particularly important for Event Sourcing based design patterns. Other design patterns require more complex atomicity guarantees. Design patterns like Saga, CQRS, as well as higher level transaction management patterns require atomicity across combinations of services, in workflows, as domain level aggregates and/or across domains.
Options for adding atomicity to your microservices architecture
When atomicity is needed within a service, the combination of Pulsar and Cassandra in the same platform provides microservices teams with several great implementation options. The first is DataStax’s recently released change data capture (CDC) solution that combines database-level event publishing through Pulsar topics as a way to ensure that every database mutation is made available for consumption by other services.
The CDC approach (i.e. incremental processing) is a great option because of its simplicity. DataStax has integrated Cassandra and Pulsar to provide a no-code solution that exposes Cassandra mutations to Pulsar topics, automagically. A user simply needs to configure CDC for their table and they will receive a Pulsar stream of change events as they persist.
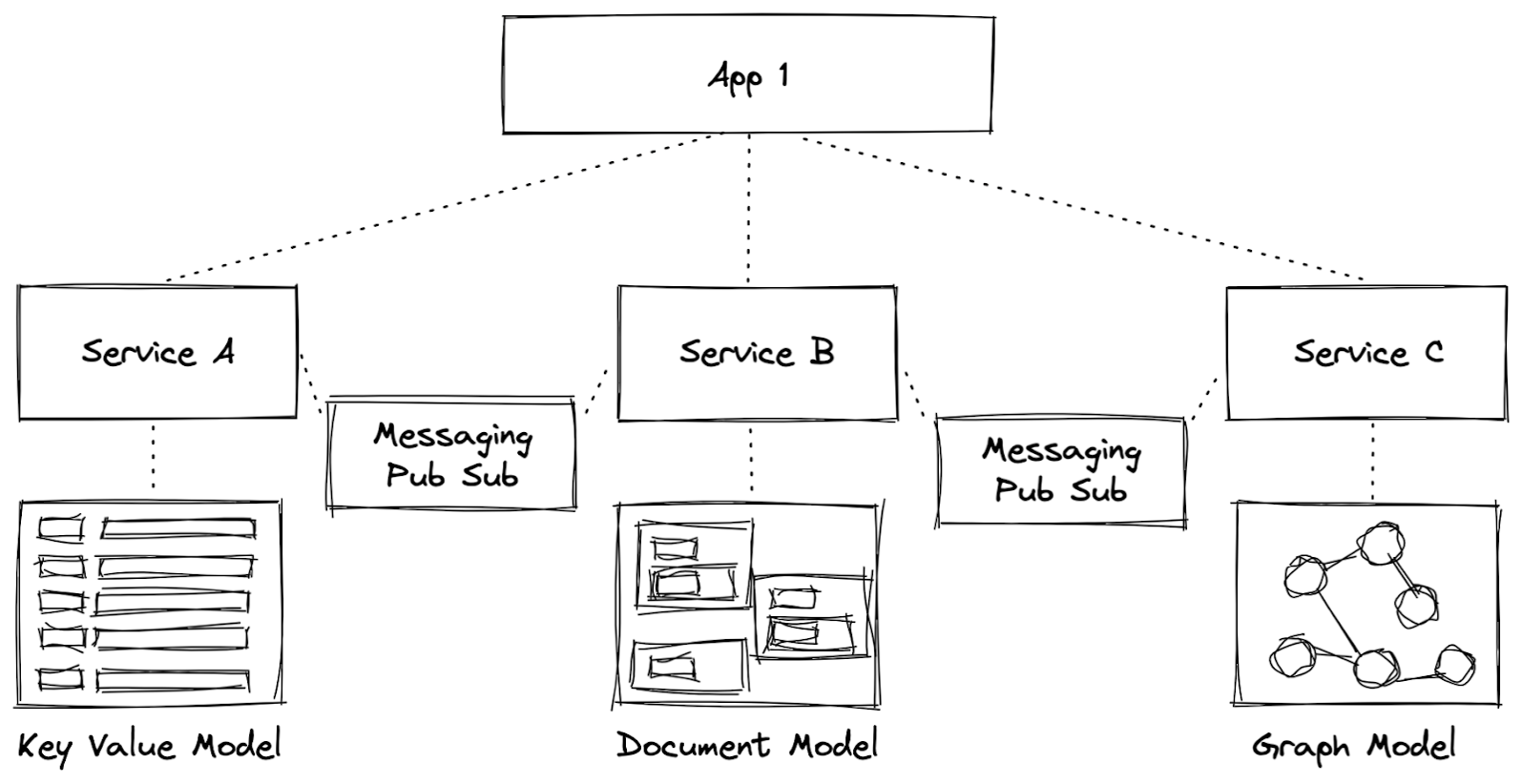
Figure 4. Atomicity within a service (DB + Event Pub) via CDC.
Another option is Pulsar Functions, a serverless based compute framework that’s a part of Apache Pulsar. Pulsar Functions can be used to encapsulate atomic logic wrapping a database mutation with the publishing of a corresponding event as a part of a single “transaction”. In microservices parlance, this is known as a “local transaction” that guarantees atomicity for events that flow into microservices systems. Unlike CDC, Pulsar Functions require microservices developers to code logic to deliver atomicity guarantees. Pulsar Functions are a great option when complex logic is needed to support local transactions.
Figure 5. Atomicity within a service “local transaction” (DB + Event Pub) via Pulsar Functions.
When cross service atomicity is needed, messaging and serverless functions can be used to control the atomic flow of data across services. A great example of this is the Saga design pattern. Sagas provide distributed, cross service atomicity through a coordinated set of “local transactions”. Pulsar Functions are a great choice to implement sagas. They afford microservices developers the ability to create complex logical routines that guarantee a flow of “logical transactions” all succeed or all fail. The same logical techniques can be applied to other “higher order” data flow patterns, like CQRS (where read replicas require atomic guarantees) and transactional outbox.
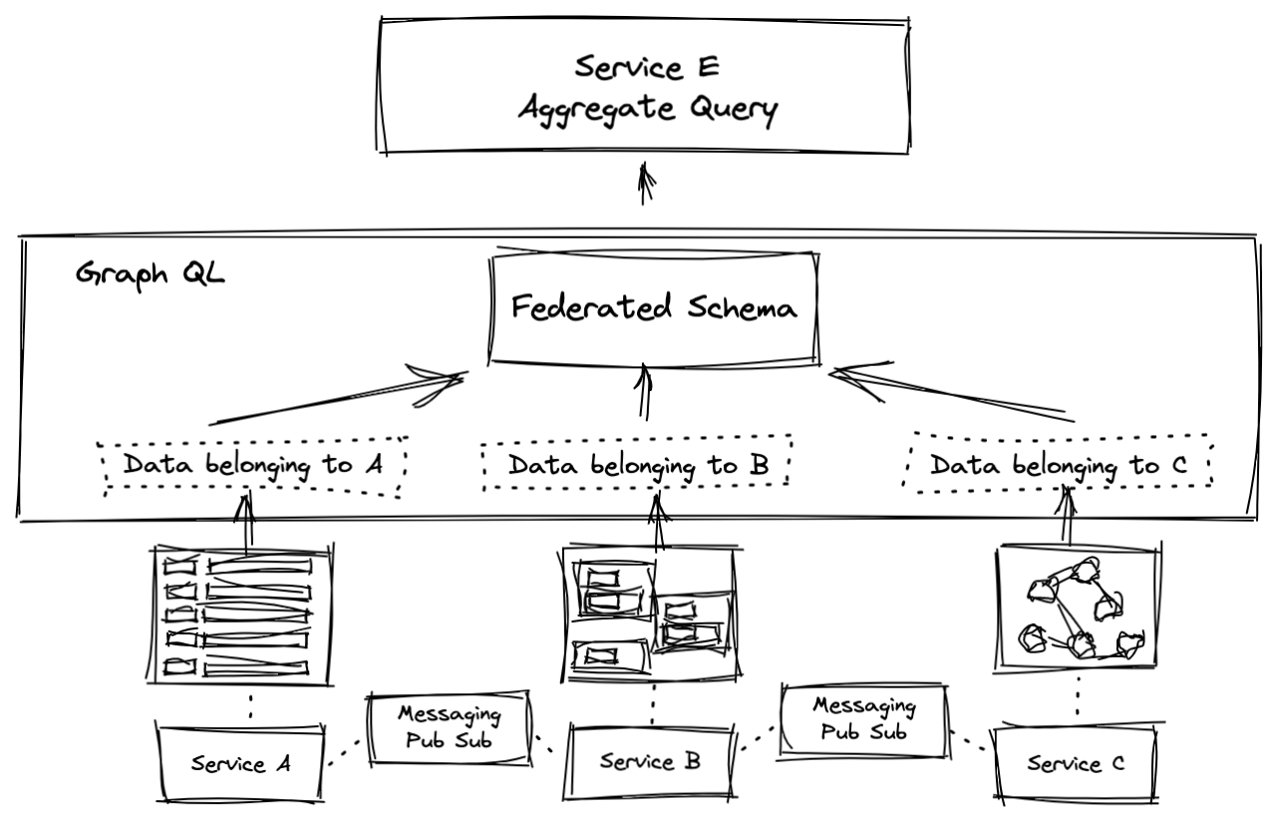 Figure 6. Cross-service atomicity with sagas via Pulsar Functions.
Figure 6. Cross-service atomicity with sagas via Pulsar Functions.
The combination of the messaging and streaming capabilities of Pulsar with the scale and multi-API capabilities of Cassandra is a giant leap forward for microservices teams looking to implement distributed transactions. No longer do teams have to stitch together messaging functionality and database functionality. Nor do they have to support, secure and govern multiple systems just to support data flow within microservices systems.
At DataStax, we see the next step in the evolution of microservices to be consumable, design pattern based-APIs that obfuscate infrastructure and severely shorten development times. Temporal is leading the way in that direction with a microservices workflow platform that exposes a set of pre-built, scalable APIs containing all of the logic associated with the distributed microservices design patterns we’ve discussed here. With these advancements, developers will be free to write code without having to think about the infrastructure needed to achieve scalable services, an exciting future indeed.
Data access isn’t the only thing APIs can provide
Data Federation within microservices systems has been gaining a lot of momentum thanks to the explosive growth of GraphQL. GraphQL simplifies querying within microservices, particularly when domain level and cross domain level aggregates are needed.
Last year, Apollo released Apollo Federation, a purpose-built, open source tool that optimizes the use of GraphQL in microservices architectures. The TL;DR here is that an enterprise can now work with a complete schema that connects all sources of data within distributed architecture where separate teams own their portion of the graph. In other words, Apollo Federation delivers the benefits of an enterprise data model with the benefits of two pizza teams.
To bring the benefits of Apollo Federation to Cassandra and GraphQL users, DataStax has partnered with Apollo to integrate the Apollo Federation tool with the open source Stargate project.
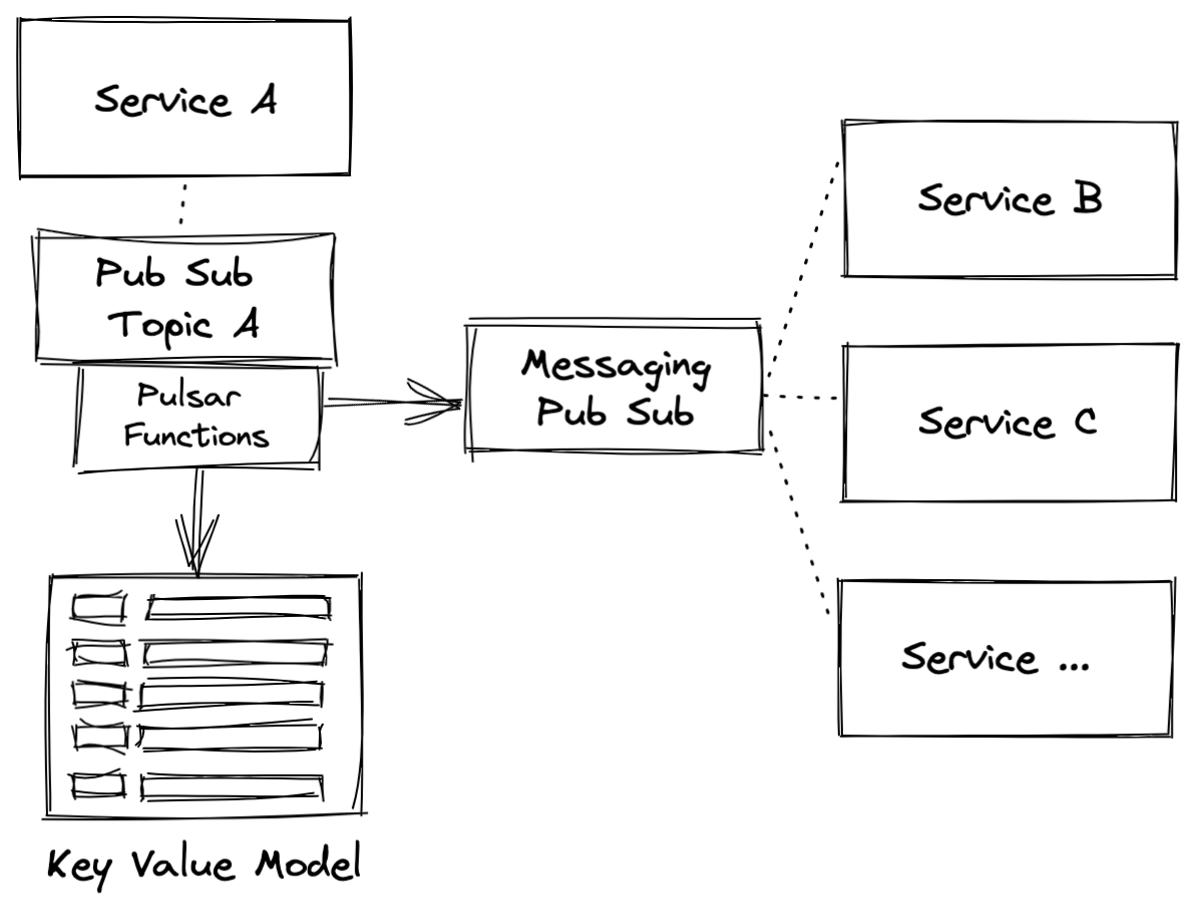
Figure 7. Federated data querying with GraphQL.
A lot has been written about data being the “hardest part” of delivering a microservices architecture. But, it doesn’t have to be this way. Today’s microservices pain points are solvable with a data platform that looks like scalable APIs to developers, that is consistently operable across all services, and that delivers the total cost of ownership, security, and governance benefits of a standardized data platform.
Follow the DataStax Tech Blog for more developer stories. Check out our YouTube channel for free tutorials and DataStax Developers on Twitter for the latest news in our developer community.
Resources
- What are Microservices?
- Microservice Architecture and its 10 Most Important Design Patterns
- Why Apache Pulsar as a Service is Essential to the Modern Data Stack
- The 2021 Apache Pulsar User Report is Here!
- Apache Cassandra
- Stargate
- Introducing the Design for Stargate v2
- Developing with Stargate: REST API
- Developing with Stargate: GraphQL API
- Developing with Stargate: gRPC API
- DataStax
- Atomicity in Database Systems
- Change Data Capture (CDC)
- Pulsar Functions Overview
- A Pattern Language for Microservices
- Pattern: Saga
- Pattern: Command Query Responsibility Segregation (CQRS)
- Pattern: Domain Event
- Pattern: Event Sourcing
- Pattern: Transactional Outbox
- GraphQL
- Temporal
- Easily Manage Workflows at Scale with Temporal.io and Astra DB
- How to Connect Temporal.io to Astra DB in Just 5 Easy Steps
- Introduction to Apollo Federation
- GraphQL Integrity Principles
- Microservices & Two-Pizza Teams: A Story of Autonomy and Ownership
More Technology
View All
Introducing the DataStax AI Terraform Module


