Cassandra File System Design

Jake LucianiEngineering

The Cassandra File System (CFS) is an HDFS compatible filesystem built to replace the traditional Hadoop NameNode, Secondary NameNode and DataNode daemons. It is the foundation of our Hadoop support in DataStax Enterprise.
The main design goals for the Cassandra File System were to first, simplify the operational overhead of Hadoop by removing the single points of failure in the Hadoop NameNode. Second, to offer easy Hadoop integration for Cassandra users (one distributed system is enough).
In order to support massive files in Cassandra we came up with a novel approach that relies heavily on the fundamentals of Cassandra’s architecture, both Dynamo and BigTable.
CFS Data Model
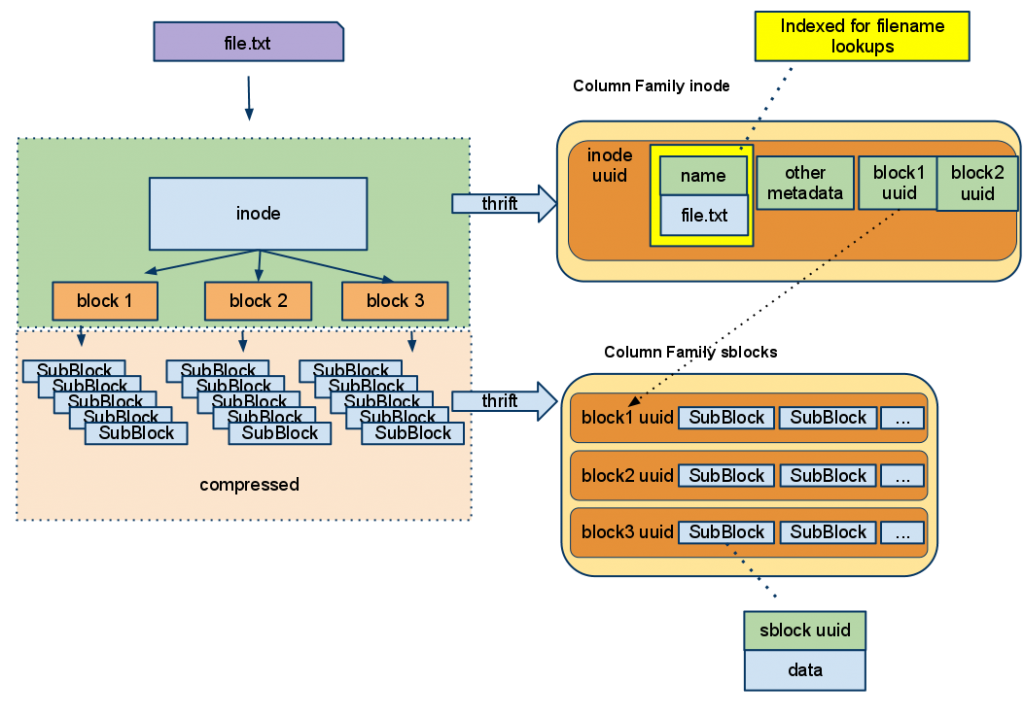
CFS is modeled as a Keyspace with two Column Families in Cassandra. The Keyspace is where replication settings are, so unlike HDFS, you can’t change replication per file. You can, however, accomplish the same with multiple CFS Keyspaces. The two Column Families represent the two primary HDFS services. The HDFS NameNode service, that tracks each files metadata and block locations, is replaced with the “inode” column family. The HDFS DataNode service, that stores file blocks, is replaced with the “sblocks” Column Family. By doing this we have removed three services of the traditional Hadoop stack and replaced them with one fault tolerant scalable component.
The ‘inode’ Column Family contains meta information about a file and uses a DynamicCompositeType comparator. Meta information includes: filename, parent path, user, group, permissions, filetype and a list of block ids that make up the file. For block ids it uses TimeUUID so blocks are ordered sequentially naturally. This makes supporting HDFS append() simple.
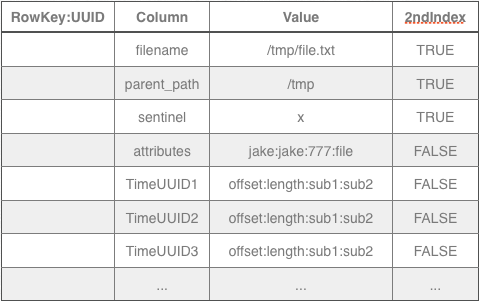
Secondary indexes are used to support operations like “ls” and “rmdir” the corresponding CQL looks something like:
select filename from inode where parent_path=‘/tmp’;
select filename from inode where filename > ‘/tmp’ and filename < ‘/tmq’ and sentinel = ‘x’;
The sentinel is needed because of how cassandra implements secondary indexes. It chooses the predicate with the most selectivity and filters from there.
Since file identifiers are accessed by secondary indexes it can use a UUID as the row key, giving us good distribution of data across the cluster. To summarize, an entire files meta information is stored under one wide row key.
The second column family ‘sblocks’ stores the actual contents of the file.
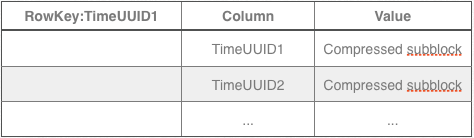
Each row represents a block of data associated with an inode record. The row key is a block TimeUUID from a inode record. The columns are time ordered compressed sub-blocks that, when decompressed and combined, equal one HDFS block. Let’s walk through the read and write paths to make this all more clear.
CFS Write Path
Hadoop has the “dfs.block.size” parameter to tell how big a file block should be per file write. When a file comes in it writes the static attributes to the inode column family.
Then allocates a new block object and reads dfs.block.size worth of data. As that data is read it splits it into sub blocks of size “cfs.local.subblock.size”. those sub-blocks are compressed using google snappy compression. Once a block is finished the block id is written to the inode row and the sub blocks are written to cassandra with the block id as the row key and the sub block ids as the columns. CFS splits a block into sub-blocks since it relies on thrift, which does not support streaming so it must ensure it doesn’t OOM the node by sending 256MB or 512Mb of data at once. To Hadoop though, the block looks like a single block so it doesn’t cause any change in the job split logic of map reduce.
CFS Read Path
When a read comes in for a file or part of a file (let’s assume Hadoop looked up the the uuid from the secondary index) it reads the inode info and finds the block and subblock to read. CFS then executes a custom thrift call that returns either the specified sub-block data or, if the call was made on a node with the data locally, the file and offset information of the Cassandra SSTable file with the subblock. It does this since during a mapreduce task the jobtracker tries to put each computation on the node with the actual data. By using the SSTable information it is much faster, since the mapper can access the data directly without needing to serialize/deserialize via thrift.
One question that comes up is why does CFS compress sub-blocks and not use the ColumnFamily compression in Cassandra 1.0? The reason is by compressing and de-compressing on the client side it cuts down of the network traffic between nodes.
Integrating with Hadoop
Hadoop makes it very simple to hook a custom file system implementation in and everything just works. Only the following change is needed to core-site.xml
<property> <name>fs.cfs.impl</name> <value>com.datastax.bdp.hadoop.cfs.CassandraFileSystem</value> </property>
Now it’s possible to execute the following commands:
hadoop fs -copyFromLocal /tmp/giant_log.gz cfs://cassandrahost/tmp
or even
hadoop fs distcp hdfs:/// cfs:///
More Technology
View All
Introducing the DataStax AI Terraform Module


