Cassandra vs failures, latency edition

Jonathan EllisTechnology

A common misconception is that masterless databases like Cassandra are designed to tolerate network partitions, which are quite possible but relatively uncomon within a single data center compared to other failures.
A more complete understanding is that Cassandra is designed to tolerate any failure without interruption, whether due to node failures, garbage collection pauses, or slow disks, all of which are indistinguishable from partitions to the rest of the system.

Cassandra fault tolerance. Click for details
An even more complete understanding is that designing to accomodate failure also drives latency lower: since there are no masters and any replica can answer requests, Cassandra has no artificial bottleneck that makes latency spike whenever there is a hiccup.
HBase may be the most well-known master-oriented distributed database competing with Cassandra. While HBase developer Enis Soztutar reports that "[i]n the present HBase architecture, it is hard, probably impossible, to satisfy constraints like 99th percentile of the reads will be served under 10 ms," Cassandra easily achieves this in many clusters.
Here's one example, from a production cluster in England (in microseconds):
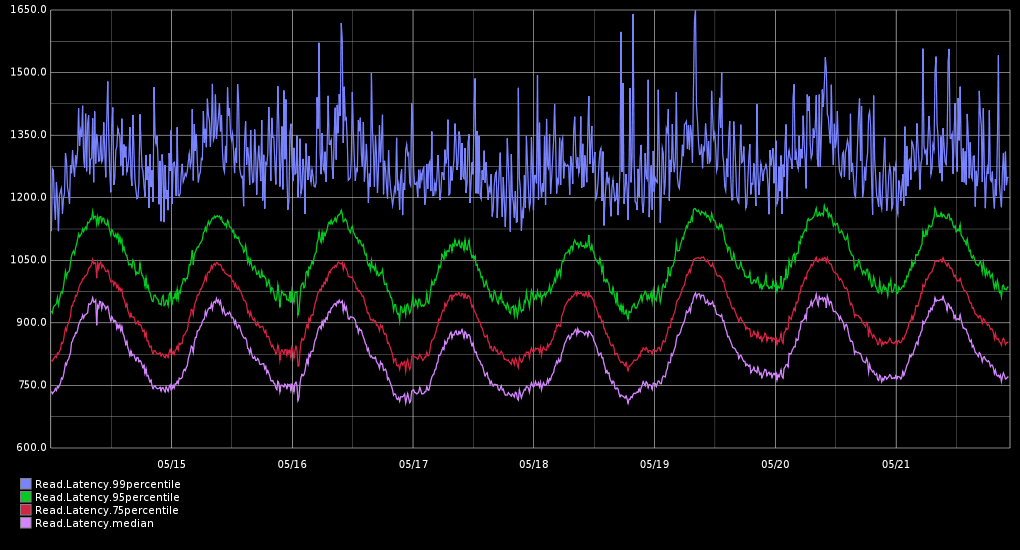
Part of the explanation is that Cassandra is simply faster overall. But more broadly, Cassandra's fault tolerant design is what allows the slowest 1% of requests to be less than twice as slow as the average.
More Technology
View All
Introducing the DataStax AI Terraform Module


