From CFS to DSEFS

Piotr Kołaczkowski

Cassandra File System (CFS) is the default distributed file system in the DataStax Enterprise platform in versions 2.0 to 5.0. Its primary purpose is to support Hadoop and Spark workloads with temporary Hadoop-compatible storage. In DSE 5.1, CFS has been deprecated and replaced with a much improved DataStax Enterprise File System (DSEFS). DSEFS is available as an option in DSE 5.0, and was made the default distributed file system in DSE 5.1.
A Brief History of CFS
CFS stores file data in Apache Cassandra®. This allows for reuse of Cassandra features and offers scalability, high availability and great operational simplicity. Just as Cassandra is shared-nothing, CFS is shared-nothing as well. It scales linearly with the number of nodes in either performance and capacity.
Because Cassandra was not designed to store huge blobs of binary data as single cells, files in CFS have to be split into blocks and subblocks. Subblocks are each 2 MB large by default. A block is stored in a table partition. A subblock is stored in a table cell. The inodes table stores file metadata such as name and attributes and a list of block identifiers.
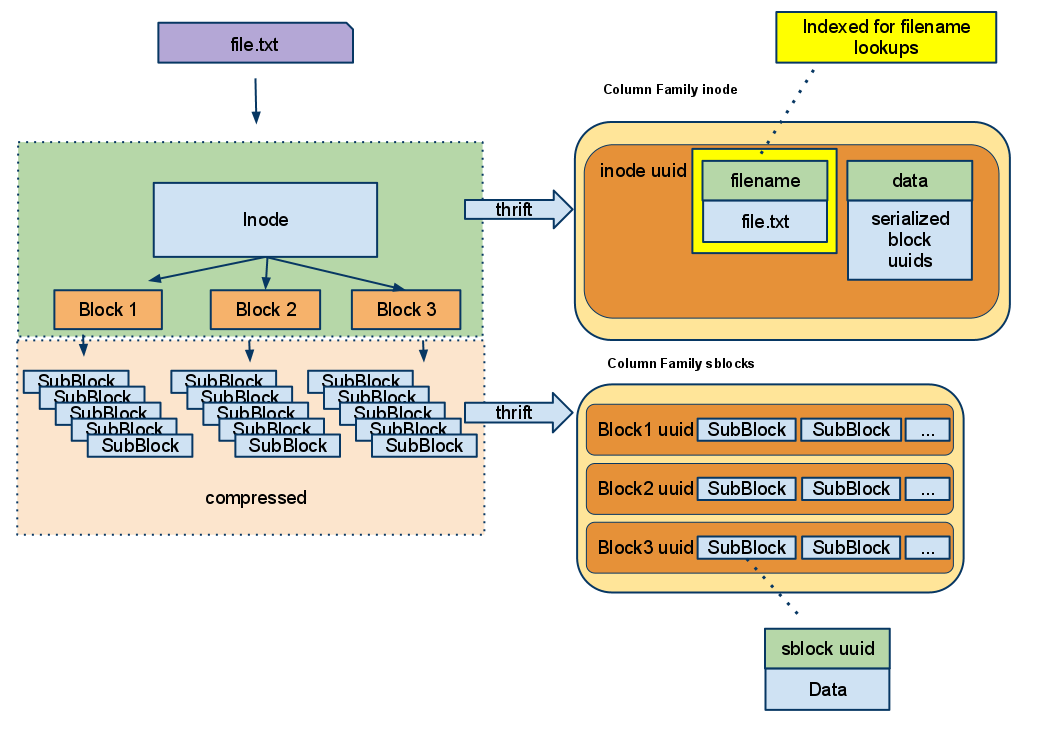
Except for Cassandra, CFS has almost no server-side components. All the operations like looking up or creating files, splitting/merging subblocks, and data compression/decompression are performed by the client. Therefore to access CFS, the client needs thrift access to Cassandra.
CFS Limitations
Unfortunately this design comes with a few limitations:
- A subblock must be fully loaded into memory and transferred between the client and the storage before the operation timeout happens. This increases memory use.
- When writing to Cassandra, each row has to be written at least twice - for the first time to the commit log, and for the second time to a new sstable on disk.
- There is additional I/O overhead of Cassandra compaction, particularly for write-heavy workloads.
- Reclaiming space after deleting files is deferred until compaction. This can get particularly bad when dealing with workloads that cause writing temporary files, e.g. when doing exploratory analytics with Spark. When SizeTieredCompactionStrategy is used, this can result in taking several times more space than needed.
- Authorization is weak, because it is implemented on the client-side. The server administrator can only restrict who may and who may not access CFS at all, but it is not possible to restrict access to a part of the directory tree.
To alleviate the delayed delete problem and reduce both the time and space overhead of compaction, CfsCompactionStrategy was introduced in DSE 2.1. This strategy flushes each block to a separate sstable. When the file needs to be deleted, it just deletes the right sstables from disk. It also doesn't waste I/O for repeatedly rewriting sstables. This is much faster and more efficient for short-lived files than reading and compacting sstables together, however in practice it introduces another set of problems. While there is no hard limit on the number of sstables in the keyspace, each sstable comes at some cost of used resources like file descriptors and memory. Too many sstables make it slow to find data and blow up some internal Cassandra structures like interval trees. It is very easy to run into issues by having too many small files. Simply put, CfsCompactionStrategy didn't scale in the general case, so it has been deprecated and removed in DSE 5.0.
Introducing DSEFS
DSEFS is the new default distributed file system in DSE 5.1. DSEFS is not just an evolution of CFS. DSEFS has been architected from scratch to address the shortcomings of CFS, as well as HDFS.
DSEFS supports all features of CFS and covers the basic subset of HDFS and WebHDFS APIs to enable seamless integration with Apache Spark and other tools that can work with HDFS. It also comes with a few unique features. Notable features include:
- creating, listing, moving, renaming, deleting files and directories
- optional password / token authentication and kerberos authentication in Spark
- POSIX permissions and file attributes
- interactive console with access to DSEFS, local file system, CFS and other HDFS-compatible filesystems
- querying block locations for efficient data local processing in Spark or Hadoop
- replication and block size control
- transparent optional LZ4 compression
- a utility to check filesystem integrity (fsck)
- a utility to view status of the cluster (e.g. disk usage)
DSEFS Interactive Console
DSEFS comes with a new console that speeds up interacting with remote filesystems. Previously, to access CFS, you had to launchdse hadoop fs command which started a new JVM, loaded required classes, then connected to the server and finally executed the requested command. Launching and connecting was repeated for every single command and could take a few seconds every time. DSEFS console can be launched only once and then can execute many commands reusing the same connection. It also understands a concept of working directory, so you don't need to type full remote paths with every command. You can use many file systems like DSEFS, CFS, HDFS, local file system in a single session. Tab-completion of paths helps to improve interaction speed even more.
DSEFS Architecture
The major difference between CFS and DSEFS architectures is that in DSEFS the data storage layer is separate from the metadata storage layer. Metadata, which includes information about paths, file names, file attributes, as well as pointers to data, are stored in Cassandra tables. File data are stored outside Cassandra, directly in the node's local file system. Data is split into blocks, each 64 MB large by default, and each block is stored in its own file.
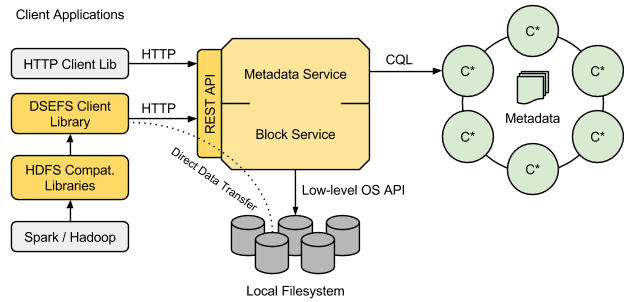
Storing data blocks in the local file system has several advantages:
- There is virtually no limit on the number of blocks that can be stored, other than the capacity of storage devices installed in the cluster. Blocks at rest do not take any other system resources such as memory or file descriptors.
- The DSEFS server can stream a data block over the network very efficiently using sendfile without copying any part of it to JVM heap nor userspace memory.
- Writing data to blocks skips the Cassandra commit log, so every block needs to be written only once.
- Deleting files is fast and space is reclaimed immediately. Each block is stored in its own file in some storage directory, so deleting a file from DSEFS is just deleting files from the local file system. There is no need to wait for a compaction operation.
- Looking up blocks is faster than accessing sstables. Blocks can be quickly accessed directly by their name which is stored in the metadata.
- Replication for data can be configured in a very fine grained way, separately from Cassandra replication. For example files in one directory can have RF=3 and files in another directory can have RF=5. You can also set replication factor for each file.
- Data placement is much more flexible than what can be achieved with consistent hashing. A coordinator may choose to place a block on the local node to save network bandwidth or to place a block on the node that has low disk usage to balance the cluster.
Using Cassandra to store metadata has also many advantages:
- The Cassandra tabular data model is well suited for efficient storage and quick lookup of information about files and block locations. Metadata is tiny compared to data, and comprised of pieces of information of such types that Cassandra can handle well.
- Cassandra offers excellent scalability, with capacity not limited by the amount of memory available to a single server (such as for an HDFS NameNode). This means DSEFS can store a virtually unlimited number of files.
- The shared-nothing architecture of Cassandra offers strong high availability guarantees and allows DSEFS to be shared-nothing as well. Any node of your cluster may fail and DSEFS continues to work for both reads and writes. There are no special "master" nodes like HDFS NameNode. Hence, there are no single points of failure, even temporary. DSEFS clients can connect to any node of the DSE cluster that runs DSEFS.
- Cassandra lightweight transactions allow to make some operations atomic within a data center, e.g. if multiple clients in the same data center request to create the same path, at most one will succeed.
- Cassandra offers standard tools like cqlsh to query and manipulate data. In some cases it may be useful to have easy access to internal file system metadata structures, e.g. when debugging or recovering data.
The following diagram shows how DSEFS nodes work together:
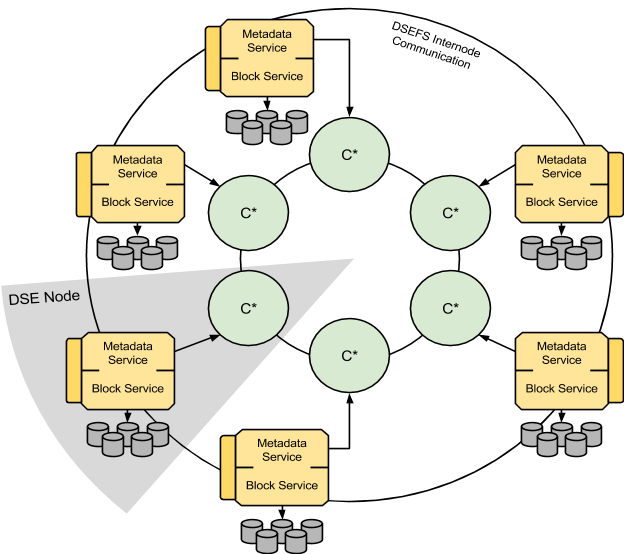
Clients may talk to any node by HTTP to port 5598. The contacted node becomes the coordinator for the request. When accessing a file, the coordinator consults the metadata layer to check if the file exists, then to check permissions and finally to get the list of block identifiers and block locations. Then it fetches the blocks either from local block layer or from remote nodes by using DSEFS internode communication on port 5599. The coordinator joins blocks together and streams them to the client. In the future we may implement an optimization to skip the coordinator and request and join blocks directly by the client.
When writing a file, first the appropriate records are created in the metadata to register the new file, then the incoming data stream is split into blocks and sent to the appropriate block locations. After successfully writing a block, metadata is updated to reflect that fact.
DSEFS Implementation
DSEFS has been implemented in the Scala programming language. It uses Netty for network connectivity, memory management and asynchronous task execution.
Netty together with Scala-Async allow for non-blocking, asynchronous style of concurrent programming, without callback hell and without explicit thread synchronization. A small number of threads is multiplexed between many connections. A request is always handled by a single thread. This thread-per-core parallelism model greatly improves cache efficiency, reduces the frequency of context switches and keeps the cost of connections low. Connections between the client and the server as well as between the nodes are persistent and shared by multiple requests.
DSEFS allocates buffers from off-heap memory with Netty pooled allocator. JVM heap is used almost exclusively for temporary, short-lived objects. Therefore DSEFS is GC friendly. When internally testing the DSEFS server in standalone mode, external to DSE, we've been able to use JVM heaps of size as low as 64 MB (yes, megabytes) without a noticeable drop in performance.
Contrary to CFS, DSEFS doesn't use the old Thrift API to connect to DSE. Instead, it uses DataStax Java Driver and CQL. CFS was the last DSE component using Thrift, so if you migrate your applications to DSEFS, you can simply disable Thrift API by setting cassandra.yaml start_rpc property to false.
Conclusion
DSE 5.1 comes with a modern, efficient, scalable and highly available distributed file system. There is no reason to use CFS any more. CFS has been deprecated but left available so you can copy your old data to the new file system.
For documentation on DSEFS visit:
https://docs.datastax.com/en/dse/5.1/dse-dev/datastax_enterprise/analytics/dsefsTOC.html
We'd love to get your feedback on your experience with DSEFS! Are there any features you want added?
More Technology
View All
Introducing the DataStax AI Terraform Module


