Compaction Improvements in Cassandra 2.1

Ryan McGuire

One feature that makes Cassandra so performant is its strategy to never execute in-place updates. When you write to a column in an existing row, this gets written to the end of the commitlog (and eventually to an SSTable.) Likewise, for deletes, a tombstone gets written to the end of the commitlog (and eventually to an SSTable.) The old column values are still there, and Cassandra knows how to merge these update chains together to get the current column value. This strategy makes disk usage patterns very linear and minimizes disk seek times. These are all very good features for performance.
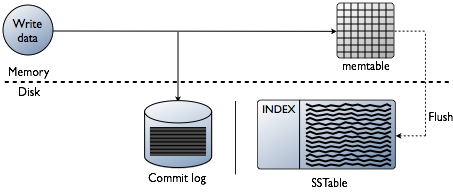
The only problem is that, over time, you would be storing not just your data in Cassandra, but the entire history of your data: inserts, updates, and deletes. This takes a toll on performance when you wish to access that data, because, in addition to the wasted disk space, Cassandra has to replay this series of events to get the most up-to-date version of your data. This is what compaction helps to avoid.
Cassandra’s compaction routine will process your SSTables, reducing this history of changes down to a single set of the most recent data per row (bye-bye, tombstones). Once compaction is done, Cassandra reads should be nice and fast once again.
Except, there’s still a problem here. Operating systems use something called a page cache, which stores contents of frequently accessed files in memory to avoid having to fetch them from disk. On Linux, you can see for yourself how large this page cache is by running the free command:
$ free -m
total used free shared buffers cached
Mem: 15995 15681 313 150 285 10708
-/+ buffers/cache: 4687 11307
Swap: 0 0 0
That’s from my own laptop, which has 16GB of RAM. The last column, cached, is showing that 10GB of my RAM is not being used for any program I’m running; but it’s still being put to good use caching frequently accessed files from my hard drive.
When you read data from Cassandra, this same cache is relied upon to make things fast. The problem is, compaction destroys the original SSTable and creates a new one, which is not in the cache yet.
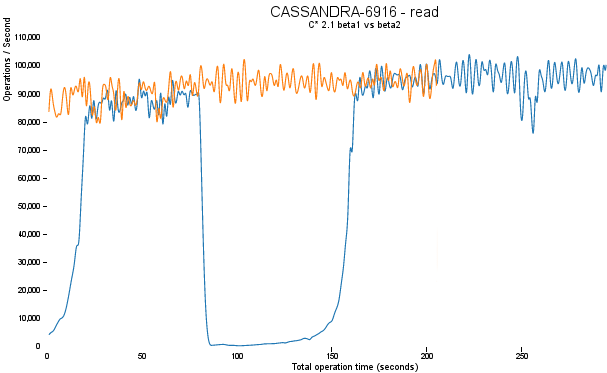
The above chart shows a read operation running in Cassandra 2.1 beta1 (blue line) vs. 2.1 beta2 (orange line.) This test scenario is a rather extreme case of a bulk load and verify operation, which may or may not be a typical situation, but it highlights the topic at hand. This was performed right after a large write operation, which induced a compaction. In beta1, as soon as we start to read, we immediately get a cache miss. The data we just wrote in the previous operation is no longer cached, because Cassandra threw the file (and cache) away once the compaction finished. This gradually improves as the new SSTable is read and re-cached, but this process repeats itself on further cache misses.
The patch introduced in CASSANDRA-6916 (which will be included in the upcoming 2.1 beta2 release) greatly improves this by introducing incremental replacement of compacted SSTables. Instead of waiting for the entire compaction to finish and then throwing away the old SSTable (and cache), we can read data directly from the new SSTable even before it finishes writing. As data is written to the new SSTable and reads are directed to it, the corresponding data in the old SSTables is no longer accessed and is evicted from the page cache. Thus begins an incremental process of caching the new SSTable, while directing reads away from the old one. The dramatic cache miss is gone. This lets Cassandra 2.1 provide predictable high performance even under heavy load.
More Company
View All


Introducing Tejas Kumar, Developer Relations Engineer
