

Cassandra 1.2 is currently in beta, with final release planned before the end of the year. 1.2 finalizes support for the improved, but backwards-incompatible version 3 of the CQL language. We've previously covered CQL3 from a high level and by example; here, I'd like to back up a little and explain why this evolution was necessary, as well as some of the improvements it allows us to bring to the developer experience.
TLDR: backwards compatibility
Before covering anything else I want to emphasize that the Thrift API is not going anywhere. As far back as Cassandra 0.7, we committed to preserving backwards compatibility and not breaking working code, and nothing here changes that commitment.
(At a technical level, CQL3 can use either the new binary protocol, or Thrift RPC, but its Thrift methods are separate from the ones used by CQL2.)
A brief overview of the Cassandra storage engine
Bigtable, although Cassandra goes beyond Bigtable in many ways, including support for indexes and distributed counters.
To support high-performance writes, Cassandra uses a log-structured storage engine. There is no overwrite-in-place: updates append new data that gets merged with older data in that row in the background.
This means that unlike btree-based designes, Cassandra write performance does not degrade as the existing data set grows. It also means that there is no distinction between INSERT and UPDATE operations; the only operation provided is effectively INSERT OR UPDATE.
Cassandra's distributed nature also influences the storage engine design. In particular, Cassandra recognizes that distributed joins are performance killers: not only do they require lots of expensive random reads, but these reads have to be merged across the network, dramatically increasing the overhead involved.
Early observers of the NoSQL space concluded that if Cassandra does not do joins for you, then joins should be done client-side. Not so! Instead of joins, Cassandra encourages denormalization: at update time, clients should write the records to multiple columnfamilies, such that queries (known ahead of time) can be retrieved from a single row.
To support this, Cassandra's storage engine provides wide, sparse rows. These rows can correspond 1:1 with business objects, but more often they encode data in the cell name as well as the value -- thus a "row" becomes more of an (ordered) map, than a relational row. This is the kind of model we had in mind when we improved the storage engine to allow up to two billion columns per row.
Example: a music service
There are three primary patterns in applying Cassandra's storage model:
- Simple object -> row mapping; fields correspond to columns
- Sparse objects: objects and fields still correspond to rows and columns, respectively, but we do not know what the fields will be in advance
- Materialized views: Cassandra rows are resultsets; objects are each packed into one column in the cassandra row using CompositeType
Let's look at examples of each of these in the context a social music service. Our service will have just two object types: songs and playlists. (All playlists are public -- we're skipping describing any kind of user authentication for brevity.)
Old-style schema with the CLI
The songs data is an example of the first pattern: we'll record title, album, and artist, as well as the actual audio file itself:
create column family songs
with key_validation_class = UUIDType
and comparator = UTF8Type -- cell names are strings
and column_metdata = [{column_name: title, validation_class: UTF8Type},
{column_name: album, validation_class: UTF8Type},
{column_name: artist, validation_class: UTF8Type},
{column_name: data, validation_class: BytesType}];
Data in the Songs columnfamily will look like this to the storage engine. Note how cell names are repeated, like key:value pairs in a Map:

(Note that using UUIDs as surrogate keys instead of sequential integers is a Cassandra best practice; using natural keys is also a good option.)
But what if we also want to allow the users to tag the songs? The most straightforward solution is to add a second columnfamily following the second pattern. Here you see the row being used as a Set, or more pedantically a Map, where Map's keys -- the cell names -- are the tags, and the values are empty.
Instead of specifying cell name literals in our columnfamily definition, we just specify a comparator to tell Cassandra what type the names will be.
create column family song_tags
with key_validation_class = UUIDType
and comparator = UTF8Type -- cell names are still strings, but user-defined
Here's what that looks like with a couple songs tagged:

Finally, we want to allow users to group songs into playlists. The relational way to do this would be to create a playlists table with a foreign key to the songs, but as described above we're going to denormalize instead.
The way we're going to do that is to pack each song in a playlist into one column, so fetching a playlist is just a single primary key lookup. Cassandra provides CompositeType for this. We also use the column value here to hold the song id, which we tell Cassandra about with default_validation_class:
create column family playlists
with key_validation_class = UUIDType
and comparator = 'CompositeType(UTF8Type, UTF8Type, UTF8Type)' -- title, album, artist
and default_validation_class = UUIDType; -- song id so we can fetch the data blob
A playlist with the songs from earlier would then look like this -- one cell, or Map entry, per song, with the song's attributes packed into a composite name:

The Thrift RPC API
The primary method for fetching data from Cassandra over the Thrift api is get_slice. There are several variants on this theme but get_slice covers the important concepts.
A slice to Thrift means a set of columns from a single row, described either by name or as a contiguous run of columns from a starting point. This last is useful for denormalized resultset columnfamilies like playlists since columns are always ordered by comparator.
In our example, the only columnfamily with statically defined cell names is songs. We can fetch a given song as follows:
get_slice('62c36092-82a1-3a00-93d1-46196ee77204', -- the row key uuid
ColumnParent('songs'),
SlicePredicate(column_names=['title', 'album', 'artist', 'data']),
ConsistencyLevel.ONE)
(I'm simplifying here just a little by using human-readable forms for the row key and cell names; the actual Thrift API requires these be encoded as byte arrays.)
To fetch the tags for a song, since we don't know what tag names might have been given we'll ask Cassandra to give us the entire row -- or rather, the first ten entries -- as represented by a SliceRange with empty start and finish:
get_slice('62c36092-82a1-3a00-93d1-46196ee77204',
ColumnParent('song_tags'),
SlicePredicate(slice_range=SliceRange(start='', finish='', count=10)),
ConsistencyLevel.ONE)
A slice for playlists would be similar.
CQL2: a language for wide rows
CQL2 was introduced in Cassandra 0.8 and extended in 1.0. The goal was to provide a SQL-like language for Cassandra that would be more extensible than the original Thrift API. However, CQL2 hewed extremely close to the concepts from thrift. Here are our column family definitions in CQL2:
CREATE COLUMNFAMILY songs (
id uuid PRIMARY KEY,
title text,
album text,
artist text,
data blob
);
CREATE COLUMNFAMILY song_tags (
id uuid PRIMARY KEY
) WITH comparator=text;
CREATE COLUMNFAMILY playlists (
id uuid PRIMARY KEY
) WITH comparator='CompositeType(UTF8Type, UTF8Type, UTF8Type)' AND default_validation=uuid;
CQL2 makes some syntactic improvements over the cli above, notably around static column definitions. Interacting with the songs columnfamily will look familiar to SQL users:
insert into songs (id, title, artist, album)
values ('a3e64f8f...', 'La Grange', 'ZZ Top', 'Tres Hombres');
insert into songs (id, title, artist, album)
values ('8a172618...', 'Moving in Stereo', 'Fu Manchu', 'We Must Obey');
insert into songs (id, title, artist, album)
values ('2b09185b...', 'Outside Woman Blues', 'Back Door Slam', 'Roll Away');
SELECT * FROM songs;
id | album | artist | title
-------------+--------------+----------------+---------------------
2b09185b... | Roll Away | Back Door Slam | Outside Woman Blues
8a172618... | We Must Obey | Fu Manchu | Moving in Stereo
a3e64f8f... | Tres Hombres | ZZ Top | La Grange
Unfortunately that's about where the good news ends. Fundamentally CQL2 still forces us to deal with the raw storage engine representation of the data. This applies to queries as well, where CQL2 adds a SliceRange syntax (..) that directly maps to the get_slice Thrift call above.
Here's what that looks like for song_tags:
insert into song_tags ('id', 'blues', '1973')
values ('a3e64f8f-bd44-4f28-b8d9-6938726e34d4', '', '');
insert into song_tags ('id', 'covers', '2007')
values ('8a172618-b121-4136-bb10-f665cfc469eb', '', '');
SELECT * FROM song_tags;
id,8a172618-b121-4136-bb10-f665cfc469eb | 2007, | covers,
id,a3e64f8f-bd44-4f28-b8d9-6938726e34d4 | 1973, | blues,
SELECT 'a'..'f' FROM song_tags WHERE id = '8a172618-b121-4136-bb10-f665cfc469eb';
covers
--------
(You can see how cqlsh switches to a "tuple" format for wide rows that do not have cell names in common.)
We're going to have to skip actually inserting and reading playlists from CQL2 since cqlsh does not support interacting with CompositeType columns. We'll come back to this in the CQL3 section.
CQL2 was easy to implement since it maps so straightforwardly to what the storage engine has been doing all along. But it turns out there are several major problems with this approach:
- It requires clients to manually decode the CompositeType packing when processing values from a columnfamily like playlists. This has negative implications for non-Java clients -- like the Python cqlsh -- which have to reverse-engineer the serialization format, and even with Java clients the unpacking is cumbersome from a user perspective.
- It does not compose with the row-oriented parts of SQL; e.g., we have FIRST to limit the number of columns, distinct from LIMIT for the number of rows.
- Row-oriented functions like count don't work either, e.g. to count the number of columns (records) in a single playlist; Thrift hacks around that by adding separate count methods for each operation; CQL2 never produced a solution for this common use case.
- You can't index the data in a wide row since the components of the CompositeType are not named, and if you did come up with a way to specify the index, you still couldn't specify predicates in the (row-oriented) WHERE clause; you'd have to invent another kind of predicate syntax just for the slices. Note that this is a problem with the Thrift API as well, not just CQL2.
- More qualitatively, years of experience explaining the "sparse, wide rows" model has driven home the point that very few people find that and the attendant CompositeType-packing naturally intuitive.
Thus, we went back to the drawing board in Cassandra 1.1 and revised the CQL language to address these problems.
CQL3
CQL3 makes one very important changes to how it presents Cassandra data: wide rows are "transposed" and unpacked into named columns. From a relational standpoint, you can think of storage engine rows as partitions, within which (object) rows are clustered.
The songs data doesn't really change, since we had a static set of columns defined there:
CREATE TABLE songs (
id uuid PRIMARY KEY,
title text,
album text,
artist text,
data blob
);
For the song tags, we have two choices. If we need to be compatible with data from an old-style schema, we can do that as follows:
CREATE TABLE song_tags (
id uuid,
tag_name text,
PRIMARY KEY (id, tag_name)
);
Thus, we're giving the storage engine cell name, that we were using as a Map key, its own CQL3 column.
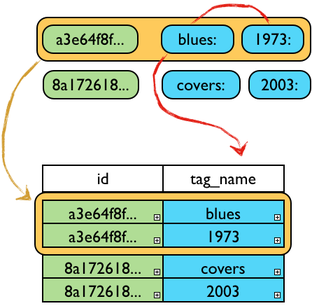
The orange arrow shows how a single storage engine row becomes a CQL3 partition, with one CQL3 row per storage engine cell. The red arrow shows how the storage engine cell name is accessible in the tag column.
If we simply use the old schema directly as-is, Cassandra will give cell names and values autogenerated CQL3 names: column1, column2, and so forth. Here I'm accessing the data inserted earlier from CQL2, but with cqlsh --cql3:
SELECT * FROM song_tags;
id | column1 | value
--------------------------------------+---------+-------
8a172618-b121-4136-bb10-f665cfc469eb | 2007 |
8a172618-b121-4136-bb10-f665cfc469eb | covers |
a3e64f8f-bd44-4f28-b8d9-6938726e34d4 | 1973 |
a3e64f8f-bd44-4f28-b8d9-6938726e34d4 | blues |
However, instead of creating a separate columnfamily to act as our tags set, CQL3 allows us to more naturally represent that sparse tag collection directly in the songs table, as a Set data type:
ALTER TABLE songs ADD tags set<text>;
Finally, we would represent the playlist data as a CQL3 table as follows:
CREATE TABLE playlists (
id uuid,
title text,
album text,
artist text,
song_id uuid,
PRIMARY KEY (id, title, album, artist)
);
insert into playlists (id, song_id, title, artist, album)
values ('62c36092-82a1-3a00-93d1-46196ee77204', 'a3e64f8f-bd44-4f28-b8d9-6938726e34d4', 'La Grange', 'ZZ Top', 'Tres Hombres');
insert into playlists (id, song_id, title, artist, album)
values ('62c36092-82a1-3a00-93d1-46196ee77204', '8a172618-b121-4136-bb10-f665cfc469eb', 'Moving in Stereo', 'Fu Manchu', 'We Must Obey');
insert into playlists (id, song_id, title, artist, album)
values ('62c36092-82a1-3a00-93d1-46196ee77204', '2b09185b-fb5a-4734-9b56-49077de9edbf', 'Outside Woman Blues', 'Back Door Slam', 'Roll Away');
SELECT * FROM playlists;
id | title | album | artist | song_id
-------------+---------------------+--------------+----------------+------------
62c36092... | La Grange | Tres Hombres | ZZ Top | a3e64f8f...
62c36092... | Moving in Stereo | We Must Obey | Fu Manchu | 8a172618...
62c36092... | Outside Woman Blues | Roll Away | Back Door Slam | 2b09185b...
Which maps to the storage engine's representation as follows:
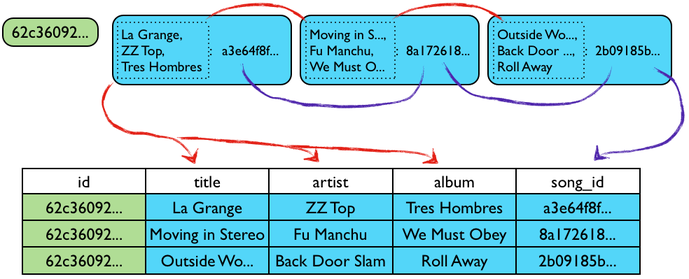
The red arrow shows how the cell name gets unpacked into three CQL3 columns. The purple arrow shows how the cell value becomes the song_id column.
Presenting a storage engine row as a partition of multiple object rows solves all the problems we had with CQL2: clients do not have to know about the details of CompositeType packing, there is no distinction between "slice" syntax and normal WHERE predicates, and indexing wide rows becomes possible.
To illustrate this last, consider the query SELECT * FROM playlists WHERE artist = 'Fu Manchu'. With the schema as given so far, this requires a sequential scan across the entire playlists dataset. But if we first CREATE INDEX ON playlists(artist), Cassandra can efficiently pull out the records in question.
There is no way to do this with the Thrift or CQL2 APIs -- not because we have chosen not to expose it there, but because there is no way to specify "the artist component of my CompositeType cell" in either index creation, or querying.
Conclusion
We've seen here how CQL3 allows mapping Cassandra storage engine cells to a more powerful and more natural rows-and-columns representation. In another post I'll explore in more detail some of the limitations of the one-cell-per-row design and how CQL3 improves on that limitation as well.
More Technology
View All


