Data Model Meets World - Blog Series

Jeffrey CarpenterSoftware Engineer - Stargate

A data model based on simplifying assumptions won't fly in a real-world application.
Note: This blog series coincides with the short course Data Model Meets World. This content originally appeared on Jeff's personal blog and is reproduced here by permission.
I was contacted recently by a reader of of my book Cassandra: The Definitive Guide, 2nd Edition (O’Reilly), who asked several questions about how the hotel data model presented in the book would work in practice. In response, I explained several of the simplifications I made in putting together examples for the book, and how things might look different in a real world application.
Afterward, it occurred to me that I should share this conversation with a wider audience, because creating good data models has been proven to be one of the key factors in building successful applications with Apache Cassandra. My hope is that this series of articles will help you to overcome some of the typical challenges of data modeling for real applications. I’ve also recorded a tutorial here on DataStax Academy which you can watch at Data Model Meets World.
It started with a simple hotel data
Humans do best at learning concepts and techniques when we can see an example of principles in action. Learning how to create data models for Cassandra is no different.
You can read the data modeling chapter of the book for free at the O'Reilly website.
For your convenience, here is the physical data model for hotels presented in the book (“POI” stands for “Point of Interest”):
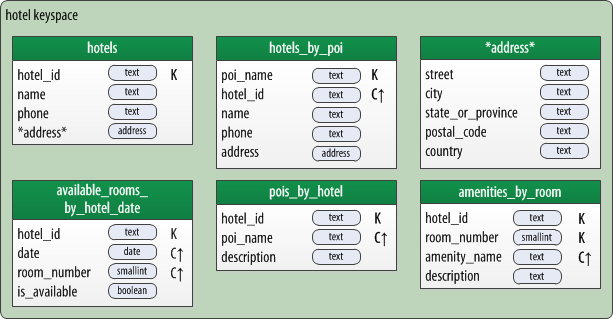
A Cassandra physical data model for hotel data.
The CQL schema corresponding to this design is included in the book, and is also available on GitHub.
The tables shown above are designed to support access patterns that might be associated with shopping for hotel rooms, such as:
- finding hotels near a point of interest
- learning about hotel rooms and amenities
- inquiring about the availability of rooms for one or more nights
In order to keep the data model simple, a number of obvious possible extensions were omitted, such as:
- storing a richer set of attributes for hotels, amenities, and rooms
- supporting a more robust set of hotel search options
- I’m sure you can think of others
All in all, I felt pretty good about this data model, since it was concise yet detailed enough to introduce the key discussion points around Cassandra data modeling that I wanted to cover.
And yet…
Questions from the real world
…I received the following series of insightful questions from a reader of the book who is wrestling with how the sample hotel model would work in a real application:
- In Chapter 5 a data model is presented for hotels. A hotel_id is part
of the key for many tables. From the book, I learned that you need the partition key beforehand to be able to query the tables presented. How would you get the hotel_id, given that there might by hundreds of hotels in a large corporation? A sample key like AZ123 (presented in Chapter 9) would be hard to know ‘by heart’. Would you use a separate Key/value store to manage those ID’s and the hotel names? Would Cassandra fit the bill for managing the keys? If so, how? - In the same data model, points-of-interest would be managed by ‘names’. For the book, I gather that poi_names have to be unique. How would uniqueness be guaranteed across the cluster, given that new hotels might be acquired weekly and POIs may change over time on a global scale? From within an application to manage the ‘points-of-interest’, I would be tempted to read all poi-names before trying to add a new one, but wouldn’t that result in a full cluster scan? Or would you hard-code the POI names in the application, which goes against the principle of separating data layer and application layer. Is there any better solution given a choice of Cassandra? How would users get a list of POI names (e.g. within a certain geographical region)? Would you use Cassandra for that?
But there’s a deeper level to these questions that I can’t just dismiss by saying “relax, it’s just an example”. This reader is anticipating some of the deeper architectural considerations and tradeoffs that come into play into a real system:
- Managing relationships between data types
- The unique identification of records
- Search options beyond exact matching
- Deciding when and how to cache data
- Polyglot persistence and what it means to be “multi-model”
These are exactly the kinds of pressures that come to bear on any model we create that test their “air worthiness”, but the stakes are especially high for our data models.
Over this series of posts, we’ll explore these issues and discuss the implications of our data modeling choices on qualities such as scalability, extensibility, and maintainability. If we’re successful, the journey will make us better data modelers, developers, and architects.
Let’s start by taking a step back to look at how we arrived at the physical data model that is presented in the book. If you’ve received any instruction on data modeling for Cassandra, you’ll be familiar with the recommended practice of “Query-first” design, in which you identify the required queries (or “access patterns”) for your application and design tables based on those queries. In the book, I present the access patterns shown below, which a hotel reservation application might provide to support shopping and booking stays at a hotel:
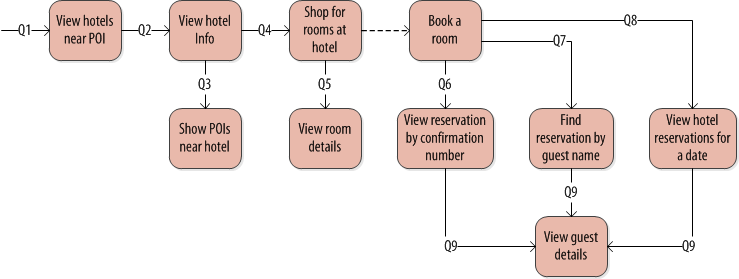
Access patterns for a hotel reservation application
As you can see, the access patterns are shown as a directed graph, where the results of one query provide the information required to make the next query. Thus, in order to shop for hotel rooms (at least, according to this example), you first enter the name of the POI where you want to go (Q1 — find POI by name), which enables the retrieval of a list of hotels, and you select one or more of these to view the hotel detail (Q2 — find a hotel by ID).
The graph of access patterns is repeated in the logical data model shown below, which is drawn using the “Chebotko diagram” notation:
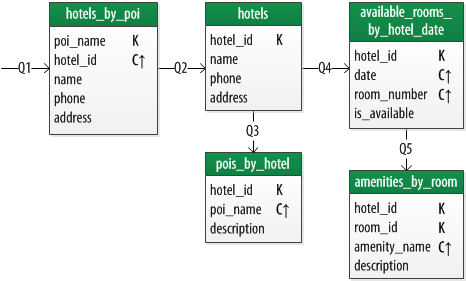
Chebotko diagram showing a logical data model for hotels
As with the access pattern diagram, you can follow the arrows see how Q1 is used to find records in the hotels_by_poi table, and how the hotel_ids returned from Q1 can be used in Q2 to find records in the hotels table. This is a simple example of the principle of denormalization which is recommended in Cassandra data modeling; the same information about a hotel is repeated in two different tables, each of which supports a different form of query.
If you’re building a naïve hotel shopping application, this might be all you need — the ability to get a list of hotels with basic identifying information, and the ability to request additional information on a specific hotel.
The problem with this example is that is there’s only one entry point to finding a hotel, and therefore only one shopping path that our application could support. The only way to find a hotel is to have a priori knowledge of its ID, or to locate it based on a point of interest. A real world application must support multiple ways of locating hotels — by attributes such as name, geolocation, or amenities.
Supporting these additional queries will require some affordances in our data model, such as additional hotel tables keyed by the desired attributes. Other options available to us include Cassandra’s indexes and materialized views, as well as complementary search technologies, each of which have their place if used properly. We’ll explore these options in more detail in future installments, including advice on when to use each approach, and how to leave room in your data model design for future expansion.
Making our data models flight ready
We’ve gotten a great start on our journey by looking at how we navigate relationships between types, but there are still a lot of remaining stops.
Upcoming articles in this series will continue to explore Cassandra data modeling and architecture issues. Let’s take our fledgling data models and make them fly!
More Technology
View All
Introducing the DataStax AI Terraform Module


