Data Model Meets World, Part V: Data Remodeling

Jeffrey CarpenterSoftware Engineer - Stargate

You’ve created an awesome data model, but will it stand the test of time?
Note: This blog series coincides with the short course Data Model Meets World. This content originally appeared on Jeff's personal blog and is reproduced here by permission.
In this series of articles, I’m responding to a series of questions that I received from a reader of of my book Cassandra: The Definitive Guide, 2nd Edition (O’Reilly), who asked several questions about how the hotel data model presented in the book would work in practice.
Previously we’ve discussed how to navigate relationships between different data types, how to maintain the unique identity of data over time, how to reconcile your data model with your architecture, and when to use a multi-model database.
This time we’re going to talk about remodeling. With any system that has success over time, the need will arise to store new data and to leverage existing data in new ways. Like adding a new bedroom to a house or modernizing your kitchen, data remodeling is a delicate matter that should be approached with care to avoid damaging what is already in place.
What is “data remodeling”?
I admit to making this term up, but I think it provides a helpful analogy. Let’s define data remodeling as making changes to an existing data model. This is particularly interesting when the existing data model is already in a deployed system.
What kinds of changes might be involved in a data remodel? Consider the following:
- Adding a new data type (which might imply multiple tables)
- Adding attributes to an existing data type
- Adding a new way of querying an existing data type
- Changing the type of an existing attribute
- Removing a table
- Removing an attribute
There are times in remodeling a home where you need to knock out a wall in order to open up space, and by analogy, data remodeling will sometimes lead you to delete an attribute or a table that is no longer relevant. The data modeling decisions here are pretty trivial and are simple to execute via CQL commands like DROP TABLE or ALTER TABLE … DROP.
Similarly, changing the type of a column is not supported in Cassandra. That sort of change may be handled by adding a new column and removing an old column. The semantics of re-populating the new column based on the old column are more of a data maintenance or data migration question, not a data modeling question.
In terms of additions, adding new data types and attributes are straightforward changes that we can handle via standard Cassandra data modeling techniques we’ve covered previously. This leaves us with the case that is the biggest challenge in data remodeling: adding new queries.
Query-first design, again
One of the key tenets of data modeling for Cassandra is to begin with the desired queries, or “access patterns”, and to design tables that support each of these queries. When new requirements are placed on your system, the remodeling approach looks much the same — again we start with access patterns.
For this series of articles, we’ve been using a sample hotel data model from my book. If you’re jumping into the middle of this series and would like a full introduction to this sample hotel data model, I’d suggest reading the first article in this series, or the data modeling chapter from the book, which is freely available at the O’Reilly website.
Taking a look at the access patterns identified in the book, let’s focus on those that relate to searching for hotels. The options for finding hotels seem pretty limited. Its great to be able to locate hotels by point of interest, and looking up a hotel by a unique ID seems useful for maintenance purposes, but what about other attributes?
Consider what happens when we’re asked to extend our data model to support some additional ways to locate hotels: by name, geographic location (latitude and longitude), or amenity. The figure below shows how we might work in some new access patterns to support the requested search options.
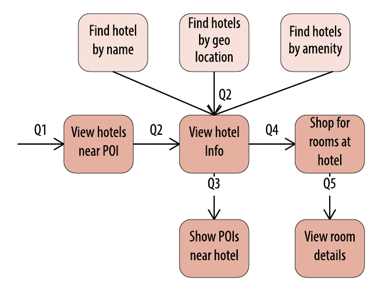
Adding new access patterns for finding hotels
As you can see, I’ve chosen to leverage some of the existing framework that was in place previously, with new access patterns for finding a hotel that then lead into the previously defined “View hotel info” access pattern.
A plethora of tables
If we follow the typical Cassandra data modeling approach of designing a table for each access pattern, this will lead to the addition of the three additional tables shown toward the right side of this diagram:
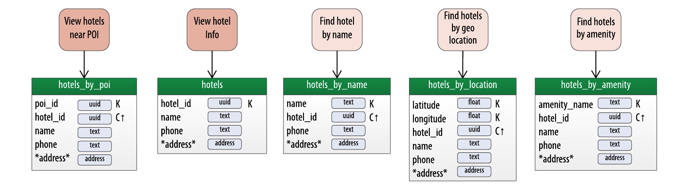
The approach of adding a table per query has its limitations
As you can see, these additional search requirements are causing the number of tables to grow. Counting the existing tables, this now adds up to 5 denormalized tables storing hotel data. Plus, this hasn’t even taken into account searching by multiple attributes at once.
What if a new requirement is identified to search by both point of interest (POI) and amenity? If we had the foresight to consider this case in our original modeling, we might have thought to leverage an existing table for this. For example the primary key for the hotels_by_poi table could be adjusted to have an additional clustering key:
PRIMARY KEY ((poi_name), amenity_name, hotel_id)
However, this would lead to duplicate entries for each hotel according to the number of amenities, which is probably not the best approach. This is actually a great case for an index, which we’ll discuss more below.
We should also consider the impact of multiple denormalized tables on the write path. In order to guarantee consistency across the multiple tables we’ll want to use batches to coordinate writes across multiple tables. This instinct to preserve integrity of writes across multiple tables is a good one, but remember that there is a performance cost associated with batches and additional burden placed on the coordinator node which services each batch write.
Options for supporting additional queries
As we have seen, these new access patterns are starting to stress our design. What options do we have to avoid creating a combinatorial explosion of tables?
Materialized Views
First, we can use the materialized views feature introduced in Cassandra 3.0. This has some similarities to the approach we showed above, where we were basically maintaining our own materialized views. Now Cassandra can take on that work for us, eliminating the need to use a batch.
The figure below uses the reservation portion of the data model from the book to show the reservations_by_confirmation table as a materialized view on the reservations_by_hotel_date table. This allows us to perform queries on the reservations_by_confirmation table by just the confirmation number.

A materialized view for reservations indexed by confirmation number
Whenever a record is written to reservations_by_hotel_date table, Cassandra updates the reservations_by_confirmation table.
To create a this materialized view, we’d use the following syntax:
CREATE MATERIALIZED VIEW reservations_by_confirmation
AS SELECT * FROM reservations_by_hotel_date
WHERE confirm_number IS NOT NULL and hotel_id IS NOT NULL and
start_date IS NOT NULL and room_number IS NOT NULL
PRIMARY KEY (confirm_number, hotel_id, start_date, room_number);
Materialized views are useful for searching on one additional column, and they’re a good fit for cases where there is high cardinality. A unique confirmation number is a good example.
SASI Indexes
Another option is to use an index. Cassandra supports a pluggable interface for defining indexes, and there are multiple implementations available. I recommend the “SSTable attached secondary index”, or SASI for short, over Cassandra’s native secondary index implementation.
The figure below shows how we depict the ability to query by confirm_number on the reservations_by_hotel_date table from a data modeling perspective:
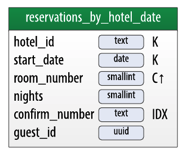
Indexing by confirmation number
SASI supports three types of indexes, PREFIX, CONTAINS, and SPARSE, where PREFIX is the default. Here is the corresponding CQL syntax for building a SASI PREFIX index:
CREATE CUSTOM INDEX reservations_by_confirmation_idx
ON reservations_by_hotel_date (confirm_number)
USING ‘org.apache.cassandra.index.sasi.SASIIndex’;
Querying against this index for exact or partial matches is quite very simple:
SELECT * FROM reservations_by_hotel_date WHERE confirm_number = ‘CXTRFQ’; // exact match
SELECT * FROM reservations_by_hotel_date WHERE confirm_number LIKE ‘C%’; // prefix match
SASI indexes perform best when the column being indexed is of lower cardinality data. Building a SASI index against a column which stores a unique confirmation number might not be the ideal case.
Geospatial Indexing
Astute observers will have noticed something about the hotels_by_locationtable I proposed in a diagram above that isn’t quite right. How would we construct a query that does a bounding box search when both the latitude and longitude are partition keys? Cassandra doesn’t allow us to do a range query on multiple attributes.
In fact, location-based or geospatial search is not supported by Cassandra natively, but there are third party index implementations that provide geospatial searches, for example, by radius or bounding box: Stratio’s Lucene index implementation, and DataStax Enterprise Search (which uses Apache Solr and Lucene on top of Cassandra). Both integrations take advantage of Cassandra’s pluggable secondary index API.
DataStax Enterprise Search
DSE Search is an especially powerful tool. It maintains search cores co-located with each Cassandra node, updating them as part of Cassandra’s write path so that data is indexed in real-time.
In addition to supporting the text and geospatial search features we’ve discussed here, DSE Search also supports advanced capabilities like search faceting. DSE Search is well integrated with the other elements of the DSE platform, for example, allowing you to perform searches on graph databases built with DSE Graph.
A strategy for supporting additional queries
Now I realize that that I’ve given you several options to think about, but only minimal advice for when to use these options. While there is no one-size-fits-all approach, here is the way I tend to approach supporting additional queries:
- For a small, potentially fixed number of queries (say, 3 or less), create a table per query.
- For a greater number of queries, create tables for those which are most important to the application. For example, the queries which are accessed the most frequently or those that are the most performance-critical.
- For additional queries, use materialized views to leverage existing tables when MVs are a good fit. Remember that the partition key elements of the original table must be included in the materialized view partition key, and that materialized views won’t perform especially well for columns with now cardinality.
- For queries where a materialized view won’t work, or you need more advanced search options, use a secondary index such as a SASI or DSE Search index. I’d prefer the DSE Search index over the SASI index, and would recommend steering clear of Cassandra’s native secondary index implementation.
- Finally, depending on your data, it’s possible that you may reach a point where you actually incur more performance debt by adding indexes than by simply filtering in application code.
One caveat I will share about materialized views and SASI indexes: because these are both relatively new features in Cassandra, there are still some edge cases that are being worked out, so make sure to test these features out under load. In fact, load testing is generally good advice for any cloud application, to make sure it scales as expected. We’ll talk more about this in the next post.
Taking a step back
As with any home improvement project, it’s important that we periodically pull ourselves out from detailed work to get a sense of the big picture and make sure our projects are on track. In data modeling, if you find yourself coming up with many combinations of attributes to query, you may need to take a step back and consider what kind of system you’re actually building.
At some point, more and more flexibility in attributes begins to cross the line into more of a search engine or even an analytics application, and you might be better served by a hybrid approach. If you’re in an analytics environment, consider loading the data into Spark and performing more complex search and analysis logic there. DSE Analytics provides a built in Spark integration which is perfect for this kind of application.
That’s all for this time. We have one more topic to examine in the next article: how to make sure your data models support high performance at scale.
More Technology
View All
Introducing the DataStax AI Terraform Module


