Integrating Apache Cassandra® and Kubernetes through K8ssandra

Aleks VolochnevDeveloper Advocate EMEA

Scalability, high performance, and fault tolerance are key features that most enterprises aim to integrate into their database architecture. Apache Cassandra® is the database of choice for large-scale cloud applications, while Kubernetes (K8s) has emerged as the leading orchestration platform for deploying and managing containerized systems in the cloud. This partnership enables enterprises to meet the snowballing requirements for data and storage in global-scale applications.
For developers, the integration between Cassandra and Kubernetes comes naturally. They both allow for horizontal or vertical scaling, and are both based on nodes, so you can expand or shrink your infrastructure with no downtime or third-party software. Simply by adding or removing nodes, you can automatically scale your applications based on demand. Both technologies are also self-healing, making them fool-proof for mission-critical applications.
In this post, you’ll learn the theories behind deploying Cassandra on Kubernetes and put it into practice using another open-source tool called K8ssandra. K8ssandra makes it efficient to operate Cassandra on K8s, and also simplifies the process of building applications on top of it.
Overview of Cassandra
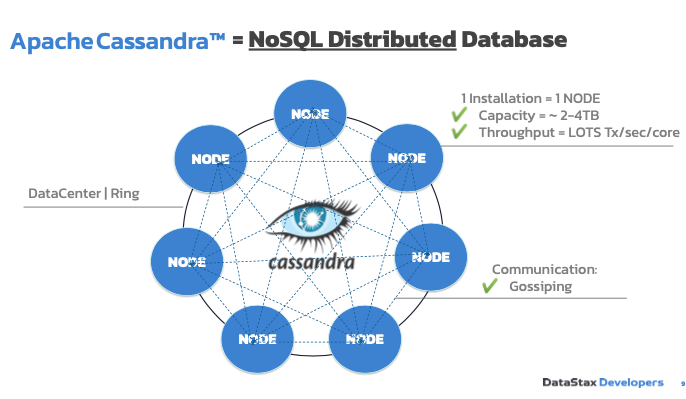
Figure 1: Apache Cassandra data distribution
Cassandra is a NoSQL distributed database that has individual nodes powering your database instead of a single machine like in the case of SQL. Each of the nodes has a capacity of two to four terabytes of data with a throughput of thousands of transactions per second, per core.
These nodes communicate through a protocol called “gossip” to understand what each of them are doing and to integrate a new node to the cluster or move data to keep it available if one of the nodes goes down. Cassandra, by nature, is a peer-to-peer system so the system automatically responds and handles when you add and remove nodes over “gossip”.
A set of these powerful nodes is called a data center or a ring. You’ll mostly work with Cassandra on the cluster level, which is a set of data centers. The ring that you see in Figure 1 comprises your data and you can make requests in and out to any particular node in the ring. The requests that you make are automatically replicated to the other nodes that are relevant in the ring.
Data distribution and replication on Cassandra
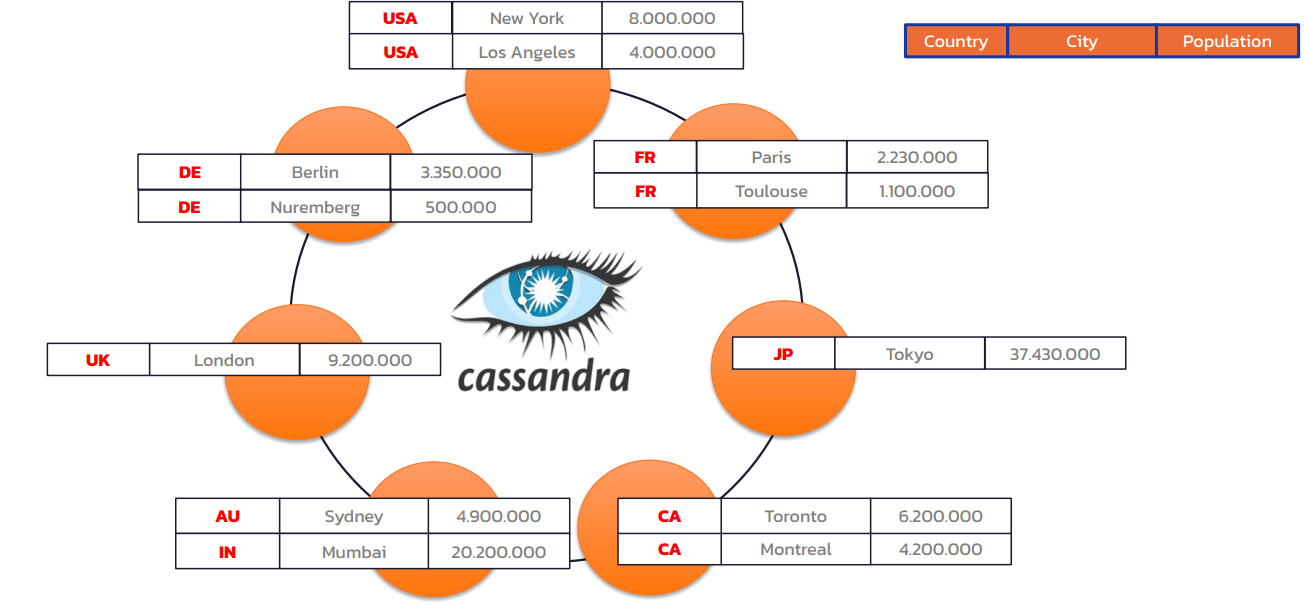
Figure 2: Data distribution on Cassandra
In Cassandra, data is partitioned by partitions in any particular table. When you create a table, you set a partition key which determines how the data will be partitioned. As data comes into the system, it’s automatically distributed around the nodes in a cluster based on what partitions the data is in. Data that has similar partitions are stored in the same place.
Cassandra also embodies inherent replication when you create your key space, equivalent to a database or a schema in a relational database. Replication determines how many data centers you have and what your replication factor is. Once you’ve set your replication, Cassandra automatically handles the data replication throughout your cluster. The default standard for the replication factor is three, which means there will be three copies of any particular partition in each data center of a cluster.
Cassandra’s replication capabilities across clusters in multiple nodes ensures robustness and fault tolerance. Even when you lose multiple nodes, you’ll still have your data.
Cassandra is also deployment agnostic—you can install it on-premises, with a cloud provider, or a mix of both. Multi-cloud is great if you want to handle peaks for a specific event, like Black Friday sales. For a full explanation on Cassandra, watch this YouTube video.
Why use containers with Cassandra?
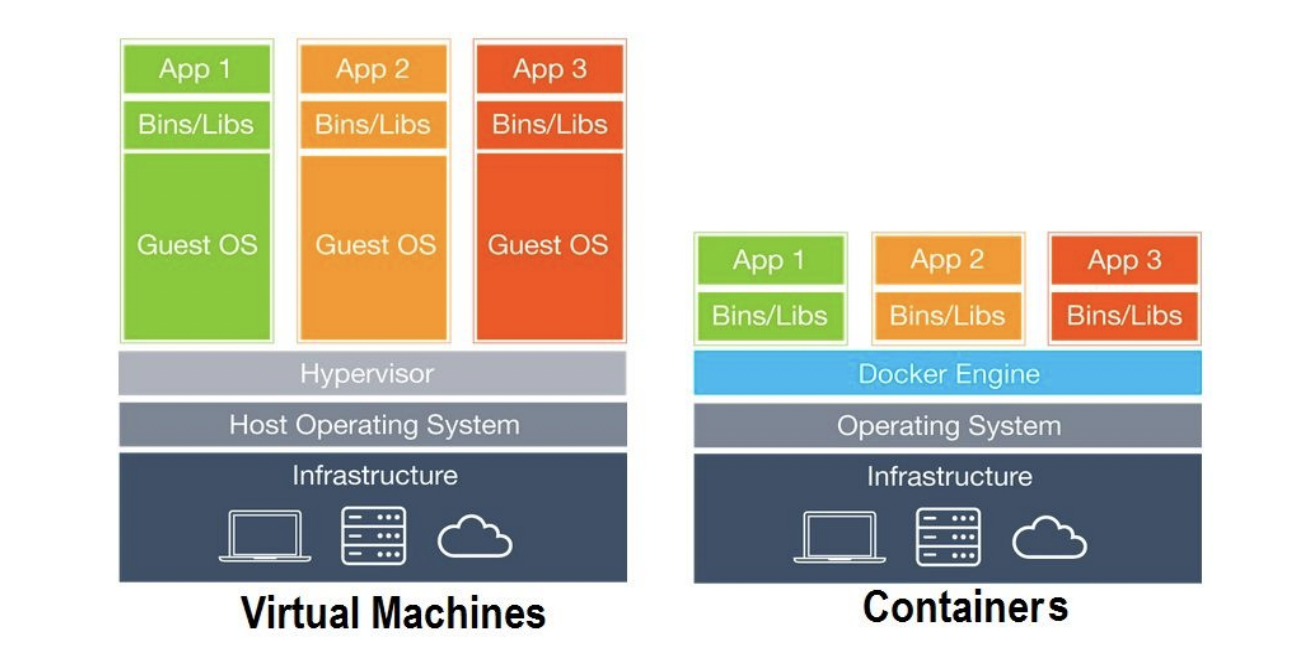
Figure 3: The difference between virtual machines and containers
Since Cassandra is a distributed database, there are multiple modules that can lead to the degradation of performance over time. Virtual Machines (VMs) offer some relief with rapid disaster recovery and automatic backups. VMs are huge files embedded with an operating system, and applications are deployed by a hypervisor running multiple VMs on a single physical server. They replicate the environment of a physical computer and provide all the functionality of a computer.
However, in each VM, there’s a huge operating system which can take up massive space in a central processing unit (CPU), including all the resources required to run an application and RAM.
This is where containers come into play. Containers are Linux processes that are packed with all their dependencies into portable “images,” so applications can run quickly and reliably from one computing environment to another. A typical Docker system includes:
- A docker daemon that manages containers
- A docker daemon provides a REST API that specifies program interfaces
- A command line interface (CLI) client to send commands back to the Docker Daemon
When you type commands using the client, they are sent through the REST API to the engine and the engine starts, stops or interacts with running containers.
Running a Docker container
A Docker container lifecycle consists of immutable, static images like a template. Once you’re happy with an application you built, you can take a snapshot of the environments and create a Docker image using a Dockerfile. You can then push the image to a registry or pull it locally to start an environment based on the image. Ultimately, you can create a container based on the Docker image by executing docker run. Visit Datastax’s Docker Fundamentals workshop to learn more about this process.
Cassandra developers created a Cassandra Docker image, a read-only file, which is pushed to the Docker registry, available for the public to download and configure based on the requirements from the image. Once Cassandra is downloaded from the Docker image, you can configure the image by using a set of parameters. See how to configure a Docker image in this video.
To run multi-container applications, you can use Docker Compose which deploys a YAML file to configure the applications. Docker Compose is appealing for Cassandra since it can use the Docker image from Cassandra and provide the proper parameters.
But Docker Compose isn’t enough to orchestrate the containers to recover or scale a single node on Cassandra. In this case, a container orchestration platform like Kubernetes becomes imperative.
Why Kubernetes?
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications. Kubernetes works virtually with different containers, underlying infrastructures, and multi-cloud capabilities. When you deploy Cassandra on a container where you have a very thin layer of Linux, Kubernetes can help you easily and efficiently manage these containers.
The key differentiating features of Kubernetes include:
- Storage orchestration
- Batch execution
- Horizontal scaling
- Self-healing
- Automatic bin packing
- Secret and configuration management
- Automated rollouts and rollbacks
- Service discovery and load balancing
Kubernetes infrastructure
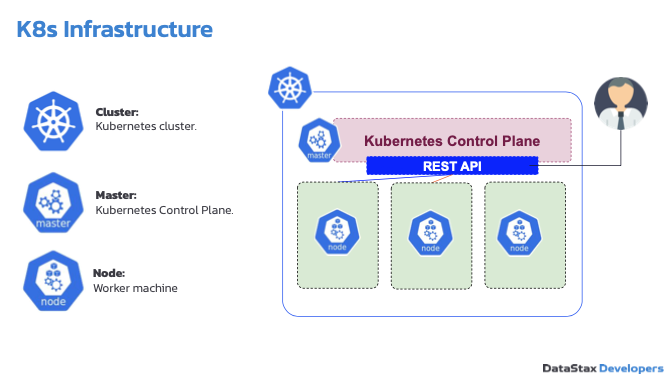
Figure 4: Kubernetes infrastructure
Kubernetes is a distributed system like Cassandra, but while Cassandra is masterless, Kubernetes contains a master called Kubernetes Control Plane which can be replicated in a cluster for resilience reasons. Figure 5 illustrates the components of a Kubernetes Control Plane.
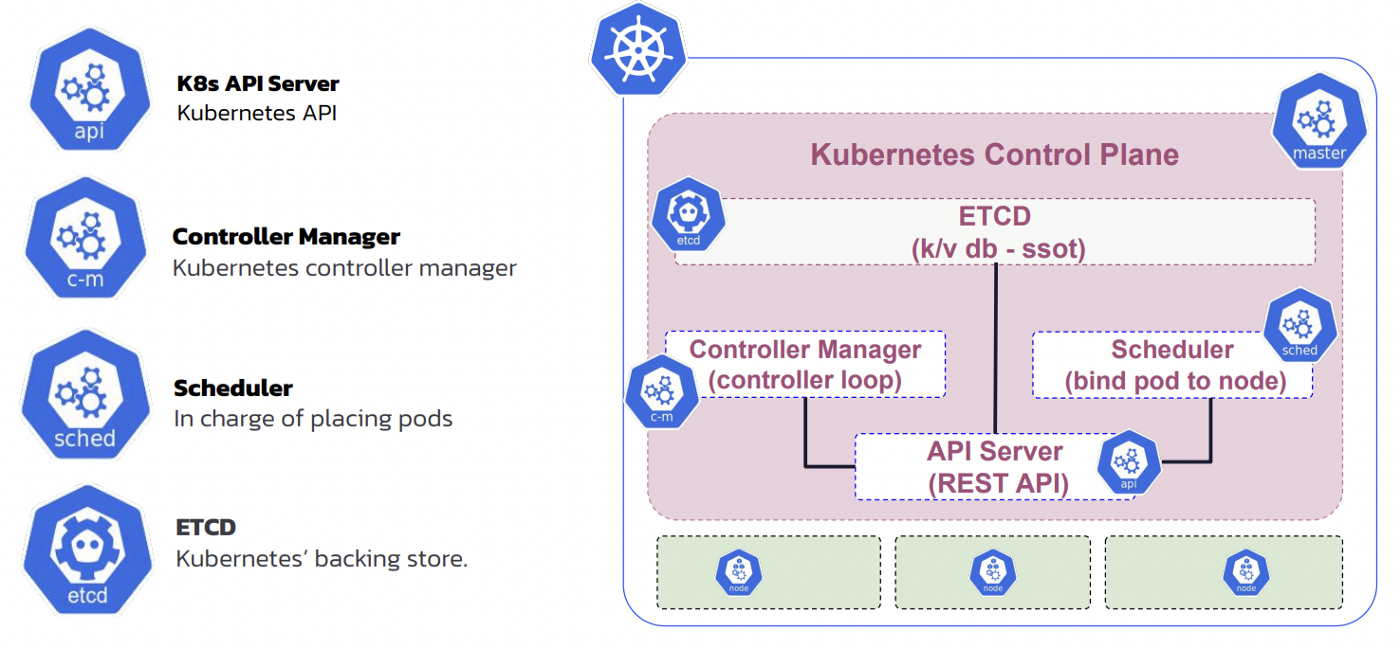
Figure 5: Kubernetes Control Plane
A command line interface (CLI) called kubectl is used to interact and communicate with a Kubernetes cluster. kubectl provides a command which is posted to the REST API of the control plane. When you set up Kubernetes on your machine, you map your kubectl command with an existing, running Kubernetes cluster.
A Kubernetes worker node contains kubelet, kube-proxy, and multiple pods. Inside each pod, you can host a single or multiple containers. Pods and containers work together to scale simultaneously.
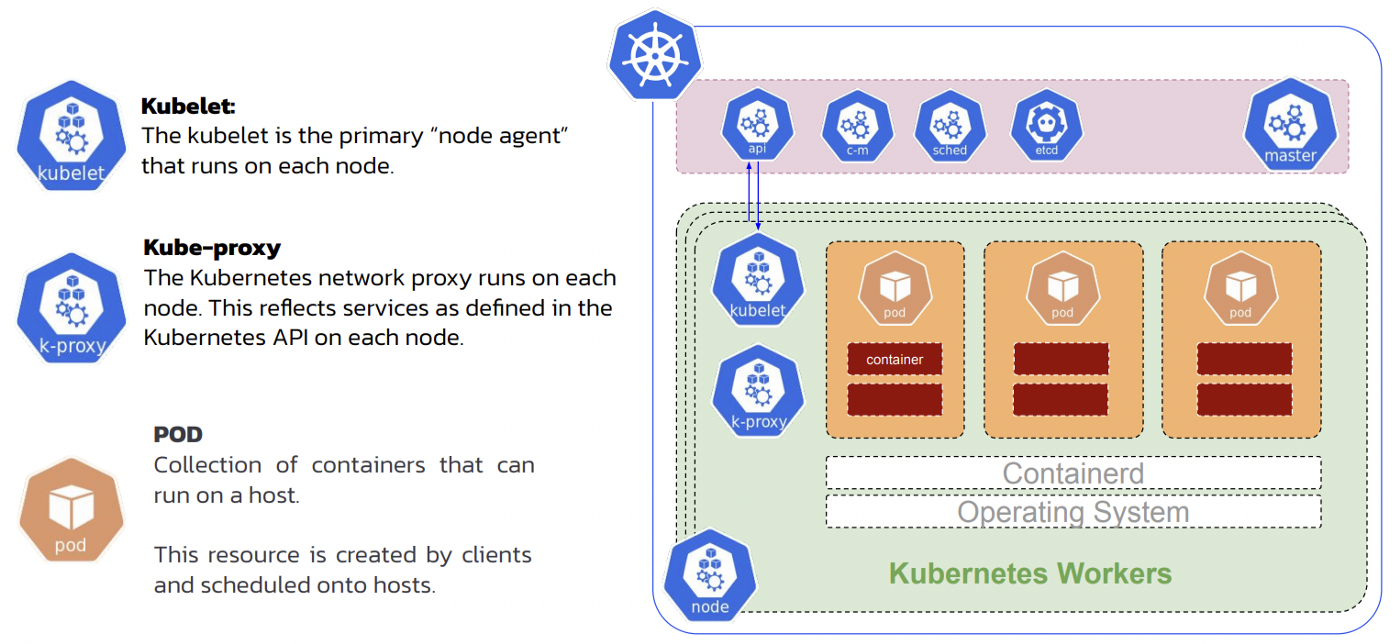
Figure 6: Kubernetes Worker Node
Kubernetes resources
Everything created in Kubernetes is called a resource, and there are multiple types of resources, such as:
- Namespace: A way to isolate a bunch of resource components inside the same name. When you build an application that requires several pods, you can put them under the same namespace so you can interact with them using a single namespace and run group operations.
- Storage: Different applications have different forms of storage needs and Kubernetes offer some tools to configure your storage to serve your needs:
- PersistentVolume: A storage resource provisioned by an administrator or dynamic provisioner.
- PersistentVolumeClaim: A request for
PersistentVolume. Similar to a pod that requests specific resources from a node, this claims requests for a specific size from a PV resource. - StorageClass: Describes the parameters for a class of storage for which PersistentVolumes can be dynamically provisioned.
- Statefulset: A set of pods with consistent identities. A dynamic PV is provided when a
statefulsetis initiated. If a Cassandra node goes down and you want to replace it, StatefulSets can point it to the same storage volume where the previous data files were stored. - Custom resources: Extensions of the Kubernetes APIs. While a resource in Kubernetes stores API objects, a custom resource stores customized API objects. Custom resource definitions (CRDs) extend Kubernetes’ capabilities by adding a custom API object useful for integrating Cassandra. Examples include CassandraDataCenter (cass-operator), CassandraBackup, and CassandraRestore.
- Operator: A type of component with resources in Kubernetes to support the default controller that monitors events, acts on it, and changes the status of a CRD.
For example, suppose an application requires an operator. In that case, you will need to define and configure the operator or instances running in the operator, subsequently define and start a CRD. Then step-by-step, the operator will respond, which initiates the other components in the application.
The Datastax Kubernetes operator for Cassandra is also known as cass-operator, which automates the process of managing Cassandra in a Kubernetes cluster. Cass-operator extracts data, including the nodes and cluster names, to manage individual Kubernetes resources.
It also monitors Cassandra clusters against discrepancies and with simple configurations using YAML. Cassandra can fully optimize Kubernetes orchestration. Cass-operator also helps store data in a rack, scales racks evenly with new nodes, and replaces unrecoverable nodes. Watch this tutorial about cass-operator to learn more.
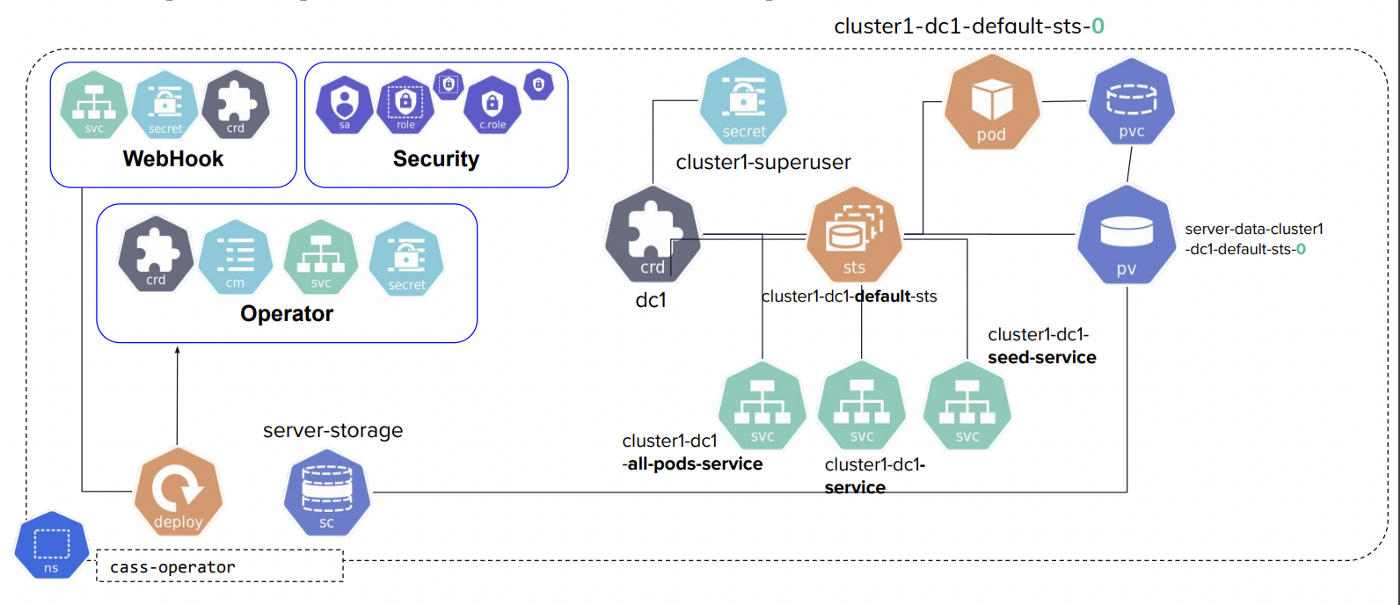
Figure 7: Sample deployment with Cass-operator
But fitting Cassandra’s distributed system into Kubernetes can be time-consuming and challenging. You need to consider two factors:
- Normal Kubernetes deployment procedures, such as setting up networking and storage, creating multiple Cassandra Pods, configuring backups and repairs, connecting your applications, configuring seed nodes, TLS certificates, and so much more.
- Best practices for the cass-operator.
Fortunately, K8ssandra, the open-source community tool, handles everything for you through Helm charts and the Helm package manager.
Introducing K8ssandra
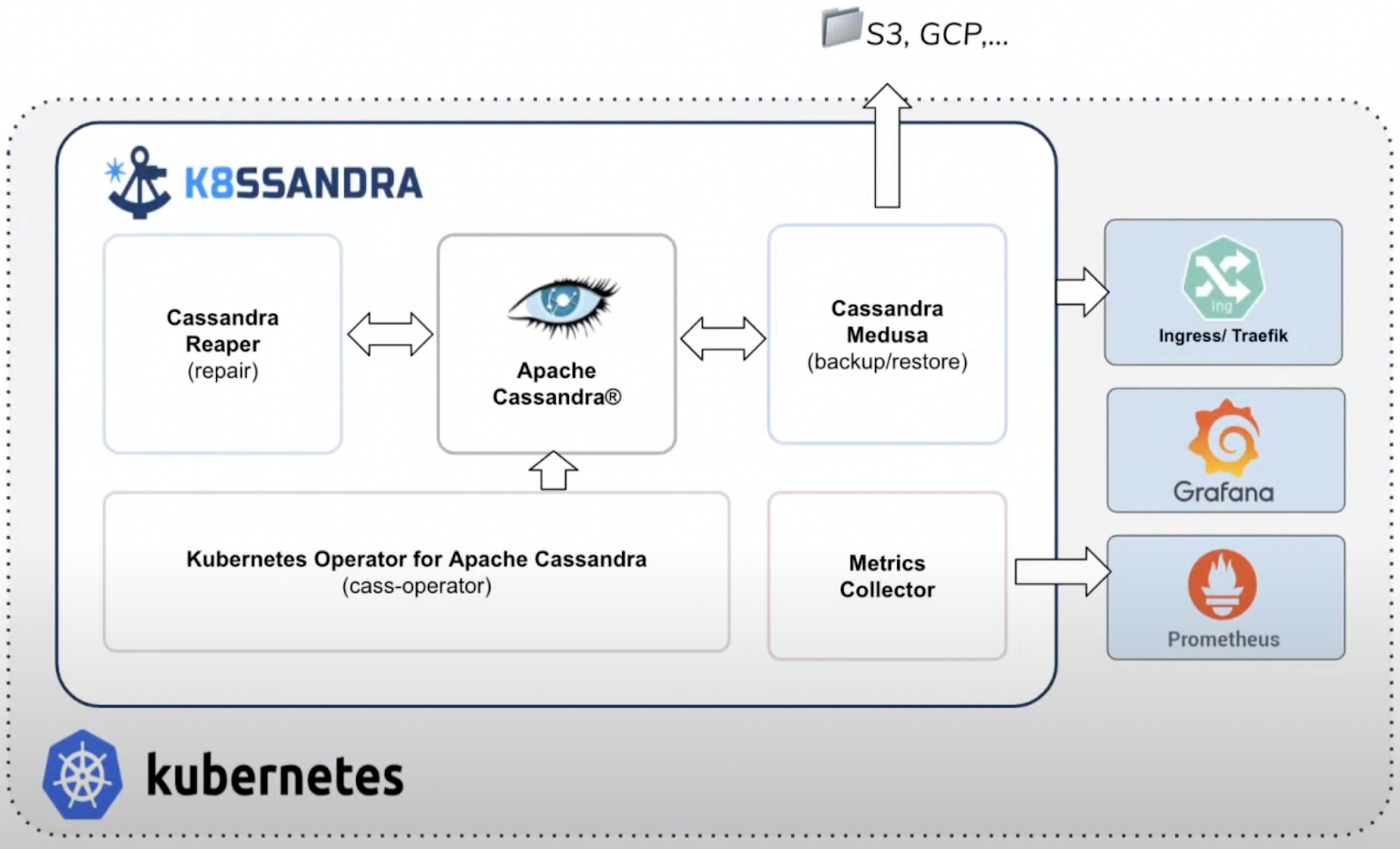
Figure 8: K8ssandra infrastructure
K8ssandra is an open-source, cloud-native, production-ready platform for deploying Cassandra and required tooling on Kubernetes. Apart from managing the database, it also supports the infrastructure for monitoring and optimizing data management. K8ssandra offers an ecosystem of tools to provide richer data APIs and automated operations alongside Cassandra, such as:
- Cassandra Reaper: An open-source tool used to schedule and orchestrate automatic repairs of Cassandra clusters.
- Cassandra Medusa: A command line tool that provides back and restores functions.
- HELM: A Kubernetes deployment tool or a package manager for automating, packaging and configuring applications to the Kubernetes cluster.
- Prometheus and Grafana: Used for storage and visualization of metrics related to Cassandra. While Grafana’s pre-configured dashboards enable observability, Prometheus is pre-built and collects metrics.
- Traefik: Kubernetes ingress for external access.
- Stargate: Data Gateway providing REST, GraphQL, gRPC, Document APIs.
All the components are installed and wired together as part of K8ssandra’s installation process, freeing you from performing the tedious plumbing of components. K8ssandra developers follow the principle “batteries are included but swappable,” so you can switch off components you don’t need or “bring your own” Grafana with you instead of using the bundled one.
Hands-on K8ssandra workshop
Now that you’re familiar with the ins and outs of deploying Cassandra on Kubernetes through K8ssandra, let’s put it into practice. In this YouTube workshop, we gave you two options to get started: local setup or our cloud instance. But, since the cloud instances were terminated after the workshop, you’ll need to use your own computer or cloud node. Make sure you have a Docker-ready machine with at least a 4-core + 8 GB RAM.
Install the required tools to set up K8ssandra on your computer and click on each of the links below to get started.
- Setting up Cassandra
- Monitoring Cassandra
- Working with data
- Scaling your Cassandra cluster up and down
- API access with Stargate
- Running repairs
Conclusion
In this post, we gave you an in-depth explanation and a hands-on experience of deploying Cassandra on Kubernetes with K8ssandra and its developer-friendly tools, such as Prometheus, Grafana, and Helm.
For more workshops on Cassandra, check out the DataStax Devs YouTube channel.
Follow the DataStax Tech Blog for more developer stories and follow DataStax Developers on Twitter for the latest news about our developer community.
Resources
- Introduction to Apache Cassandra - the “Lamborghini” of the NoSQL World
- Kubernetes
- Cass Operator | DataStax Documentation
- What is a Kubernetes Operator?
- Run Apache Cassandra | DataStax blog
- Blog: Kubernetes Data Simplicity: Getting started with K8ssandra| DataStax blog
- Why K8ssandra?
- Stargate
- Cassandra Reaper
- YAML Basics
- Grafana
- Helm
- Docker Compose
More Technology
View All
Introducing the DataStax AI Terraform Module


