Designing a Future-Proof Data Architecture Part 2

DataStax

This is an excerpt from the DataStax whitepaper Moving to a Modern Architecture, which delves into the eight key ways to prepare for and manage a modern data architecture. Click here to download the full whitepaper.
What does a data architecture that can withstand nearly anything thrown at it—both now and in the future—look like?
Without a doubt, that’s a rather foggy crystal ball to gaze into, but there is a way to bring things more clearly into focus. By reviewing the most often cited modern application data needs and issues that typically cause IT architectures to buckle and collapse, you can design a data blueprint that can hold up even under the nastiest of weather.
Let’s start with some of the most common requirements and then go into others that have more recently come about with the current evolution of database systems, digital applications, and their radically distributed deployments.
Multi-Model
Microservices architectures are the soup du jour today where developing modern applications are concerned.
The idea is to stitch together components that roll up to the big picture application in a way that allows development teams to more easily work in parallel and thus get things to market more quickly. Key to the success of microservices is strong flexibility at the data layer, which accommodates the concept of polyglot persistence in a more modern way than previous implementations.
In the past, polyglot persistence implied that customers would use either a limited set of data models (key-value, tabular, JSON, relational, graph) or perform extract-transform-load (ETL) operations across data stores. Use cases such as master data management, customer-360-view, and others, mandated the latter approach, which increased complexity and total cost of ownership (TCO) because multiple vendors and cost models were involved.
Development was difficult because each vendor’s mechanism for interacting with the data store was different, both with respect to its dialect and where they lay on the logical / physical design divide. This forced application developers to write abstraction layers if they needed more than a single model in their application. Further, these abstraction layers had to work at very different levels across the physical / logical spectrum to keep application development aligned.
A multi-model database approach represents the next phase of maturity for our database industry and addresses these hurdles, especially as it relates to mainstream developers and administrators within the enterprise. This is accomplished with a single, integrated backend that:
- Supports multiple data models (e.g., tabular, JSON, graph) at a logical layer for ease of development for application developers
- Ensures all models are exposed via cohesive mechanisms, thereby avoiding cognitive context switching for developers
- Provides a unified persistence layer that delivers geo-redundant, always-on characteristics and a common framework for operational aspects such as security, provisioning, disaster recovery, etc.
- Empowers a variety of use cases across OLTP and OLAP workloads for lines of businesses within an enterprise to innovate with agility
- Delivers best-in-class TCO efficiency for the long haul to enable wider adoption within centralized IT teams of an organization
TIP: Ensure your data platform supports true multi-model capabilities versus a surface-level implementation of data store support. As an example, a number of relational and NoSQL vendors offer graph functions in their core model, which fall light-years short of a true graph database.
Cloud Native
You can park a car in a lot full of boats, but doing so doesn’t make the car a boat.
All relational database management system (RDBMS) vendors offer a version of their database in the cloud, however, that doesn’t make them cloud databases. The saying, “There is no cloud; it’s just someone else’s computer,” applies to databases as well. There is no cloud pixie dust that auto-magically takes legacy relational databases or certain NoSQL databases and transforms them into a native cloud database that exploits all the benefits that cloud offers.
Why care about this? Because your future-proof data architecture will almost certainly use cloud in some way. In their “The Future of the DBMS Market Is Cloud” report, Gartner states, “Database management system deployments and innovations are increasingly cloud-first or cloud-only. Data and analytics leaders selecting DBMS solutions must accept that cloud DBMS is the future and must plan for shifting spending, staffing and development accordingly.”
So how does a native cloud database behave versus the pretenders? A short list of the characteristics include:
- Transparent elasticity—being able to easily expand and contract resources given usage and resource demands.
- Unbounded scalability—one TB or PB, one thousand users or ten million, the cloud database elasticity should include seamless scalability (and make no mistake, the two are not synonymous).
- Built-in redundancy—the database should be able to fully exploit different regions, availability zones, and (yes!) different clouds to guarantee zero downtime and no loss of data access.
- Simplified data distribution—same as location independence described above.
- Autonomous manageability—the typical administrator tasks of backup, provisioning, tuning, etc., should be handled in a hands-free way.
- Uniform security—data protection should be applied in a consistent manner across workloads, data models, other clouds, and on-premises participants in the deployments.
TIP: The underlying data architecture’s foundation is absolutely key here—a masterless, shared-nothing design will allow for all of the above requirements to be fulfilled either within the database itself or via simple integration with the cloud platform vendors.
Winnowing the Field
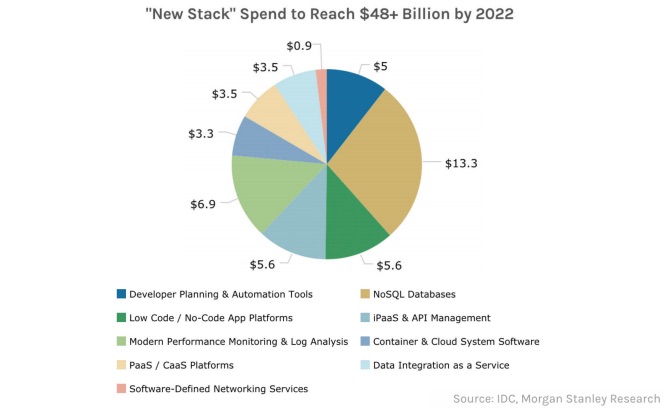
There’s no doubt that the requirements we’ve covered for a future-proof data architecture are tough, but c’mon, you didn’t think this would be easy did you? So what will step up to the challenge? Traditional relational databases are good for centralized and legacy applications (e.g., ERP) but aren’t really a fit for widely distributed digital applications. Instead, you need something that’s a little different than your grandfather’s database. In a recent report, analysts at Morgan Stanley assert that the “new stack” needed for modern applications consists of:
- Developer planning and automation tools
- NoSQL databases
- Low code / no-code app platforms
- iPaaS and API management
- Modern performance monitoring and log analysis
- Container and cloud system software
- PaaS / CaaS platforms
- Data integration as a service
- Software-defined networking services
Their prediction for the modern data architecture layer is NoSQL, with their forecast being that it will attract the most new dollars spent:
However, just because a database platform is nonrelational in nature, doesn’t mean that it will be able to support the requirements needed for a true futureproof data architecture. As an example, most NoSQL databases mimic the master-slave design of relational databases.
Summing Things Up
So what does a data architecture that can withstand nearly anything thrown at it, both now and in the future, look like? It’s one that:
- Doesn’t hit the wall when the data volumes and user traffic swell to extremely high levels. Stays online come hell or high water.
- Offers location independence, allowing you to read and write data anywhere in the world.
- Supports contextual transaction processing so that various workloads—standard transactions, analytics, search—can all be supported within the context of a single interaction.
- Has not only multi-workload functionality, but multi-model support as well, which helps streamline microservices development.
- Is cloud native in the sense that it seamlessly takes advantage of all the cloud’s benefits, while sporting security uniformity across the platform and allowing for the ultimate in deployment flexibility (on-premises, single cloud, multi-cloud, hybrid cloud).
If you’re looking for more details on how to actually implement a future-proof data architecture, please give our experts at DataStax a shout (datastax.com/contactus) and they’ll be happy to show you how it’s done.
Thanks for reading this excerpt from the DataStax whitepaper Moving to a Modern Architecture, tune in next week when we'll release another excerpt or click here to download the full asset.
More Technology
View All
Introducing the DataStax AI Terraform Module


