DSE 5.1 Resource Manager Part 2 – Process Security

Jacek Lewandowski

Recap from part 1 of this post - DSE Resource Manager is a custom version of Spark Standalone cluster manager. In the first part of this post we explained how the network security was improved in DSE 5.1 for Apache Spark™ applications. Here we will show how the executor processes are started and what we improved in DSE 5.1 in terms of security and processes separation.
DSE Resource Manager comes with a customizable implementation of the mechanism used to control the driver and executor lifecycles. In particular we provide an alternative to the default mechanism which allows processes to be run as separate system users. Follow this blog post to learn how this impacts the security of your DSE cluster, how it can be configured and how you can verify what it actually does. We will also show a step-by-step guide to demonstrate how it works.
OSS Spark Standalone Master - prior to DSE 5.1
Spark executors (and drivers when deployed in the cluster mode) are run on DSE nodes. By default these processes are started by DSE server and are run by the same OS user who runs DSE server. This obviously has some security implications - we need to fully trust the applications which are run on the cluster because they can access DSE data and configuration files. The applications can also access files of each others.

Fig. 1 - Running executors and drivers in OSS Spark Deployment (DSE 5.0 and older)
All processes are run as the same system user thus all of them have the same permissions
DSE 5.1 introduces a new feature which allows to delegate running Spark application components to a runner which can be chosen in DSE configuration, in dse.yaml. The legacy behaviour is now implemented as a “default” runner.
“RunAs” runner
DSE 5.1 brings also the run_as runner which allows to run Spark applications on behalf of a given OS user. Basically the system user, dse, cassandra, or whoever runs DSE server is not used to run users’ applications. Additionally applications of different DSE users are run as different system users on the host machine. That is:
- all the simultaneously running applications deployed by a single DSE user will be run as a single OS user
- applications deployed by different DSE users will be run by different OS users
- the DSE user will not be used to run applications
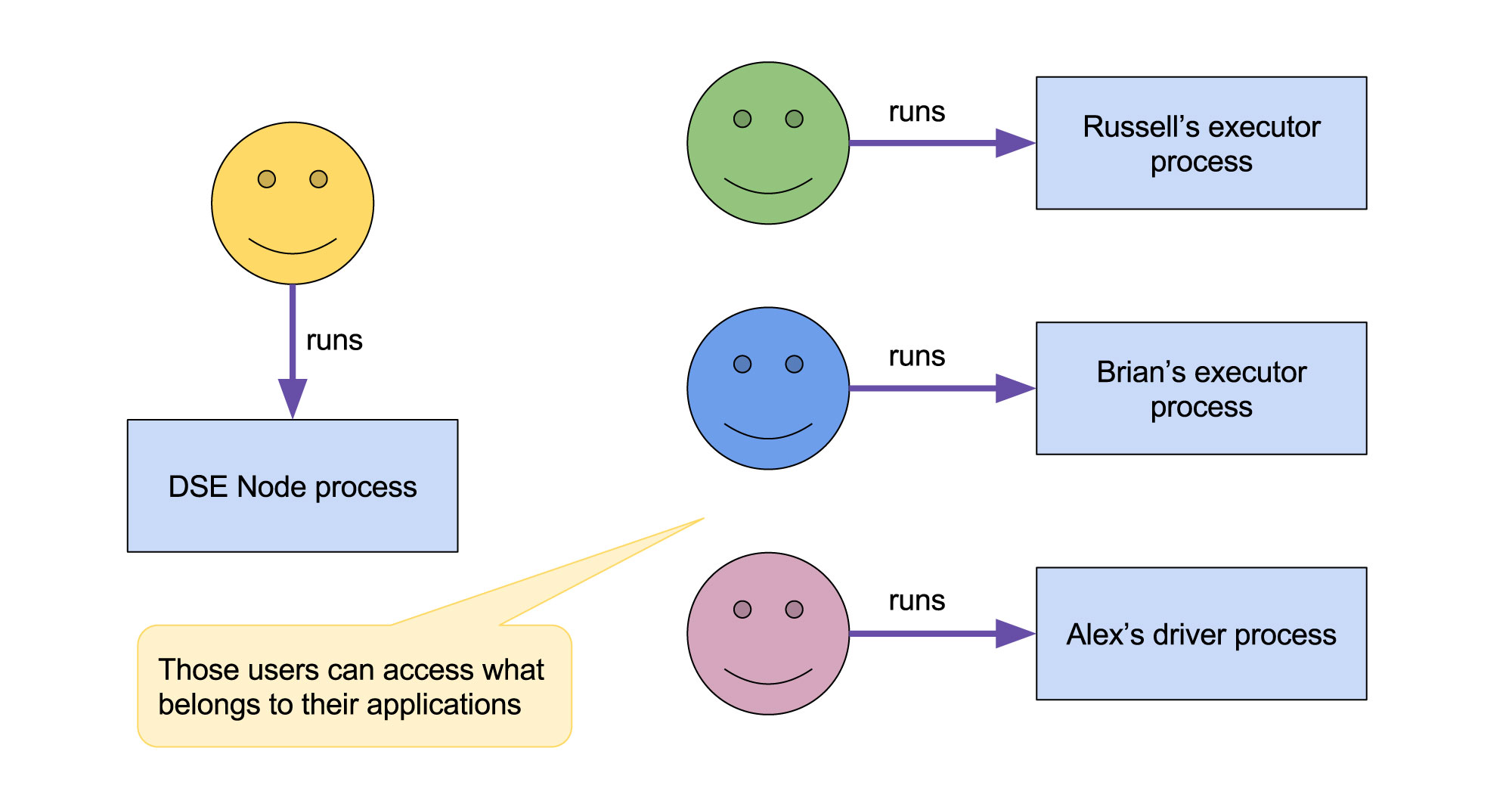

Fig. 2 - Running executors and drivers with RunAs runner / DSE Resource Manager (DSE 5.1)
DSE node process and processes belonging to different DSE users are run as different OS users thus they may have different permissions
The above assumptions allows implementing security rules which protect DSE server private files and prevent accessing private files of other applications.
Mechanism
DSE leverages the sudo program to run Spark application components (driver, executors) as specific OS users. Unlike Hadoop/Yarn resource managers, DSE does not link a DSE user to a particular OS user. Instead, a certain number of spare user accounts (slots) are used. When a request to run an executor or a driver is received by DSE server, it looks up an unused slot, and locks it for that application. Until the application is finished, all of its processes will be run as that slot user. Then, the slot user will be released and can be used by another application.
Since the number of slots is limited, a single slot is shared among all the simultaneously running applications run by the same DSE user. Such a slot is released once all the applications of that user are removed. When there are not enough slots to run an application, there will be error reported and DSE will try to run the executor or driver on a different node. DSE does not limit the number of slots you can configure so, if you need to run more applications simultaneously, simply create more slots. The most reasonable default is the number of cores available to the Spark Worker on that DSE node because there will never be more distinct executors running simultaneously than the number of available cores (each executor uses at least one core).
Slot assignment is done on per node basis, that is the executors of one application may run on different slots on different DSE nodes. An even more important implication is that when DSE is run on a fat node, different DSE instances running within the same OS should be configured with a disjoint sets of slot users. Otherwise, it may end up with a single OS user running applications of two different DSE users.

Fig. 3 - Slot assignment on different nodes
Each DSE instance manages slot users independently. Make sure that if you run multiple DSE instances in a single OS they should use different slot users
Cleanup procedure
RunAs runner cleans up those files which are created in default locations such as the RDD cache files and the content of executor and driver work directories.
A slot user is used to run executors and drivers of one DSE user at one time. When the slot is released, it can be used by a different DSE user. Therefore we have to make sure that some files created by applications on each worker node are handled properly, in particular:
- When the slot is released, those files will not be accessible to newly started applications which will be run as the same slot user
- When we run executors or a driver of the application again on the same worker node (after the slot was previously released), the application files will be accessible again to that application
The runner we implemented does not follow what files are created by the application but there are two locations common to each Spark applications which we can control:
- Application work directory - it is created under Spark worker directory, which is defined in /etc/dse/spark/spark-env.sh as SPARK_WORKER_DIR and by default it is set to /var/lib/spark/worker. There is a subdirectory for each application, and then a subdirectory for each executor. For example, in those directories executor standard out and standard err streams are saved.
- RDD cache location - the location of cache is also defined in /etc/dse/spark/spark-env.sh as SPARK_LOCAL_DIRS and by default it is set to /var/lib/spark/rdd. There are subdirectories with randomly generated names which are created by executor and driver processes.
To ensure the aforementioned security requirements against the above locations the runner changes ownership and permissions of these locations in runtime. In particular, when a slot is released (the last process running on the slot has finished) the runner changes the ownership of the application directories and their content from the slot user to DSE service user so that no slot user cannot access them. On the other hand, when executors of the application are about to be run again on a worker node, the ownership of the application directories and their content is changed back to the slot user which is newly assigned to that application.
There is one more detail in this regard - what will happen if the worker is killed or the node dies suddenly and the runner is unable to perform cleanup? This problem is fixed in the way that when the worker starts, the first thing it does is to change the ownership of all remaining application directories to DSE service user. When executors of some application are run again on this worker node, they will follow the scenario described above and the application directories will be made accessible to those executors.
Note that if your application creates files somewhere else, you need to clean up those files on your own.
Configuration
In order to start working with run_as runner, the administrator needs to prepare slot users in the OS. run_as runner assumes that:
- each slot user has its own primary group, whose name is the same as the name of slot user (usually a default behaviour of the OS)
- DSE service user (the one as who DSE server is run) is a member of each slot's primary group
- sudo is configured so that DSE service user can execute any command as any slot user without providing a password
We also suggest to override umask to 007 for slot users so that files created by sub-processes will not be accessible by anyone else by default, as well as make sure DSE configuration files are not visible to slot users. One more step to secure DSE server environment can be modifying limits.conf file in order to impose exact disk space quota per slot user.
The only settings which the administrator needs to provide in DSE configuration is a selection of run_as runner and a list of slot users to be used on a node. Those settings are located in dse.yaml, in spark_process_runner section.
Example configuration - configure run_as runner with two slot users: slot1 and slot2
- Create 2 users called slot1, slot2 with no login; each such user should have primary group the same as its name: slot1:slot1, slot2:slot2
$ sudo useradd --user-group --shell /bin/false --no-create-home slot1
$ sudo useradd --user-group --shell /bin/false --no-create-home slot2
- Add DSE service user (the one as who DSE server is run) to the slot user groups - DSE service user has to be in all slot user groups
You can find the DSE service user name by looking into /etc/init.d/dse - there is the entry which define DSE service user, for example (let it be cassandra in our case):
CASSANDRA_USER="cassandra"
Then, add that user to each slot user primary group:
$ sudo usermod --append --groups slot1,slot2 cassandra
By invoking the following command you can verify group assignment:
$ id cassandra
uid=107(cassandra) gid=112(cassandra) groups=112(cassandra),1003(slot1),1004(slot2)
- Modify /etc/sudoers file by adding the following lines (remember to use visudo to edit this file):
Runas_Alias SLOTS = slot1, slot2 Defaults>SLOTS umask=007 Defaults>SLOTS umask_override cassandra ALL=(SLOTS) NOPASSWD: ALL
- Modify dse.yaml so that:
spark_process_runner: runner_type: run_as run_as_runner_options: user_slots: - slot1 - slot2
The above settings configure DSE to use run_as runner with two slot users: slot1 and slot2.
- Do those changes on all the nodes in data center where you want to use run_as runner. After applying the configuration restart all the nodes.
Next, given our workers have at least 2 cores available, we will run two applications but two different users so that a single worker will simultaneously run executors of both applications.
- Start two applications in separate consoles
$ DSE_USERNAME=john DSE_PASSWORD=password dse spark --total-executor-cores 3 --master dse://?connection.local_dc=DC1
$ DSE_USERNAME=anna DSE_PASSWORD=password dse spark --total-executor-cores 3 --master dse://?connection.local_dc=DC1
Go to the Spark Master UI page and you will see that both application are registered and running. Then go to Spark Worker UI of one of the workers and verify that the worker is running executors of both applications. To see which slot users are used, execute the following statement in each shell:
scala> sc.makeRDD(1 to 3, 3).map(x => s"${org.apache.spark.SparkEnv.get.executorId} - ${sys.props("user.name")}").collect().foreach(println)
The command runs a simple transformation of a 3-element collection. Each partition will be processed as a separate task - if there are 3 executors with 1 core assigned, each element of the collection will be processed by a different executor. We will get the value of system property “user.name” from each executor JVM. You will notice that one shell will report different slot user for the same executor ID than the other shell which means that both executors are run by different OS user.
You may also have a look at the directories created for each application and executor:
$ sudo ls -lR /var/lib/spark/worker
Example output of this command:
./app-20170424121437-0000: total 4 drwxrwx--- 2 cassandra slot1 4096 Apr 24 12:14 0 ./app-20170424121437-0000/0: total 12 -rw-rw---- 1 cassandra slot1 0 Apr 24 12:14 stderr -rw-rw---- 1 cassandra slot1 10241 Apr 24 12:16 stdout ./app-20170424121446-0001: total 4 drwxrwx--- 2 cassandra slot2 4096 Apr 24 12:14 0 ./app-20170424121446-0001/0: total 8 -rw-rw---- 1 cassandra slot2 0 Apr 24 12:14 stderr -rw-rw---- 1 cassandra slot2 7037 Apr 24 12:22 stdout
Similarly, when you list /var/lib/spark/rdd you will see that directories used by different applications have different owners.
Refer to the DSE Analytics documentation to get more detailed information about DSE Resource Manager. Stay tuned for more posts related to DSE Resource Manager where we are going to cover running Spark applications high availability troubleshooting.
More Technology
View All
Introducing the DataStax AI Terraform Module


