DSE Continuous Paging Tuning and Support Guide

Russell Spitzer

Introduction
Continuous paging (CP) is a new method of streaming bulk amounts of records from Datastax Enterprise to the Datastax Java Driver. This is disabled by default and can be activated and used only when running with DataStax Enterprise (DSE) 5.1. When activated, all read operations executed from the CassandraTableScanRDD will use continuous paging. Continuous Paging is an Opt-In feature and can be enabled by setting "spark.dse.continuous_paging_enabled" to true as a Spark configuration option. The configuration can be set in:
- the spark-defaults filespark.dse.continuous_paging_enabled true
- on the command line using--conf spark.dse.continuous_paging_enabled=true
- or programmatically inside your application using the SparkConf
conf.set("spark.dse.continuous_paging_enabled","true")
Continuous Paging cannot be enabled or disabled once the Spark Context has been created.
When to enable Continuous Paging?
Any operation that has reading from Apache Cassandra® as it's bottleneck will benefit from continuous paging. This will use considerably more Cassandra resources when running so it may not be best for all use-cases. While this feature is Opt-In in 5.1.0 it may become on by default in future DSE Releases.
How it works
Continuous paging increases read speed by having the server continuously prepare new result pages in response to a query. This means there is no cycle of communication between the DSE Server and DSE Java Driver. The reading machinery inside of DSE can operate continuously without having to constantly be restarted by the client like in normal paging. The DSE Java Driver Sessions start these ContinuousPaging requests using the executeContinuously method. The Spark Cassandra Connector implements a custom Scanner class in the DseCassandraConnectionFactory which overrides the default table scan behavior of the OSS Connector and uses the executeContinuously method. (Continuous Paging cannot be used with DSE Search and will be automatically disabled if a Search query is used) Because this is integrated into DSE Server and the DSECassandraConnectionFactory there is no way to use ContinuousPaging without using DSE.
When running, the Continuous Paging session will operate separately from the session automatically created by the Spark Cassandra Connector so there will be no conflict between and Continuous Paging and non-Continuous paging queries/writes. A cache is utilized so there will never be more than one CP Session per executor core in use.
How to determine if CP is being used
CP will be automatically disabled if the target of the Spark Application is not DSE or is not CP capable. If this happens it will be logged within the DseCassandraConnectionFactory object. To see this, add the following line to your logback-spark and logback-spark-executor xml files in the Spark conf directory:
<logger name="com.datastax.bdp.spark.DseCassandraConnectionFactory" level="DEBUG"/> <logger name="com.datastax.bdp.spark.ContinuousPagingScanner" level="DEBUG"/>
The executor logs will then contain messages describing whether or not they are using continuous paging. Executor logs can be found in
/var/lib/spark/work/$app-id/$executor-id/stdout or by navigating to the Executor tab of the Spark Driver UI on port 4040 of the machine running the driver.
Most usages of continuous paging do not require any instantiation on the Spark Driver so there will most likely be no references to the ContinuousPaging code in the Driver logs.
Most Common Pain Points
Most CP errors will manifest themselves as tasks failing in the middle of the Spark job. These failures will be immediately retried and most likely will succeed on a second attempt. This means jobs will not necessarily fail due to these exceptions but they may cause jobs to take longer as some of the tasks need to be redone. The following are some of the possible situations.
Server Side Timeouts (Client isn't reading fast enough)
Since the connector is now constantly serving up pages as quickly as it can, there is a built-in timeout on the server to prevent holding a page indefinitely when the client isn't actually trying to grab the page. This will mostly manifest as an error in your Spark Driver logs saying that the server "Timed out adding page to output queue":
Failed to process multiple pages with error: Timed out adding page to output queue org.apache.cassandra.exceptions.ClientWriteException: Timed out adding page to output queue
The timeout being exceeded is from the cassandra.yaml,
continuous_paging: max_client_wait_time_ms: 20000
The root cause of this timeout is most likely the Spark Executor JVM garbage collecting for a very long period of time. The garbage collection causes execution to pause and the client to not request pages from the Server for a period of time. The Driver UI for the Spark Application contains information about GC in the Spark Stage view. Every task will list the total amount of GC related pauses for the task. If a particular GC exceeds the max_client_wait_time_ms then the Server will throw the above error. Depending on the frequency of GC there are two different mediations.
Sporadic GC
If the GC is sporadic but successful at cleaning out the heap then the JVM is most likely healthy but is producing a lot of short lived objects. Increasing the max_client_wait_time_ms or reducing the executor heap size can reduce this pause time and should be sufficient to avoid the error.
To retain parallelism when shrinking the JVM heap, instead of using one large JVM with multiple threads you can spawn several smaller Executor JVMs on the same machine. This can be specified per Spark Driver application using the spark.executor.cores parameter. This will spawn x executor JVM's per machine where x = total number of cores on worker / spark.executor.cores. Setting this must be done with a corresponding change in spark.executor memory otherwise you will use up all the ram on the first executor JVM. Because of RAM limitations, the number of executor JVMs that will be created is actually
Min( AvailableSparkWorkerCores / spark.executor.cores, AvailableSparkWorkerMemory / spark.executor.memory )
Heavy GC
If the executor is running into a GC death spiral (very very high GC, almost always in GC, never able to actually clean the heap) then the amount of data in a Spark Executor Heap needs to be reduced. This can only be done on an application by application basis but basically means reducing the number of rows or elements in a single Spark partition or reducing cached objects.
For DSE *decreasing* the tuning parameter spark.cassandra.input.split.size_in_mb will reduce the number of CQL partitions in a given Spark partition but this may not be sufficient if more data is added with later operations.
Overloading the heap can also be caused by caching large datasets on the executor, exhausting available ram. To avoid this try using the DISK_ONLY based caching strategies instead of MEMORY_ONLY. See api docs.
Client Side Timeouts
Conversely the client can ask for pages from the Server but the server can be under load and fail to return records in time. This timeout will manifest with the following error message
Lost task 254.0 in stage 0.0 (TID 105, 10.200.156.150): java.io.IOException: Exception during execution of SELECT "store", "order_time", "order_number", "color", "qty", "size" FROM "ks"."tab" WHERE token("store") > ? AND token("store") <= ? ALLOW FILTERING: [ip-10-200-156-150.datastax.lan/10.200.156.150:9042] Timed out waiting for server response
These are caused by the client having to wait more than spark.cassandra.read.timeout_ms before the next page can be returned from the server. The default for this is 2 minutes which means it was a very long delay. This can be caused by a variety of reasons:
- The DSE Node is undergoing Heavy GC
- The node went down after the request (the CPE will need to be restarted on another machine)
- Some other network failure
If the error is due to excessive load on the DSE cluster, there are several knobs for tuning the throughput of each executor in the Spark job. Sometimes running a consistent but slower than max speed can be beneficial.
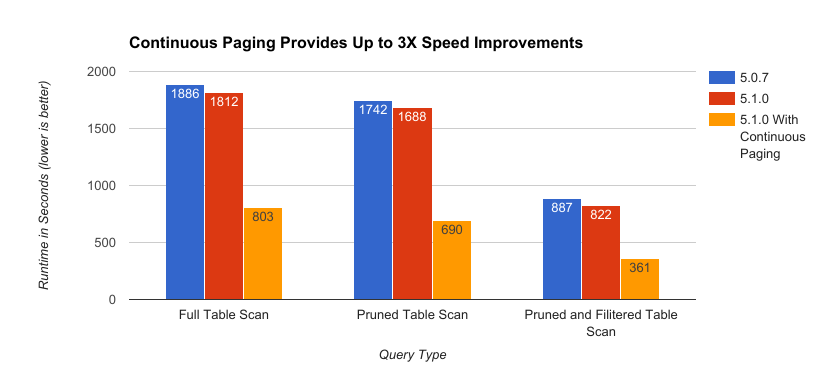
Performance
In most tests we have seen a roughly 2- to 3.5-fold improvement over the normal paging method used by DSE. These gains are made using the default settings but there are two main knobs at the session level for adjusting throughput
- reads_per_sec - MaxPagesPerSecond
- fetch.size_in_rows - PageSize in Rows
They can be set on at the configuration level using
spark.cassandra.input.reads_per_sec spark.cassandra.input.fetch.size_in_rows
or programmatically on a per read basis using the ReadConf object.
The defaults are unlimited pages per second and 1000 rows per page. *Note: These settings are per executor*
Example:
40 Spark Cores 100 Reads per Sec 1000 Rows Per Page 40 Executors * (100 max pages / second * 1000 rows/ page) / Executor = 4000000 Max Rows / Second
Since the max throughput is also limited by the number of Cores, this can also be adjusted to change throughput.
Reading and Writing from Cassandra in the Same Operation
It is important to note that Continuous Paging is only beneficial when reading from Cassandra is the bottleneck in the pipeline. This means that other Spark operations can end up limiting throughput. For example, reading and then writing to Cassandra (sc.cassandraTable().saveToCassandra) can end up limiting the speed of the operation to the write speed of Cassandra. In these cases, continuous paging will provide limited, if any, benefit.
More Technology
View All
Introducing the DataStax AI Terraform Module


