DSE Graph Just Got Faster

Chris SplinterProduct Management

If you want more performant graph traversals, upgrade to DSE 5.1.10 or DSE 6.0.1. In this post, we take a deeper look at the improvement.
A Tale of Traversal Construction
DataStax Enterprise Graph leverages Gremlin, the property graph query language of Apache TinkerPop™, as its core API. DataStax is not only committed to providing the best choice for distributed graph databases, but since the DSE 5.1 release, DataStax has also invested heavily in advancing the Apache TinkerPop™ framework, leading to a lot of great enhancements for graph querying. In this blog post, we will show an example of one of these enhancements that manifests as a 1.5x - 2x+ throughput performance improvement for the Java DSE Graph Fluent API ( analogous to the Bytecode API for those familiar with TinkerPop conventions ).
The Fix
We just made a significant performance improvement to Gremlin traversal construction, that targets TraversalStrategy initialization in the traversals themselves. For some context, all traversals are initialized to include a body of TraversalStrategy instances that will be applied at the time the traversal is iterated. It is through TraversalStrategy application that a Gremlin traversal can be optimized and potentially rewritten to achieve some greater efficiency.
The TraversalStrategy GlobalCache, which holds the common body of TraversalStrategy instances to apply to traversals, is accessed quite frequently during this process and more so for traversals that have a large number of child traversals ( such as g.V().local(outV()) where outV() is the child ). The specific fix ( TINKERPOP-1950 ) introduces a map to this GlobalCache to keep track of the Graph or Graph Computer classes that have already been loaded, removing the somewhat expensive need to reload these classes each time TraversalStrategy.getStrategies is called.
This traversal construction optimization technique benefits both the server and the client. On the DSE server side, it is applied when the traversal is reconstructed and executed. On clients using the Java DSE Graph Fluent API, the fix is applied when the traversal is initially constructed. As stated above, this improvement will be included in DSE versions 5.1.10 and 6.0.1, and in DSE Java Driver 1.6.7.
The Results
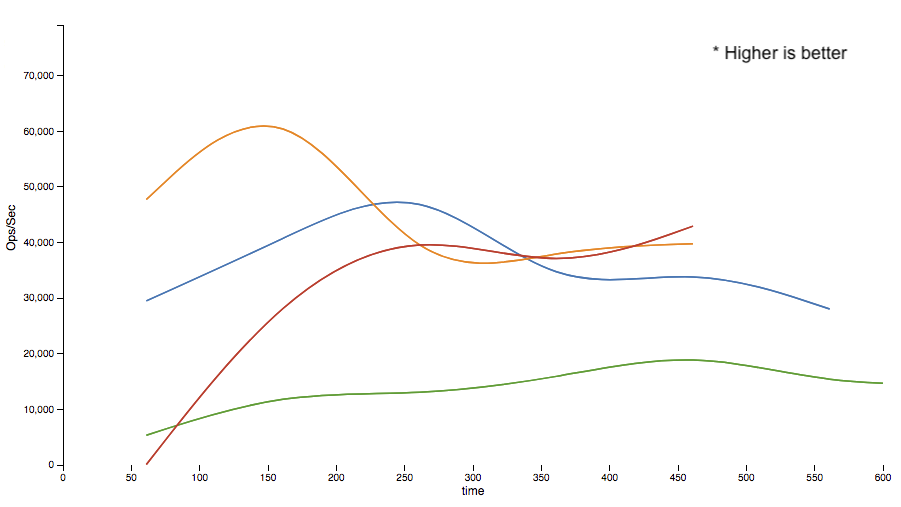
Okay, sounds good, show me the data.
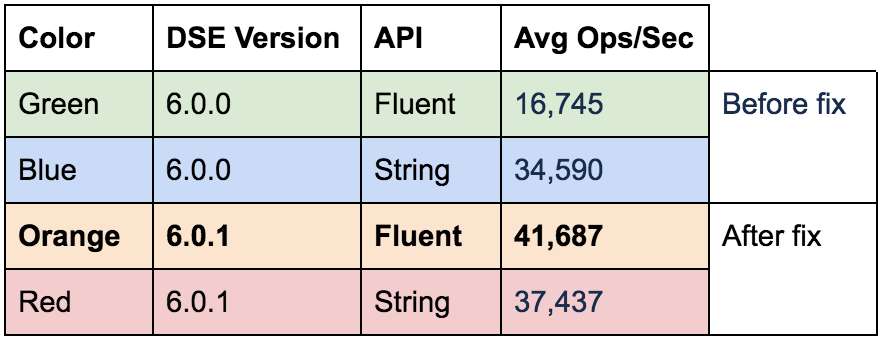
Yes, you are reading that correctly. For this run against DSE 6.0.x, the Java DSE Graph Fluent API throughput increased by more than 2x and the String API also showed a boost. It is expected that both of these would show improvement as we mentioned that this fix benefits both the client and the server.
Now let’s compare how this same test looked against DSE 5.1.x.
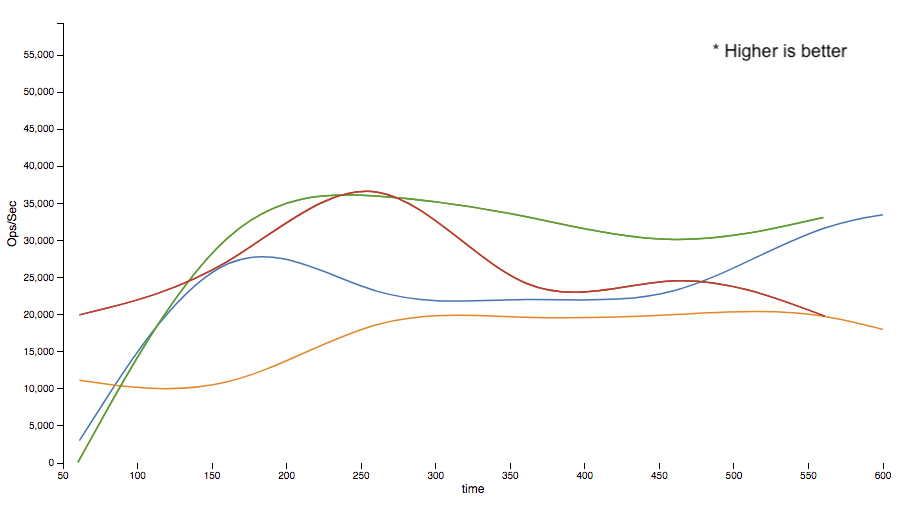
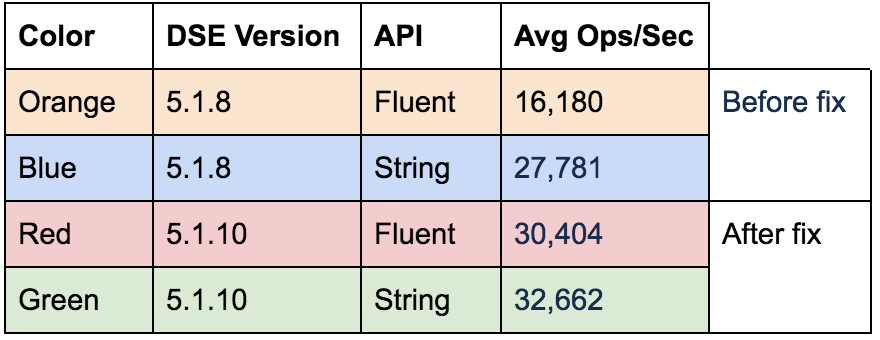
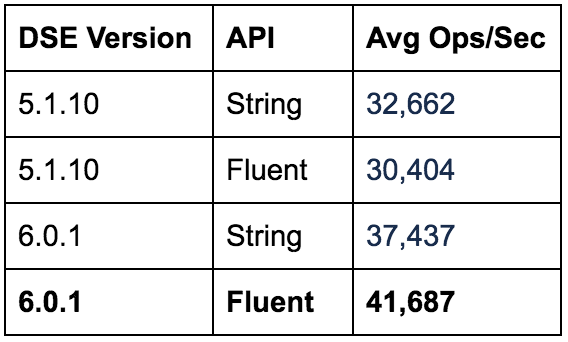
Again, we see a significant increase in throughput for the Java DSE Graph Fluent API, right around 1.7x. The String API throughput also exhibits an increase as shown in the DSE 6.0.x test. Looking at the numbers side by side between the 5.1.x and the 6.0.x runs, we see better throughput overall in the DSE 6.0.x run.
DSE 5.1.10 vs DSE 6.0.1
Test Strategy
As always, we urge you to do your own testing to gauge the impact to your workload as results will vary depending on the traversal and environment.
This test used a 5 node DSE cluster and writes a total of 20 million edges and 40 million vertices using 100 concurrent operators. The DSE nodes were running on machines with 2 CPU with 12 cores each. Hyperthreading is enabled, resulting in 48 HT cores. The instances have 128 GB RAM. They can store up to 2 TB of data, using 2x1 TB SSD.
Schema
schema.propertyKey('personId').Text().create(); schema.propertyKey('name').Text().create(); schema.propertyKey('age').Bigint().create(); schema.vertexLabel('person').partitionKey('personId').properties('name', 'age').create(); schema.edgeLabel('knows').connection('person', 'person').create();
Traversal
Java DSE Graph Fluent API ( analogous to Tinkerpop Bytecode API )
DseGraph.statementFromTraversal(DseGraph.traversal()
.addV("person")
.property("personId", session("edgeCount").asOption[String].get + "from")
.property("name", "marko" + session("edgeCount").asOption[String].get + "from")
.property("age", session("edgeCount").asOption[Long].get + 1) .as("a") .addV("person")
.property("personId", session("edgeCount").asOption[String].get + "to")
.property("name", "marko" + session("edgeCount").asOption[String].get + "to")
.property("age", session("edgeCount").asOption[Long].get + 1)
.addE("knows").from("a") )
String API ( analogous to Tinkerpop Script API )
g.addV("person")
.property("personId", edgeCount + "from")
.property("name", "marko" + edgeCount + "from")
.property("age", edgeCount + 1)
.as("a")
.addV("person")
.property("personId", edgeCount + "to")
.property("name", "marko" + edgeCount + "to")
.property("age", edgeCount + 1)
.addE("knows").from("a")
Conclusion
To wrap things up, we hope that this inspires you to upgrade to the latest versions of DataStax Enterprise and the DSE Java Driver to reap the benefits of this improvement for your DSE Graph traversals. Our road does not stop here and we will continue to pour enhancements into both Apache TinkerPop™ and DSE Graph to make your applications that leverage DSE Graph truly the best in class.
For more on DataStax Enterprise Graph, please visit the following links.
More Company
View All


Introducing Tejas Kumar, Developer Relations Engineer
