Educating the Planet with Pearson

Marko A. Rodriguez

 Pearson is striving to accomplish the ambitious goal of providing an education to anyone, anywhere on the planet. New data processing technologies and theories in education are moving much of the learning experience into the digital space -- into massive open online courses (MOOCs). Two years ago Pearson contacted Aurelius about applying graph theory and network science to this burgeoning space. A prototype proved promising in that it added novel, automated intelligence to the online education experience. However, at the time, there did not exist scalable, open-source graph database technology in the market. It was then that Titan was forged in order to meet the requirement of representing all universities, students, their resources, courses, etc. within a single, unified graph. Moreover, beyond representation, the graph needed to be able to support sub-second, complex graph traversals (i.e. queries) while sustaining at least 1 billion transactions a day. Pearson asked Aurelius a simple question: "Can Titan be used to educate the planet?" This post is Aurelius' answer.
Pearson is striving to accomplish the ambitious goal of providing an education to anyone, anywhere on the planet. New data processing technologies and theories in education are moving much of the learning experience into the digital space -- into massive open online courses (MOOCs). Two years ago Pearson contacted Aurelius about applying graph theory and network science to this burgeoning space. A prototype proved promising in that it added novel, automated intelligence to the online education experience. However, at the time, there did not exist scalable, open-source graph database technology in the market. It was then that Titan was forged in order to meet the requirement of representing all universities, students, their resources, courses, etc. within a single, unified graph. Moreover, beyond representation, the graph needed to be able to support sub-second, complex graph traversals (i.e. queries) while sustaining at least 1 billion transactions a day. Pearson asked Aurelius a simple question: "Can Titan be used to educate the planet?" This post is Aurelius' answer.
Data Loading Benchmark
![]() Pearson provides free online education through its OpenClass platform. OpenClass is currently in beta with adoption by ~7000 institutions. To meet the expected growth beyond beta, it is necessary to build the platform on a scalable database system.
Pearson provides free online education through its OpenClass platform. OpenClass is currently in beta with adoption by ~7000 institutions. To meet the expected growth beyond beta, it is necessary to build the platform on a scalable database system.
![]() Moreover, it is important to build the platform on a database system that can support advanced algorithms beyond simple get/put-semantics. The latter was demonstrated via the initial prototype. To the former, a simulation of a worldwide education environment was created in Titan to alleviate Pearson's scalability concerns.
Moreover, it is important to build the platform on a database system that can support advanced algorithms beyond simple get/put-semantics. The latter was demonstrated via the initial prototype. To the former, a simulation of a worldwide education environment was created in Titan to alleviate Pearson's scalability concerns.
| Number of students | 3.47 billion |
| Number of teachers | 183 million |
| Number of courses | 788 million |
| Number of universities | 1.2 million |
| Number of concepts | 9 thousand |
| Number of educational artifacts | ~1.5 billion |
| Total number of vertices | 6.24 billion |
| Total number of edges | 121 billion |
The simulated world was a graph containing 6.24 billion vertices and 121 billion edges. The edges represent students enrolled in courses, people discussing content, content referencing concepts, teachers teaching courses, material contained in activity streams, universities offering courses, and so forth. Various techniques were leveraged to ensure that the generated data was consistent with a real-world instance. For example, people names were generated from sampling the cross product of the first and last names in the US Census Bureau dataset. Gaussian distributions were applied to determine how many courses a student should be enrolled in (mean of 8) and how many courses a teacher should teach (mean of 4). The course names and descriptions were drawn from the raw MIT OpenCourseWare data dumps. Course names were appended with tokens such as "101," "1B," "Advanced," etc. in order to increase the diversity of the offerings. Student comments in discussions were sampled snippets of text from the electronic books provided by Project Gutenberg. University names were generated from publicly available city name and location datasets in the CommonHubData project. Finally, concepts were linked to materials using OpenCalais. The final raw education dataset was 10 terabytes in size.
A 121 billion edge graph is too large to fit within the confines of a single machine. Fortunately, Titan/Cassandra is a distributed graph database able to represent a graph across a multi-machine cluster. The Amazon EC2 cluster utilized for the simulation was composed of 16 hi1.4xlarge machines. The specification of the machines is itemized below.
- 60.5 GiB of memory
- 35 EC2 Compute Units (16 virtual cores and 64-bit)
- 2 SSD-based volumes each with 1024 GB of instance storage
- I/O Performance: Very High (10 Gigabit Ethernet)
 The 10 terabyte, 121 billion edge graph was loaded into the cluster in 1.48 days at a rate of approximately 1.2 million edges a second with 0 failed transactions. These numbers were possible due to new developments in Titan 0.3.0 whereby graph partitioning is achieved using a domain-based byte order partitioner. With respect to education, the dataset maintains a structure where most edges are intra-university rather than inter-university (i.e. students and teachers typically interact with others at their own university, and even more so within their own courses). As such, domain partitioning is possible where vertices within the university (i.e. graph community) are more likely to be co-located on the same physical machine.
The 10 terabyte, 121 billion edge graph was loaded into the cluster in 1.48 days at a rate of approximately 1.2 million edges a second with 0 failed transactions. These numbers were possible due to new developments in Titan 0.3.0 whereby graph partitioning is achieved using a domain-based byte order partitioner. With respect to education, the dataset maintains a structure where most edges are intra-university rather than inter-university (i.e. students and teachers typically interact with others at their own university, and even more so within their own courses). As such, domain partitioning is possible where vertices within the university (i.e. graph community) are more likely to be co-located on the same physical machine.
Once in Titan, the raw 10 terabyte dataset was transformed to 5 terabytes due to data agnostic Snappy compression and the use of Titan-specific graph compression techniques (e.g. "id deltas," type definitions, and Kryo serialization). After the data was loaded, it was immediately backed up to Amazon S3. This process took 1.4 hours using Titan's parallel backup strategy. The nodetool statistics for the Titan/Cassandra cluster are provided below.
|
|
Transactional Benchmark
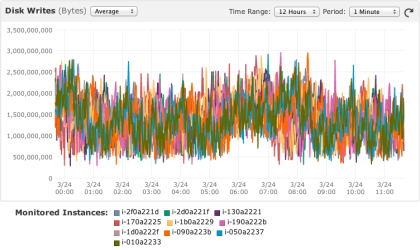
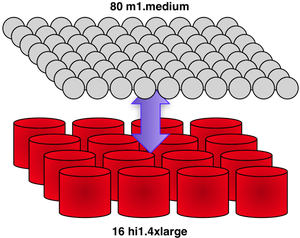 The purpose of the second half of the experiment was to subject the 121 billion edge education graph to numerous concurrent transactions. These transactions simulate users interacting with the graph -- solving educational problems, adding more content, discussing ideas with one another, etc. To put the 16 hi1.4xlarge cluster under heavy load, 80 m1.medium machines were spawned. These 80 machines simulate the application servers querying the graph and providing users the front-end experience. Each machine maintained 30 threads in a "
The purpose of the second half of the experiment was to subject the 121 billion edge education graph to numerous concurrent transactions. These transactions simulate users interacting with the graph -- solving educational problems, adding more content, discussing ideas with one another, etc. To put the 16 hi1.4xlarge cluster under heavy load, 80 m1.medium machines were spawned. These 80 machines simulate the application servers querying the graph and providing users the front-end experience. Each machine maintained 30 threads in a "while(true)-loop," randomly selecting 1 of 16 transactional templates below and executing it. Thus, 2,400 concurrent threads communicated with the 16 hi1.4xlarge Titan cluster. A review of the Gremlin queries and their mean runtimes with standard deviations are presented in the table below. Note that many of the transactions are "complex" in that they embody a series of actions taken by a user and thus, in a real-world setting, these would typically be broken up into smaller behavioral units (i.e. multiple individual transactions).
|
|
The transactional benchmark ran for 6.25 hours and executed 228 million complex transactions at a rate of 10,267 tx/sec. Provided the consistent behavior over those 6.25 hours, it is inferred that Titan can serve ~887 million transactions a day. Given the complex nature of the transactions, a real-world production system of this form should be able to sustain greater than 1 billion transactions a day.
Conclusion
 A first attempt at this benchmark was done at the turn of the year 2012. That benchmark was for a 260 billion edge graph (7 billion students) constructed using the same graph generation techniques described in this post. The graph data was loaded, but the transactional benchmark was never executed because the requisite cluster architecture could not be fulfilled by Amazon EC2 (all 32 high I/O machines in the same placement group). Thus, the smaller-scale benchmark presented here was what was possible given EC2's resources at the time.
A first attempt at this benchmark was done at the turn of the year 2012. That benchmark was for a 260 billion edge graph (7 billion students) constructed using the same graph generation techniques described in this post. The graph data was loaded, but the transactional benchmark was never executed because the requisite cluster architecture could not be fulfilled by Amazon EC2 (all 32 high I/O machines in the same placement group). Thus, the smaller-scale benchmark presented here was what was possible given EC2's resources at the time.
While this benchmark demonstrates that Titan can handle the data scale and transactional load of "99%" of applications developed today, Aurelius is not sufficiently satisfied with the presented transactional results. By reducing the transactional load to ~5,000 tx/sec, the runtimes of the queries dropped to the 100 millisecond range. The desired result was to achieve ~100ms query times at 10k tx/sec and 250ms at 25k tx/sec. Fortunately, much was learned about Titan/Cassandra during this exploration. Advances in both inter-cluster connection management and machine-aware traversal forwarding are currently in development in order to reach the desired scaling goals.
A scalable graph database is only half the story -- the story presented here. Once scaling has been accomplished, the next problem is yielding knowledge from data. For the last 2 years, Aurelius has been working with Pearson to develop novel algorithms for the education space that move beyond the typical activities seen in current web-systems: profiles, streams, recommendations, etc. Online education is ripe for automating much of the intelligence currently contributed by students and teachers. With a collective graphical model, Aurelius' algorithms move beyond creating a dynamic interface to providing computational human augmentation. These techniques generalize and should prove fruitful to other domains.
Acknowledgements
This report was made possible due to funding provided by Pearson Education. Over the 5 months that this benchmark was developed, the following individuals provided support: Pavel Yaskevich (Cassandra tuning and Titan development) and Stephen Mallette/Blake Eggleston (RexPro development and testing). Various issues in Cassandra were identified at scale and the Cassandra community readily accepted patches and quickly released newer versions in support of the effort. Note that Titan is an open source, Apache2 licensed graph database. The Titan community has supported the project via patch submissions and testing across use cases and cluster configurations. Finally, Steve Hill of Pearson has done much to ensure Titan's success -- pushing Aurelius to answer the question: "Can Titan educate the planet?"



