Impact of Shared Storage on Apache Cassandra

Gehrig Kunz

Every now and then we receive the question of why shared storage isn’t recommended for Apache Cassandra®. The conversation usually goes like this:
Customer/User – “We have an awesome SAN and would like to use it for Cassandra.”
DataStax – “We don’t recommend shared storage for Cassandra.”
Customer/User – “Why not.”
DataStax – “Two reasons really. One – performance suffers. Two – shared storage introduces a single point of failure into the architecture.”
Customer/User – “Our SAN is awesome and has never had any down time and can preform a kagillion IOPS. So why exactly shouldn’t we use shared storage.”
Hopefully, this blog post will provide some data points around shared storage and performance that will dissuade users from leveraging shared storage with Cassandra.
Single Point of Failure
There really isn’t anything to say about shared storage being a single point of failure. If someone has a single shared storage device in their architecture and multiple Cassandra nodes are pointing at the shared storage device, then the shared storage device is a single point of failure.
Performance
Our Senior Evangelist likes to define performance as the combination of speed and stability. For Cassandra, a lot of performance comes from the underlying disk system that is supporting Cassandra. To put it plainly, performance in Cassandra is directly correlated to the performance of a Cassandra node’s disk system.
But why is that? And, why can’t a super-awesome shared storage device keep up with Cassandra.
To answer the question of why, let’s take a look at the major (arguably) contributors to Cassandra disk io and measure throughput and latency. We will then take a look at some real world statistics that show the aggregated behavior of Cassandra on a shared storage device to show the affects of shared storage with Cassandra. All of these data points should show the reader that the load placed onto a storage device from a single node of Cassandra is large. And, when multiple Cassandra nodes use the same storage device, the compounded effects from each individual node’s disk io overwhelms the shared storage device.
Cassandra Disk Pressure
Cassandra uses disks heavily, specifically during writes, reads, compaction, repair (anti-entropy), and bootstrap operations.
- Writes in Cassandra are preformed using a log structured storage model, i.e. sequential writes. This allows Cassandra to ingest data much faster than traditional RDBMs systems. The write path will put heavy io pressure on disks from Commit Log syncs as well as Memtable flushes to SSTables (disk).
- Compaction is the process in Cassandra that enables good read performance by combining (merge-sorting) multiple SStables into a single SSTable. Since SSTables are immutable, this process puts a lot of pressure on disk io as SSTables are read from disk, combined and written back to disk. There are two main types of compaction and each has different io impact.
- Reads in Cassandra will take advantage of caching for optimization, but when they hit disk, they put pressure on the disk system. Each read operation against an SSTable is considered a single disk seek. Sometimes a read operation will be required to touch more than one SSTable, therefore will experience multiple disk io operations. If caches are missed during read operations, then disk io is even heavier as more SSTables are accessed to satisfy the read operation.
- Repairs are the process in Cassandra that ensures data consistency across nodes in a cluster. Repairs rely on both compaction and streaming, i.e. bulk ingestion of data, to compare and correct data replicas between nodes. Repair is designed to work as a background process and not impact the performance of production clusters. But, repair puts some stress of the disk systems because both compaction and ingestion occurs during the operation.
- Bootstrapping a node is the process of on-boarding a new, or replacing a dead, node in Cassandra. When the node starts, data is streamed to the new node which persists all data to disk. Heavy compaction occurs during this process. Thus, there is a lot of pressure put onto a disk system during the bootstrap operation.
The above list represents a subset of the disk intensive operations that occur within Cassandra.
What’s important to understand about all of the disk io operations in Cassandra is that they are not only “heavy” in terms of IOPS (general rule of thumb is that Cassandra can consume 5,000 write operations per second per CPU code) but, arguably more importantly, they can also be very heavy in terms of throughput, i.e. MB/s. It is very conceivable that the disk system of a single node in Cassandra would have to maintain disk throughput of at least 200 MB/s or higher per node. Most shared storage devices tout IOPS but don’t highlight throughput as stringently. Cassandra will put both high IOPS as well as high throughput, depending on the use case, on disk systems. Heavy throughput is a major reason why almost all shared storage Cassandra implementations experience performance issues.
To reinforce this point, we performed a simple Cassandra Stress, (Quorum writes, Replication x 3, 100 million keys, 100 cols per partition, disabled compaction throttling, increased concurrent writers) test on a 3 node EC2 cluster (M3.2XL nodes) and watched disk performance for a couple of hours via OpsCenter, sar, and iostat.
Here are some observations:
- iostat – wMB/s as high as 300 with sustained loads well over 100
- iostat – rMB/s (thanks to compaction) as high as 100 with sustained loads well over 50
- Opscenter – max disk utilization peak as high as 81% with average around 40%
- sar -d – wr_sec/s as high as 224,506 with sustained loads around 200,000
This was a small and simple test that showed the amount of load put onto disk systems during small operations. Imagine this load amplified with a complex, real-world workload and a production sized cluster (more than 3 nodes). The compound effects of these operations could easily overwhelm shared storage devices. We’ve actually overheard, though we won’t name names, storage vendors recommending not running Cassandra on their devices.
Here’s a real world example of the behavior of a shared storage device with a production Cassandra cluster. Recently while on site with a customer, who will remain anonymous to protect the innocent, we collected several data points that highlight a typical shared storage environment. The statistics collected during this on site trip represent the majority of observations made when shared storage is used for a production Cassandra system.
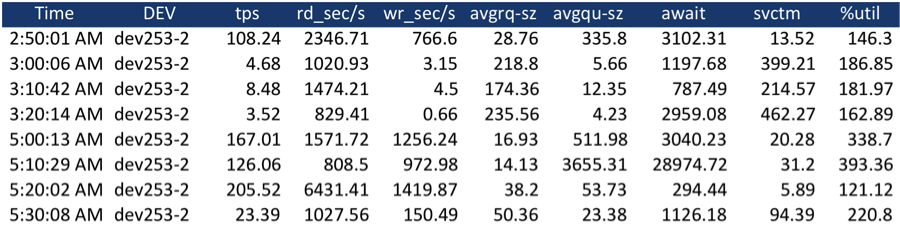
The metrics collected here were collected with sar but are the same as collected by iostat.
As one can see by this simple table, we were observing the state of device io every 10 minutes. We filtered the results to show two, 40 minute chunks of time. This table provides some exceptional metrics on poor disk performance caused by the use of shared storage. Yes, that is a 28, almost 29, second wait. Cassandra actually considered this node “down” because it was unresponsive during the high wait periods. Also, the load is minimal compared to what we were able to produce using cassandra-stress.
Performance Issues
When users chose to run Cassandra with shared storage devices, they should expect to experience any number of performance issues. The following list highlights a few potential, probable, performance issues that would be expected:
- Atrocious read performance
- Potential write performance issues
- System instability (nodes appear to go offline and/or are “flapping”)
- Client side failures on read and/or write operations
- Flushwriters are blocked
- Compactions are backed up
- Nodes won’t start
- Repair/Streaming won’t complete
Conclusion
There is one flavor of shared storage that we have seen used somewhat successfully. In environments where virtualization is used, locally attached storage that is shared across local virtual machines isn’t “so” bad. This is similar in concept to ephemeral storage in AWS.
Regardless of the channel, cable, or other fancy feature the shared storage device may have, a shared storage device will not be able to keep up with the io demand placed onto it by Cassandra.
Simply put, shared storage cannot keep up with the amount of disk io placed onto a system from Cassandra. It’s not recommended. Don’t use shared storage with Cassandra and be happier for it.
“Impact of Shared Storage on Cassandra“ was created by Jonathan Lacefield, Sr. Product Manager at DataStax.
More Technology
View All
Introducing the DataStax AI Terraform Module


