

With Cassandra 3.2 we improve the way Cassandra handles JBOD configuration, that is, using multiple data_file_directories. Earlier versions have a few problems which are unlikely to happen but painful if they do. First, if you run more than one data directory and use SizeTieredCompactionStrategy (STCS) you can get failing compactions due to running out of disk space on one of your disks. The reason for this is that STCS picks a few (typically 4) similarly sized sstables from any data directory and compacts them together into a single new file. With a single data directory and the recommendend 50% disk space free, this works fine, but if you have 3 equally sized data directories on separate physical disks, all 50% full, and we create a compaction with all that data we will put the resulting file in a single data directory and most likely run out of disk space. The same issue can happen with LeveledCompactionStrategy since we do SizeTieredCompaction in L0 if the compactions get behind.
The other problem (and the reason CASSANDRA-6696 was created in the first place) is that we can have deleted data come back with the following scenario:
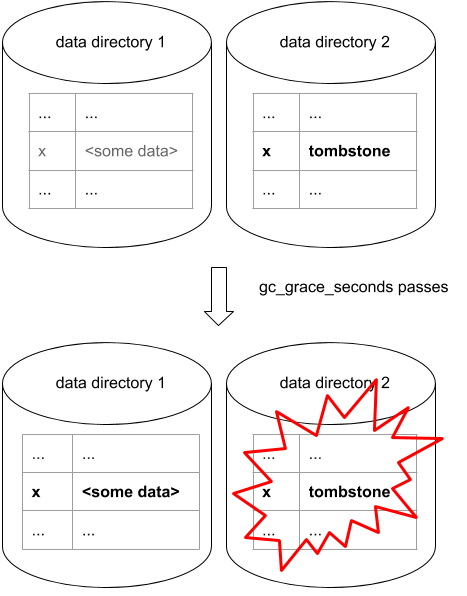
- A user successfully writes key x to the cluster
- Some time later, user deletes x (we write a tombstone for x).
- This tombstone (by chance) gets stored in a separate data directory from the actual data.
- gc_grace_seconds passes.
- Two of the nodes containing x compact away both data and tombstone, which is OK since gc_grace has passed.
- The third node does no compaction including all the sstables containing x. This means we can't drop tombstone or the actual data.
- The data directory containing the tombstone for x gets corrupt on the third node, for example by having the disk backing the data directory break.
- Operator does the natural thing and replaces the broken disk and runs repair to get the data back to the node.
- The key x is now back on all nodes.
Splitting ranges
The way we decided to solve the problems above was to make sure that a single token would never exist in more than one data directory. This means we needed to change the way we do compaction, flushing and streaming to make sure we never write a token in the wrong data directory. Note that we can still have tokens on the wrong directory temporarily, for example after adding nodes or changing replication factor, but compaction will automatically move tokens to the correct locations as we compact the data. To do this, we need to split the owned local ranges over the data directories configured for the node. We sum up the number of tokens the node owns, divide by the number of data directories and then make sure that we find boundary tokens that make sure each data directory gets as many tokens. Note that we can't care about disk size when splitting the tokens as we might give too much data to a disk that is big but is not 100% for Cassandra, and we also can't care about the amount of free space on the disk as that would make the data directory boundaries change every time we write to the data directory. We are only able to split the ranges for the random partitioners (RandomPartitioner and Murmur3Partitioner) - if you run an ordered partitioner, the behaviour stays the same as it is today - we flush/compact/stream to a single file and make no effort to put tokens in a specific data directory.
If you run vnodes we make sure we never split a single vnode range into two separate data directories, the reason for this is that in the future we could take the affected vnodes offline until the node has been rebuilt if we have a disk failure. This also enables us to do CASSANDRA-10540 where we split out separate sstables for every local range on the node, meaning each vnode will have its own set of separate sstables. Note that before CASSANDRA-7032 vnode allocation was random and with a bit of bad luck the vnodes can vary a lot in size and therefore make the amount of data in each data directory unbalanced. In practice this should not be a big problem since each node typically has 256*3 local ranges (number of tokens * replication factor) making it easier to find boundary tokens to make the data directories balanced. Also note that if we have 256*3 tokens and 3 data directories, we will not put exactly 256 ranges in each directory, instead we sum up the number of tokens in total owned by the node, then find boundary tokens that makes the token count per data directory as balanced as possible.

Splitting local range without vnodes - each data directory gets the same number of tokens

Splitting local ranges with vnodes - sum of the number of tokens in the local ranges (green boxes) in each data directory should be balanced
By having all data for one token is on the same disk makes sure that we lose all versions of a token if a disk breaks - this makes it safe to run repair again as we can not have any data that was deleted come back to life.
Compaction
To solve the problem with compaction picking sstables from several data directories and putting the result in a single directory, we made compaction data directory-local. Since CASSANDRA-8004 we run two compaction strategy instances - one for unrepaired data and one for repaired data and after CASSANDRA-6696 we run one pair of compaction strategy instances per data directory. Since it is impossible to pick sstables from two different compaction strategy instances when we start a compaction, we make sure that the compaction stays data directory local. If all tokens are placed correctly, we know that the result is going to stay in the same directory where the original sstables live - but if some tokens are in the wrong place, we will write them into new sstables in the correct locations.
Partitioning compactions over data directories like this also makes it possible to run more compactions in parallel with LeveledCompactionStrategy as we now know that each data directory will not overlap with the sstables in another data directory.
Major compaction
When a user triggers a major compaction each compaction strategy instance picks all its sstables and runs a major compaction over them. If all tokens are in the correct place, the resulting sstable(s) will stay in the same compaction strategy instance. If we have tokens that are in the wrong place, these tokens will get moved into a new sstable in the correct data directories. When running STCS, users might expect a single sstable (or two if you run incremental repairs, one for unrepaired and one for repaired data) as the result of a major compaction, after CASSANDRA-6696 we will end up with one (or two) sstable per data directory if all tokens are in the correct place, and more sstables otherwise.
Flushing
Flushing is now multi threaded, one thread per data directory. When we start a flush, we split the memtable in the number of data directories parts and give each part to a thread to write to disk. This should improve flushing speed unless you flush tiny sstables where the overhead of splitting is bigger than the gain from writing the parts in parallel.
Streaming
We simply write the stream to the correct locations, this means that one remote file can get written to several local ones.
Backups
This also makes it possible to backup and restore individual disks. Before CASSANDRA-6696 you would always need to restore the entire node since you could have tokens compacted to the disk from other disks between the time you did your backup to the time when the disk crashed. Now you can take the disk-backup plus its incremental backup files and restore the single disk that died.
Migration/Upgrading
You don't need to do anything to migrate - compaction will take care of moving the tokens to the correct data directories. If you want to speed this process up there is nodetool relocatesstables which will rewrite any sstable that contains tokens that should be in another data directory. This command can also be used to move your data into the correct places if you change replication factor or add a new disk. Nodetool relocatesstables is a no-op if all your tokens are in the correct places.
More Technology
View All


