A Letter Regarding Native Graph Databases

Marko A. Rodriguez

It's fun to watch marketers create artificial distinctions between products that grab consumer attention. One of my favorite examples is Diamond Shreddies. Shreddies, a whole wheat cereal, has a square shape and was always displayed as such. So an indigenous advertiser at Kraft foods thought to advertise a new and better Diamond Shreddies. It's a fun twist that got people's attention and some consumers even proclaimed that Diamond Shreddies tasted better though they obviously ate the same old product.Such marketing techniques are also used in the technology sector -- unfortunately, at a detriment to consumers. Unlike Kraft's playful approach, there are technical companies that attempt to "educate" engineers on artificial distinctions as if they were real and factual. An example from my domain is the use of the term native graph database. I recently learned that one graph database vendor decided to divide the graph database space into non-native (i.e. square) and native (i.e. diamond) graph databases. Obviously, non-native is boring, or slow, or simply bad and native is exciting, or fast, or simply good.
Problem is: There is no such thing as a native graph database.
On the Concept of Native Computing
Let's look at the definition of "native" when applied to data as taken directly from Wikipedia's Native Computing article:
Applied to data, native data formats or communication protocols are those supported by a certain computer hardware or software, with maximal consistency and minimal amount of additional components.
I'm not claiming that Wikipedia is an authority on this subject, but this is a baseline definition we can work with for the purpose of this letter's argument. From Wikipedia's definition, it follows that a native graph database is a graph database that represents the graph (i.e. data) maximally consistent with the underlying hardware. Currently, all commercially-available hardware follows the Von Neumann architecture. Under the Von Neumann architecture, the memory subsystems are represented as a sequential memory space. Moreover, in said memory systems, sequential access is significantly faster than random access. Realize this for yourself by writing a very large array into RAM and then comparing sequential vs. random access times. If you are too busy, read Pathologies of Big Data as the author has done the comparison for you on different types of memory systems. If you are regularly working with non-trivial amounts of data, you most definitely should read the Pathologies of Big Data article.
Next, the purpose of any database is to retrieve a query result set by navigating the memory hierarchy and sequentializing memory access as much as possible. How the data is laid out in each of these memory systems, i.e. the data format, data structures and caches, explains many if not most of the differences between database systems. As an example, consider columnar databases. These relational databases store tables by columns (not rows) which makes it possible to quickly compute aggregates over columns because data access is sequential. That's why they outperform their row-oriented counter parts on analytic queries.
We conclude that a database system is native if the data formats and structures it uses effectively sequentialize memory access across the memory hierarchy for the targeted type of workload.
Embedding a Graph in a 1-Dimensional Space
Let us now apply the concept of native computing to graph databases. Graph databases need to efficiently execute arbitrary graph traversals. A graph traversal is a restricted walk over the graph, moving from one vertex to its adjacent vertices via a selected set of incident edges. Without making any assumption on the type of traversal to be executed, it follows that a graph database needs to store vertices, their incident edges and their adjacent vertices in close proximity in the memory systems in order to sequentialize memory access (see Scalable Graph Computing: Der Gekrümmte Graph). However, those vertices have other adjacent vertices which makes it impossible to keep everything sequential (save in the most trivial graph topologies).
Consider the small graph on the left. Pick any vertex. Linearly write down that vertex, its edges and its adjacent vertices. With that initial choice made, it becomes increasingly difficult -- and ultimately impossible -- to add the other vertices, their edges and adjacencies into your linear list without pulling adjacent vertices apart. What you are attempting to do, and what every graph database needs to do, is to topologically embed a graph into a 1-dimensional space. There is a branch of mathematics called topological graph theory which studies such graph embeddings for arbitrary spaces and graphs. Unless the graph has no edges or forms a linear chain, there is no (strict) embedding into a 1-dimensional space. Hence, for all but the simplest graphs there exists no native data representation on typical Von Neumann computers which require sequential memory layout.
We conclude that there is no such thing as a native graph database for current computing systems.
Approximations to Embedding a Graph in a 1-Dimensional Space
Without a perfect mapping, the best that can be achieved is an approximation. Thus, the layout of a graph in sequential memory turns into an optimization problem. The question then becomes: "Can we lay out the graph sequentially so that most vertices have their neighbor close by?" For any given graph layout in memory, we can define the distance between two adjacent vertices as the absolute difference in their (sequential) memory addresses. Then, we define the objective function as the sum of distances of all adjacent vertex pairs. The optimal graph data layout is the one that minimizes this objective function. Unfortunately, this optimization problem is NP-hard, which means that the best we can hope for in practice are approximations (unless P=NP). Even those approximations are pretty expensive to compute. For example, in my research on disk-oriented graph layouts, I propose an approximation method based on hierarchical clustering which took hours to calculate on graphs with 100s of millions of edges and requires that the graph structure remain fixed. A static graph structure is not an option if you need to update the graph in real-time (i.e. the typical use-case for a graph database). There is a vast trove of research on the subject of optimal graph embeddings, which I encourage you to read if you are interested in the fascinating world of hyper-dimensional manifolds, but let me conclude here that this problem is difficult, far from solved, and an area of active research.
We conclude that a graph database should be judged on the tradeoffs it makes concerning computational/memory complexity and the quality of its graph embeddings.
Titan's Approach to Embedding a Graph in a 1-Dimensional Space
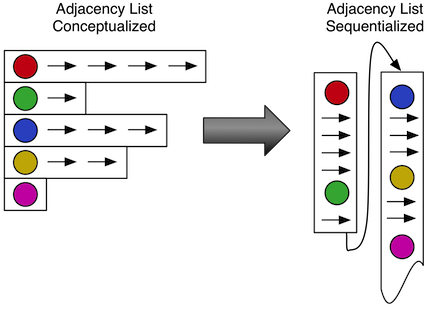 Let me illustrate the tradeoff choices that the graph database Titan has made in embedding a graph into a modern computer. Titan internally represents a graph as an adjacency list. This means it stores each vertex with all of its properties and incident edges in one sequential list. This has the benefit that Titan can access all edges and their properties with one sequential scan. In fact, Titan uses a more sophisticated variant of the adjacency list format where edges are stored in a user-defined sort order. For each vertex, an offset index is built that allows for fast retrieval of subsets of the incident edges that fall within a given sequential range. We call these indices vertex-centric indices and they significantly speed up graph traversals on large graphs which have vertices with many edges -- so called supernodes (see A Solution to the Supernode Problem). The downside of vertex-centric indices is that they require building index structures, keeping edges in sort order, and each edge is stored twice. This, in turn, requires more complex data structures and regular compactions of the data files after updates to the graph. Once off disk, Titan maintains the sorted adjacency list format in RAM using binary search instead of building index structures to acknowledge the slightly more favorable random access times of RAM. This allows the CPU to effectively prefetch data on traversals. We see that Titan expends additional storage space and computation to achieve a more sequential representation of the graph for quicker data retrieval.
Let me illustrate the tradeoff choices that the graph database Titan has made in embedding a graph into a modern computer. Titan internally represents a graph as an adjacency list. This means it stores each vertex with all of its properties and incident edges in one sequential list. This has the benefit that Titan can access all edges and their properties with one sequential scan. In fact, Titan uses a more sophisticated variant of the adjacency list format where edges are stored in a user-defined sort order. For each vertex, an offset index is built that allows for fast retrieval of subsets of the incident edges that fall within a given sequential range. We call these indices vertex-centric indices and they significantly speed up graph traversals on large graphs which have vertices with many edges -- so called supernodes (see A Solution to the Supernode Problem). The downside of vertex-centric indices is that they require building index structures, keeping edges in sort order, and each edge is stored twice. This, in turn, requires more complex data structures and regular compactions of the data files after updates to the graph. Once off disk, Titan maintains the sorted adjacency list format in RAM using binary search instead of building index structures to acknowledge the slightly more favorable random access times of RAM. This allows the CPU to effectively prefetch data on traversals. We see that Titan expends additional storage space and computation to achieve a more sequential representation of the graph for quicker data retrieval.
Once vertices are co-located with their incident edges, the next problem is, how should vertices be co-located with their adjacent vertices? Vertices are laid out sequentially in random or guided order. With random order there is no data locality between adjacent vertices but its trivial to compute and leads to balanced partitions in distributed environments. Alternatively, Titan provides a "guided order" mode which allows users to plug-in a heuristic function that tells Titan which partition block a particular vertex should be assigned to or which other vertex it should be close to. While Titan handles all of the logistics, the "intelligence" of the allocation is in the heuristic function. We believe that for some graphs it is pretty easy to come up with a good heuristic function with enough domain knowledge. For instance, the Facebook graph can be effectively partitioned using user geography as a heuristic (see Balanced Label Propagation for Partitioning Massive Graphs). This is not surprising since users who live close by are more likely to be friends on Facebook. Heuristic partitioning works well on some graphs, but requires more computation on update and is prone to imbalances in distributed deployments if not used carefully.
To conclude, the next time somebody tries to sell you a "native" graph database, be sure to reference this letter and ask them how they lay out their graph throughout all the sequential memory layers and decide for yourself the optimality of their embedding (both on disk and in memory)
Conclusion
The intention of this letter was to point out the challenges that all graph databases are facing, vindicate Titan from arbitrary categorization by vendor marketing, and to ensure that the public is properly educated on the topic at hand. All arguments presented are based on generally available computer science knowledge. Please comment on Hacker News if you find the argument flawed, lacking a proper citation, or wish to discuss the thesis at greater length. Moreover, if you are interested in this area of technology, please join Aurelius' public mailing list and participate in helping us develop the next generation of graph technologies.
Acknowledgements
Dr. Marko A. Rodriguez provided editorial review of this letter in order to make the presented argument more concise, supported with images, and easier to consume for the general reader. Pavel Yaskevich provided astute points regarding the interplay between CPU caches and RAM.
More Technology
View All
Introducing the DataStax AI Terraform Module


