Lightweight transactions in Cassandra 2.0

Jonathan EllisTechnology

Background
When discussing the tradeoffs between availability and consistency, we say that a distributed system exhibits strong consistency when a reader will always see the most recently written value.
It is easy to see how we can achieve strong consistency in a master-based system, where reads and writes are routed to a single master. However, this also has the unfortunate implication that the system must be unavailable when the master fails until a new master can take over.
Fortunately, you can also achieve strong consistency in a fully distributed, masterless system like Cassandra with quorum reads and writes. Cassandra also takes the next logical step and allows the client to specify per operation if he needs that redundancy -- often, eventual consistency is completely adequate.
But what if strong consistency is not enough? What if we have some operations to perform in sequence that must not be interrupted by others, i.e., we must perform them one at a time, or make sure that any that we do run concurrently will get the same results as if they really were processed independently. This is linearizable consistency, or in ACID terms, a serial isolation level.
For example, suppose that I have an application that allows users to register new accounts. Without linearizable conistency, I have no way to make sure I allow exactly one user to claim a given account -- I have a race condition analogous to two threads attempting to insert into a [non-concurrent] Map: even if I check for existence before performing the insert in one thread, I can't guarantee that no other thread inserts it after the check but before I do.
Paxos
Again, we can easily see how to get linearizable consistency if we route all requests through a single master. In a fully distributed system, it is less obvious. Early attempts in Cassandra tried to address this by wrapping a lock around sensitive operations, e.g. with the Cages library or with Hector's native locks. Unfortunately, the locking approach exposes you to unpleasant edge cases including lost updates in failure scenarios. We need to do better.
Fortunately, we can. The Paxos consensus protocol allows a distributed system to agree on proposals with a quorum-based algorithm, with no masters required and without the problems of two-phase commit. There are two phases to Paxos: prepare/promise, and propose/accept. 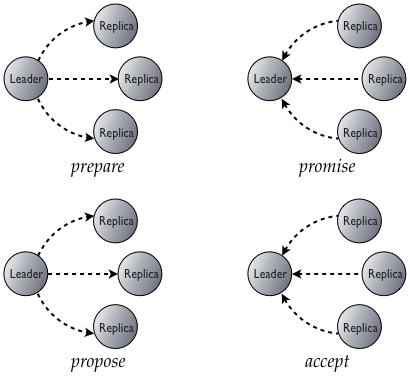
Prepare/promise is the core of the algorithm. Any node may propose a value; we call that node the leader. (Note that many nodes may attempt to act as leaders simultaneously! This is not a "master" role.) The leader picks a ballot and sends it to the participating replicas. If the ballot is the highest a replica has seen, it promises to not accept any proposals associated with any earlier ballot. Along with that promise, it includes the most recent proposal it has already received.
If a majority of the nodes promise to accept the leader's proposal, it may proceed to the actual proposal, but with the wrinkle that if a majority of replicas included an earlier proposal with their promise, then that is the value the leader must propose. Conceptually, if a leader interrupts an earlier leader, it must first finish that leader's proposal before proceeding with its own, thus giving us our desired linearizable behavior.
(For more details on Paxos itself, the best resource is Paxos made Simple.)
Extending Paxos
The alert reader will notice here that Paxos gives us the ability to agree on exactly one proposal. After one has been accepted, it will be returned to future leaders in the promise, and the new leader will have to re-propose it again. We need a way to "reset" the Paxos state for subsequent proposals. Most discussions of Paxos focus on using it to build an edit log. In our case, what we really want to do is move the accepted value into "normal" Cassandra storage. To do this, we add a third phase of commit/acknowledge: 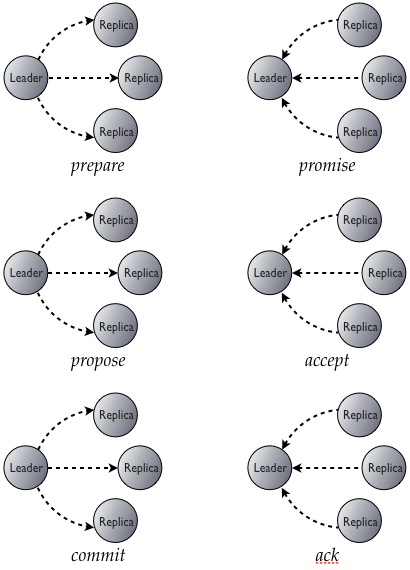
Finally, because we expose this functionality as a compare-and-set operation, we need to read the current value of the row to see if it matches the expected one. Our full sequence then looks like this: 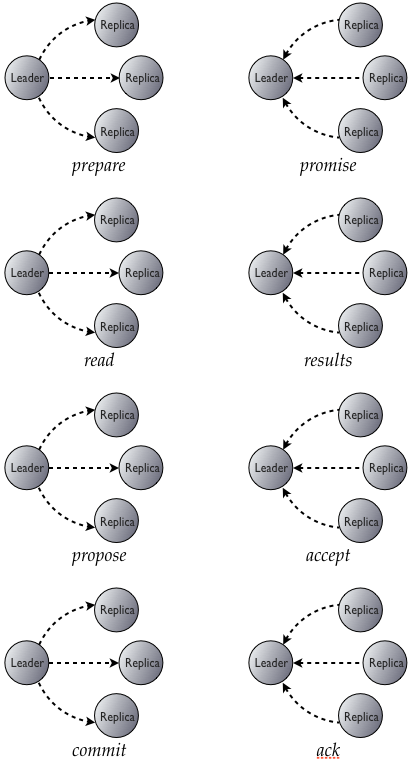
Thus, at the cost of four round trips, we can provide linearizability. That sounds like a high cost—perhaps too high, if you have the rare case of an application that requires every operation to be linearizable. But for most applications, only a very small minority of operations require linearizability, and this is a good tool to add to the strong/eventual consistency we've provided so far.
Lightweight transactions in CQL
Lightweight transactions can be used for both INSERT and UPDATE statements, using the new IF clause. Here's an example of registering a new user:
INSERT INTO USERS (login, email, name, login_count)
values ('jbellis', 'jbellis@datastax.com', 'Jonathan Ellis', 1)
IF NOT EXISTS
And an an example of resetting his password transactionally:
UPDATE users SET reset_token = null, password = 'newpassword'
WHERE login = 'jbellis'
IF reset_token = 'some-generated-reset-token'
Some fine print:
- The columns updated do NOT have to be the same as the columns in the IF clause.
- Lightweight transactions are restricted to a single partition; this is the granularity at which we keep the internal Paxos state. As a corollary, transactions in different partitions will never interrupt each other.
- If your transaction fails because the existing values did not match the one you expected, Cassandra will include the current ones so you can decide whether to retry or abort without needing to make an extra request.
- ConsistencyLevel.SERIAL has been added to allow reading the current (possibly un-committed) Paxos state without having to propose a new update. If a SERIAL read finds an uncommitted update in progress, it will commit it as part of the read.
- For details of how we deal with failures, see the comments and code.
- Tickets for DC-local transactions, updating multiple rows in a transaction, and cqlsh support for retrieving the current value from an interrupted transaction are open and will be fixed for 2.0.1.
More Technology
View All
Introducing the DataStax AI Terraform Module


