

A Gremlin traversal is an abstract description of a legal path through a graph. In the beginning, a single traverser is created that will birth more traversers as a function of the instructions dictated by the traversal. A branching familial tree of traversers is generated from this one primordial, patient zero, adamic traverser. Many traversers will die along the way. They will be filtered out, they will walk down dead-end subgraphs, or they will meet other such fates which conflict with the specification of the traversal as defined by the user (the true sadist in this story). However, the traversers that are ultimately returned are the result of a traverser lineage that has survived the traversal-guided journey across the graph. These traversers are recognized for the answers they provide, but it is only because of the unsung heroes that died along the way that we know that their results are sound and complete.
Suppose the following Traversal below that answers the question: What is the distribution of labels of the vertices known by people?" That is, what are the types and counts of the things that people know? This traversal assumes a graph where a person might know an animal, a robot, or just maybe, another person. The result is a Map such as [person:107, animal:1252, robot:256].
|
|
Every legal path of the traversal through the graph is walked by a Traverser. A traverser holds a reference to both its current object in the graph (e.g. a Vertex) and its current Step in the traversal (e.g. label()) . If the traverser is currently at vertex v[1] and step label(), then the traverser will walk to the String label of v[1]. As such, label() executes a one-to-one mapping (MapStep) as a vertex can have one and only one label. A one-to-many mapping (FlatMapStep) occurs if the traverser is currently at v[1] and at the step out("knows"). In this situation, the traverser will branch the traverser family tree by splitting itself across all "knows"-adjacent vertices of v[1]. A many-to-one mapping occurs via a ReducingBarrierStep which aggregates all the traversers up to that step and then emits a single traverser representing an analysis of that aggregate. The groupCount()-step is an example of a reducing barrier step. Finally, there is a one-to-maybe mapping (FilterStep). The step hasLabel("person") will either let the traverser pass if it is at a person vertex or it will filter it out of the data stream.
The generic form of the step instances mentioned above are the fundamental processes of any Gremlin traversal. It is important to note that a traversal does not define how these processes are to be evaluated. It is up to the _Gremlin traversal machine_ to determine the means by which the traversal is executed. The Gremlin traversal machine is an abstract computing machine that is able to execute Gremlin traversals against any TinkerPop-enabled graph system. In general, the machine's algorithm moves traversers (pointers) through a graph (data) as dictated by the steps (instructions) of the traversal (program). The Gremlin traversal machine distributed by Apache TinkerPop™ provides two implementations of this algorithm.

- Chained Iterator Algorithm (OLTP): Each step in the traversal reads an iterator of traversers from "the left" and outputs an iterator of traversers to "the right" in a stream-based, lazy fashion. This is also known as the standard OLTP execution model.
- Message Passing Algorithm (OLAP): In a distributed environment, each step is able to read traverser messages from "the left" and write traversers messages to "the right." If a message references an object that is locally accessible, then the traverser message is further processed. If the traverser references a remote object, then the traverser is serialized and it continues its journey at the remote location. This is also known as the computer OLAP execution model.
While both algorithms are semantically equivalent, the first is pull-based and the second is push-based. Apache TinkerPop™'s Gremlin traversal machine supports both modes of execution and thus, is able to work against both OLTP graph databases and OLAP graph processors. Selecting which algorithm is used is a function of defining a TraversalSource that will be used for subsequent traversals.
|
|
This article is specifically about Gremlin OLAP and its message passing algorithm. The following sections will discuss different aspects of this algorithm in order to help elucidate the mechanics of Gremlin OLAP.
Vertex-Centric Computing
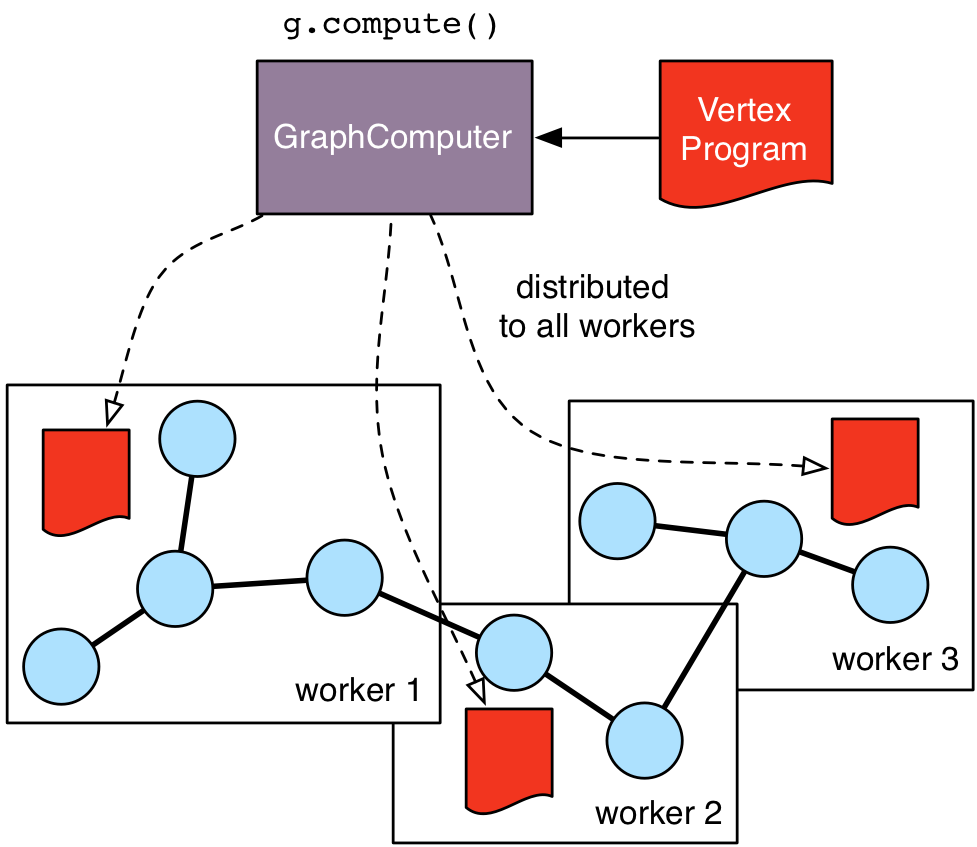
Every TinkerPop-enabled OLAP graph processor implements the GraphComputer interface. A GraphComputer is able to evaluate a VertexProgram. A vertex program can be understood as a "chunk of code" that is evaluated at each vertex in a (logically) parallel manner. In this way, the computation happens from the "perspective" of the vertices and thus, the name vertex-centric computing. Another term for this distributed computing model is bulk synchronous parallel. The vertex program's chunk does three things in a while(!terminated)-loop:
- It reads messages sent to its vertex.
- It alters its vertex's state in some way.
- It sends messages to other vertices (adjacent or otherwise)
The vertex program typically terminates when there are no more messages being sent. TraversalVertexProgram is a particular vertex program distributed with Apache TinkerPop™ that knows how to evaluate a Gremlin traversal using message passing. The chunk of code is (logically) distributed to each vertex which contains a Traversal.clone() (a worker traversal). A vertex receives traverser messages that reference a step in the traversal clone. That step is evaluated. If the result is a traverser that does not reference data at the local vertex, then the traverser is messaged away to where that data is. This process continues until no more traverser messages exist in the computation. Besides the distributed worker traversals, there also exists a single master traversal that serves as the coordinator of the computation -- determining when the computation is complete and handling global barriers that synchronize the workers at particular steps in the traversal.
Worker Graph Partitions
The graph data structure ingested by any OLAP GraphComputer is an adjacency list. Each entry in this list represents a vertex, its properties, and its incident edges. In TinkerPop, a single vertex entry is known as a StarVertex. Thus, the adjacency list read by a graph processor can be abstractly defined as List. Typically, a graph processor supports parallel execution whether parallelization is accomplished via threads in a machine, machines in a cluster, or threads in machines in a cluster. Each parallel worker processes a subgraph of the entire graph called a graph partition. The partitions of the graph's adjacency list are abstractly defined as List<List>. If the list is partitions and there are n-workers, then partitions.size() == n and worker i is responsible for processing partitions.get(i).
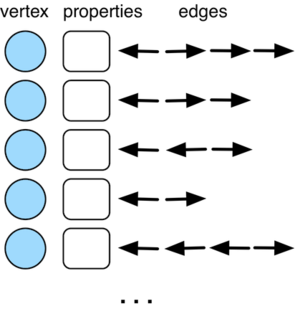
What does worker i do with its particular List-partition? The worker will iterate through the list and for each StarVertex it will process any messages associated with that vertex. For TraversalVertexProgram, the messages are simply Traversers. If the traverser's current graph (data) location is v[1], then it will attach itself to v[1] and then evaluate its current step (instruction) location in the worker's Traversal.clone(). That step will yield output traversers according to it form: one-to-many, many-to-one, one-to-one, etc. If the output traversers reference objects at v[1], then they will continue to execute. For instance, outE() will put a traverser at every outgoing incident edge of v[1], where these incident edges are contained in the StarVertex data structure. Moreover, values("name") will put a traverser at the String name of v[1]. There are three situations that do not allow the traverser to continue its processing at the current StarVertex.
- The traverser no longer references a step in
Traversaland at which point it halts. If this occurs, this means the traverser has completed its journey through the graph and traversal and it is stored in a special vertex property calledHALTED_TRAVERSERScontaining all the traversers that have halted at the respectiveStarVertex. A halted traverser is a subset of the final result. - The traverser no longer references an object at the local
StarVertexand thus, must turn itself into a message and transport itself to theStarVertexthat it does reference. The traverser detaches itself and serializes itself across the network (or stored locally if theStarVertexin question is accessible at the current worker's partition). - The traverser no longer references any data object and thus, is considered dead and is removed from the computation. This occurs when the previous graph location of the traverser is deemed not acceptable by the traversal.
This message passing process continues for all workers until all traversers are either destroyed or halted. The final answer to the traversal query is the aggregation of all the graph locations of the halted traversers distributed across the HALTED_TRAVERSERS of the vertices.
Barrier Synchronization
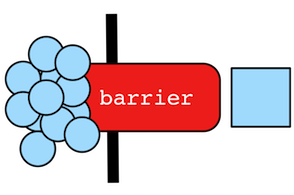
There are some steps whose computation can not be evaluated in parallel and require an aggregation at the master traversal. Such steps implement an interface called `Barrier` and include count(), max(), min(), sum(), fold(), groupCount(), group(), etc. Barrier steps are handled in a special way by the TraversalVertexProgram. When a traverser enters a barrier step at a worker traversal, it does not come out the other side. Instead, Barrier.nextBarrier() is used to grab all the traversers that were barriered at the current worker and then they are sent to the master traversal for aggregation along with other sibling worker barriers of the analogous step. For ReducingBarrierSteps, distributed processing occurs to yield a barrier that is not the aggregate of all traversers, but instead, an aggregate of their reduced associative/commutative form. For instance, CountStep.nextBarrier() produces a single Long number traverser. The master traversal's representation of the barrier step aggregates all the distributed barriers via Barrier.addBarrier(). Then that master barrier step, like any other step, is next()'d to generate the single traverser from the many. If that single traverser references a graph object, it is messaged to the respective StarVertex for further processing by a worker traversal.
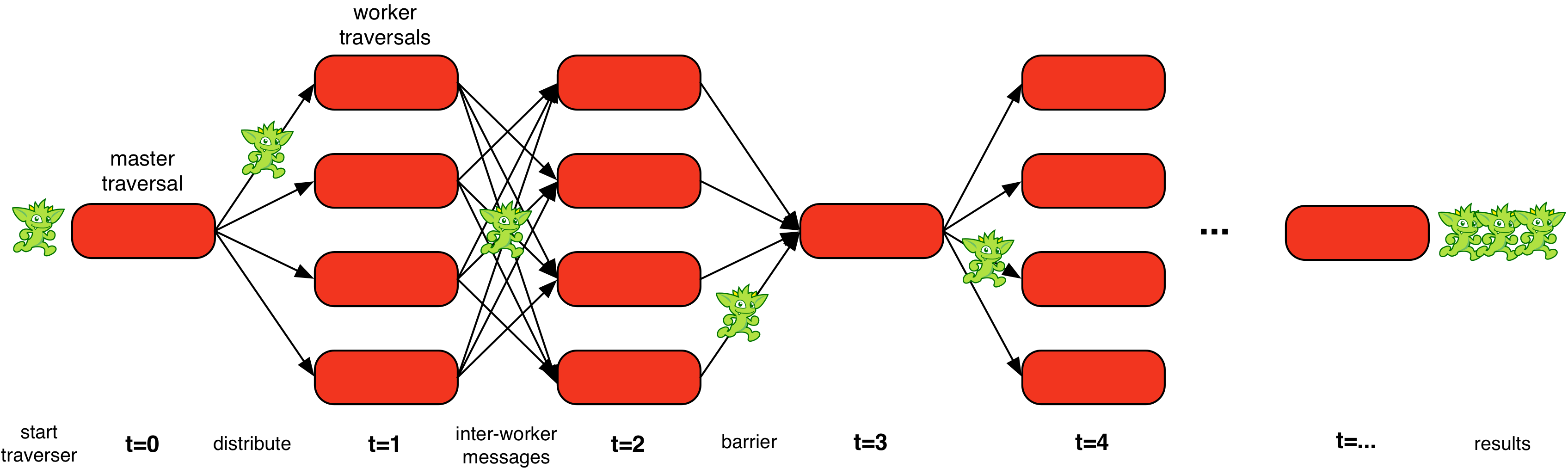
An OLAP traversal undulates from a distributed execution across worker traversal instances, to a local execution at the master traversal, back to a distributed execution across workers, so forth and so on until all traversers have halted and the computation is complete. Note that there are other interesting barrier concepts such as `LocalBarrier` that can be studied by the interested reader in Apache TinkerPop™'s documentation.
The Future of Gremlin OLAP
As of Apache TinkerPop™ 3.2.0, Gremlin OLAP's GraphComputer assumes that the input data is organized as an adjacency list (i.e. List). Moreover, it assumes that each worker processes a subset of that list and that when a traverser leaves the current StarVertex, it must send itself to the respective remote StarVertex that it does reference. These two assumptions can be lifted in order to support GraphComputer implementations that may be more efficient (and/or expressive) for certain types of graphs and traversals.
- Subgraph-Centric Computing: If a single worker partition can hold its entire
Listpartition in memory, then when a traverser leaves the currentStarVertex, it may still be able to execute deeper within the local partition's in-memory subgraph representation. Only when a traverse leaves a partition's subgraph would a message pass be required. This would significantly increase the speed of OLAP at the expense of requiring subgraphs to fit into memory. This model would also benefit greatly from a good partitioning strategy that ensures that worker subgraphs have more inter-partition edges than intra-partition edges. - Edge-Centric Computing: A single
StarVertexmay contain a significant amount of data especially as the graph grows. For example, famous people on Twitter can have on the order of 10 million+ incoming follows-edges. In order to reduce the memory requirements of the OLAP processor as well as to better load balance a computation across machines, an edge-centric model can be used where the OLAP ingested graph is an edge-list abstractly defined asList.
Both these models may one day be introduced into the current GraphComputer model. If so, Apache TinkerPop™ would support vertex-centric, subgraph-centric, and edge-centric computing spanning the gamut of useful distributed graph computing models. Fortunately, the user would be blind to the underlying execution algorithm. Behind the scenes, a traversal would infer its space/time-requirements and ask the GraphComputer to use a particular representation best suited for its evaluation.
Conclusion
The TraversalVertexProgram that drives the evaluation of a distributed Traversal is simple, containing only a few hundred lines of code. The complexity of the computation resides in both the vendor's GraphComputer implementation and Apache TinkerPop™'s Traversal implementation. TraversalVertexProgram merely stands between these two constructs routing traversers amongst worker partitions in order to effect a distributed, OLAP-based evaluation of a Gremlin traversal over a TinkerPop-enabled graph processor.
More Technology
View All


