Moving From Cassandra Tables to Search With DataStax: Part 1

David Jones-GilardiDeveloper Relations Engineer

Hi there and welcome to part 1 of a three part series on upgrading our KillrVideo java reference application from Cassandra based tabular searches to using DSE Search.
Here in part 1, we’ll take a look at the “before” picture and how we were previously performing searches. I’ll give some examples of the types of searches and how those were implemented with Cassandra tables. We’ll also talk a little about the “why” of moving to DSE Search.
In part 2, I’ll explain the transition to DSE Search and what considerations I had to take into account along with a before and after code comparison.
Finally, in part 3, we’ll take a look at our results along with some of the more advanced types of searches we can now perform.
Ok, let’s do this
First things first…assumptions!
If it isn’t obvious, we are using the Java based KillrVideo application for reference. If you aren’t familiar with KillrVideo go take a look here to get up to speed. In short, this is a real, open source, micro-service style application that we build and maintain to present examples and help folks understand the DataStax tech stack. It’s also a nice way that I personally get some code time against the stack in a real application as compared to punching out demo apps.
We are using DataStax Enterprise from drivers to cluster. All of the capabilities we’re talking about here are assumed to be within that ecosystem.
Do we really need to use DSE Search?
No. Maybe. Yes? ¯\_(ツ)_/¯
Ok, it depends, but for the most basic searches it isn’t a requirement. As a matter of fact search was already implemented in the Java version without using DSE Search. So, why the change? Mostly it comes down to requirements and the right tool for the job. So, before I get into all of this why don’t we take a look at the various types of searches that exist in KillrVideo.
In KillrVideo, you can get details and play any video from the video detail page. A quick look at the whole page and you can see all of the available searches. At the top left is the “typeahead” search bar, over to the right are the tag search buttons, and at the very bottom is the “more videos like this” search.
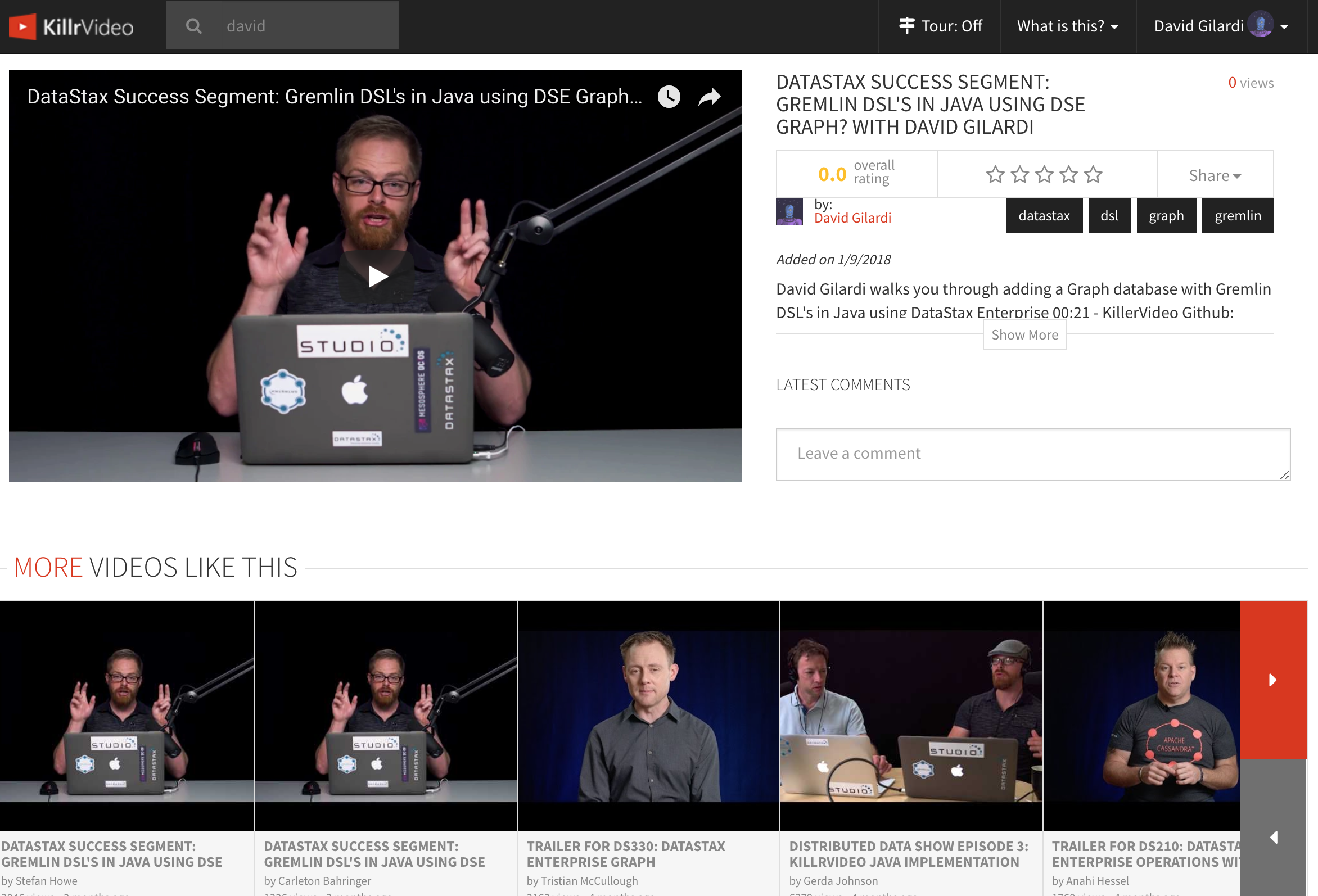
“Typeahead” search
So, nothing new here really. These types of searches have been around for quite some time. Start typing letters in the search bar and you are provided with a list of potential matches

Tag search
This next one is pretty straightforward as well. If you click on any of the tag buttons on the video detail page it will perform a search for other videos with the same tag.
“More videos like this” search
At the bottom of the video detail page is a section labeled “More Videos Like This”. This search will happen automatically when you navigate to any video and present a set of videos that are similar to the video you are currently viewing.

Let’s take a look at the implementation
Remember I mentioned before moving to using DSE Search these were all powered with Cassandra tables. Let’s break some of this down and take a look at some details. Also, if you are interested check out this pull request up on github. You can use this as a reference of the before and after changes if you so choose.
Overview
So overall the setup is pretty simple. We have 3 searches that are supported by a combination of 3 Cassandra tables (the number of searches and tables just happen to match, there is no correlation between them), 3 table entities that map to our Cassandra tables, and 3 mapping objects derived from our table entities. Here is a simple visual representation.

Now, I’m really pointing out these particular items because they will come into play later once we move to using DSE Search, namely, we will need to remove most of them. We’ll leave that there for now and come back to it later.
Of the 3 tables I just mentioned 2 of them exist only to support Cassandra based searches in KillrVideo, tags_by_letter and videos_by_tag. They follow the denormalized data model pattern we’ve come to love in Cassandra and were created solely to support this purpose. The videos table stores all videos inserted into KillrVideo. It is not specialized to Cassandra based searches and will come into play a little later.
I just mentioned that both tags_by_letter and videos_by_tag were specially created to support searches within KillrVideo. Let’s take a deeper look at both tables and see what’s going on. If you aren’t familiar with primary keys in Apache Cassandra® I highly suggest you take 5 minutes to read Patrick McFadin’s post on their importance. This will better explain how they are applied below.
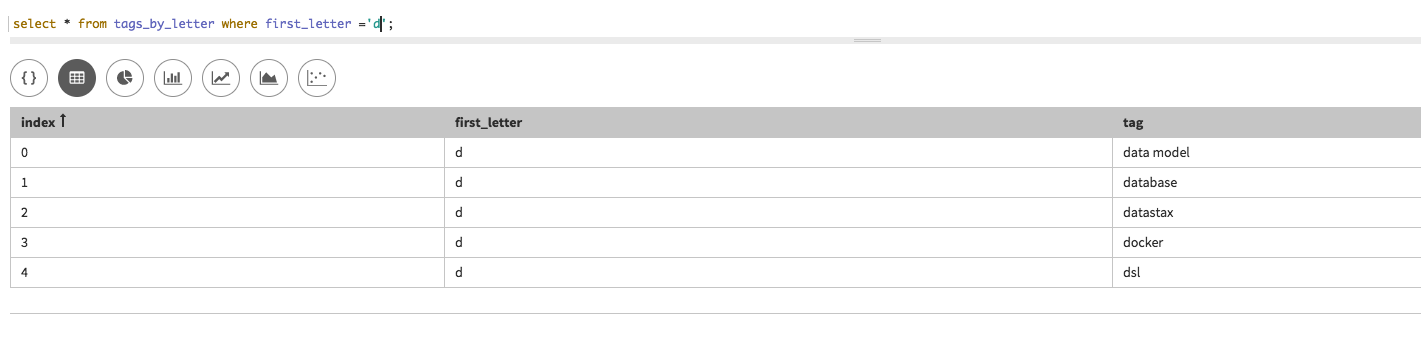
Here is the CQL schema for the tags_by_letter table:
CREATE TABLE IF NOT EXISTS tags_by_letter (
first_letter text,
tag text,
PRIMARY KEY (first_letter, tag)
);
The first_letter column is the partition key with tag as a clustering column. The partition key determines where data is located in your cluster while clustering columns handle how data is ordered within the partition. This is especially useful in cases like a “typeahead” search where searches typically start with the first letter of a given search term and usually provide an alphabetical list of results. This, in a sense, pre-optimizes query results and prevents us from having to sort our data, whether in query execution or code.
Just to absolutely belabor this point (because who doesn’t like belaboring something) here is an example of this in action. Notice how the results are sorted automatically per the tag column with no sorting or extra commands needed in the query.
Moving on, here is the CQL schema for the videos_by_tag table:
CREATE TABLE IF NOT EXISTS videos_by_tag (
tag text, videoid uuid,
added_date timestamp,
userid uuid,
name text,
preview_image_location text,
tagged_date timestamp,
PRIMARY KEY (tag, videoid)
);
Again, this table was specially created to answer the question of what videos have a specified tag. It uses tag as the partition key which allows for fast retrieval of videos that match a tag when querying. The other fields you see listed are there to provide information required by our web tier UI.
VideoAddedHandlers
Another portion we need to keep an eye on is the VideoAddedHandlers class. As the name implies this class is responsible for performing some action(s) every time a video is added to KillrVideo. If you take a look at the two prepared statements within the init() method you should notice they are inserting data into the 2 search tables we mentioned above tags_by_letter and videos_by_tag.
videosByTagPrepared = dseSession.prepare(
"INSERT INTO " + Schema.KEYSPACE + "." + videosByTagTableName + " " +
"(tag, videoid, added_date, userid, name, preview_image_location, tagged_date) " +
"VALUES (?, ?, ?, ?, ?, ?, ?)"
);
tagsByLetterPrepared = dseSession.prepare(
"INSERT INTO " + Schema.KEYSPACE + "." + tagsByLetterTableName + " " + "
(first_letter, tag) VALUES (?, ?)"
);
Every time a video is added these queries are fired off to power our searches. Notice some of the column names, things like “tag” and “first_letter”. Again, we will dig into the detailed logic here soon.
Detailed logic here soon
Alrighty, so, we’ve gone over a high level overview of the various items and objects we are using to support our Cassandra based searches. Now, let’s get into the searches themselves and see what they are doing.
“Typeahead” search
As I mentioned above the typeahead search simply takes the values the user types into the search bar and provides search suggestions based off of the sequence of letters typed in usually with a wildcard attached to the end of the sequence. An example is something like “d” which might return “database”, “decision”, “document”, etc… Then, if the user continues with something like “da” could be “database”, “databases”, “datastax”, etc… and so on.
In the Cassandra based search case this is supported by the tags_by_letter table. Every time a video is added the related subscriber method in the VideoAddedHandlers class is called and ALL tags are inserted along with the first letter of the tag into their respective columns. Since multiple tags are allowed this means we end up looping through and batching up all commands for each tag.
Then, when a user starts typing into the search bar we have the following query to get our results:
SELECT tag FROM tags_by_letter WHERE first_letter = ? AND tag >= ?
Which returns all tags that match the query string from our search. We loop through those results and send our tags back to the UI. Pretty simple.
Remember I previously mentioned the first_letter column is the partition key and tag is the clustering column which handles data ordering. This is where this all comes into play.
At this point I’d like to point out that we are working only with tags. Neither the name or description of any videos are considered. Sure, we could add support for this in our data model and code if we really wanted to, but it is something we have to explicitly take into account if we want that capability.
Tag search
Ok, let’s move to the tag based search. This one is pretty straightforward. Click on a tag button in the video details page and return all videos that have the same tag. This search is supported by the videos_by_tag table. Every time a video is added the related subscriber method in the VideoAddedHandlers class is called and an entry is made for each tag associated with the video. If a video has one tag there will be a single entry, if it has 5 there will be 5 entries, and so on. Note that the videos_by_tag table is optimized specifically for this task.
If you click on a tag button the following query is executed:
SELECT * FROM videos_by_tag WHERE tag = ?
Which returns all videos that match the tag provided in the query. We send these back to the UI which provides a list of videos for you to choose from.
“More videos like this” search
The related videos or “More videos like this” section is very similar to the tag search. The difference in this case is instead of matching only to the selected tag this search will find videos that match all tags of the selected video. So, if my selected video has tags of “datastax”, “dsl”, “graph”, and “gremlin” then the search will return videos that include any of those. It uses the same query as the tag search above. The only difference is we’ll perform a query for each tag that exists with the video and combine the results.
A couple things to point out
For one, notice how our tables and searches work in lock-step. The tables were created to support a particular set of searches or “questions” asked by our application UI and our code supports whatever CRUD operations are needed to maintain the data we use for searches. Essentially this was all purpose made to fit our search needs exactly in a denormalized fashion. This is quite different from how we may have handled things in the relational world.
Also notice the number of operations needed, mostly on the insert end, to constantly populate the search based tables with data when videos are added to the system. Now, we’re talking about Cassandra here so this is not really that much of an issue, but there is overhead associated with those operations and the code needed to support it.
Why move to DSE Search?
So, what happens now when we want to expand our searches to include more fields separate from tag, provide more varied results, or enable advanced searches? Is there a way we could reduce the number of overall actions and code needed to support our searches and also speed things up? Lastly, can we do this in such a way that does not take a whole rethink of our data model?
Well, I think at this point you know exactly what I’m going to suggest, but you’ll have to wait until part 2 of this series for details.
Oooo…suspense…I know….totally suspenseful
Until then (quite soon honestly), thanks for reading and I hope you got something useful out of part 1. Always feel free to add comments or contact me directly for any thoughts or questions.
Take care :D
Ok, let's do this
Do we really need to use DSE Search?
“Typeahead” search
Tag search
“More videos like this” search
Let's take a look at the implementation
Overview
VideoAddedHandlers
Detailed logic here soon
“Typeahead” search
Tag search
“More videos like this” search
A couple things to point out
Why move to DSE Search?
More Technology
View All
Introducing the DataStax AI Terraform Module


