Powers of Ten – Part II

Stephen Mallette

"'Curiouser and curiouser!' cried Alice (she was so much surprised, that for the moment she quite forgot how to speak good English); 'now I'm opening out like the largest telescope that ever was!"
-- Lewis Carroll - Alice's Adventures in Wonderland
 It is sometimes surprising to see just how much data is available. Much like Alice and her sudden increase in height, in Lewis Carroll's famous story, the upward growth of data can happen quite quickly and the opportunity to produce a multi-billion edge graph becomes immediately present. Luckily, Titan is capable of scaling to accommodate such size and with the right strategies for loading this data, the development efforts can more rapidly shift to the rewards of massive scale graph analytics.
It is sometimes surprising to see just how much data is available. Much like Alice and her sudden increase in height, in Lewis Carroll's famous story, the upward growth of data can happen quite quickly and the opportunity to produce a multi-billion edge graph becomes immediately present. Luckily, Titan is capable of scaling to accommodate such size and with the right strategies for loading this data, the development efforts can more rapidly shift to the rewards of massive scale graph analytics.
This article represents the second installment in the two part Powers of Ten series that discusses bulk loading data into Titan at varying scales. For purposes of this series, the "scale" is determined by the number of edges to be loaded. As it so happens, the strategies for bulk loading tend to change as the scale increases over powers of ten, which creates a memorable way to categorize different strategies. "Part I" of this series, looked at strategies for loading millions and tens of millions of edges and focused on usage of Gremlin to do so. This part of the series will focus on hundreds of millions and billions of edges and will focus on the usage of Faunus as the loading tool.
Note: By Titan 0.5.0, Faunus will be pulled into the Titan project under the name Titan/Hadoop.
100 Million
As a reminder from this article's predecessor, loading tens of millions of edges was best handled with BatchGraph. The use of BatchGraph might also be useful in the low hundreds of millions of edges, assuming that the time of loading related to developmental iteration is not a problem. It is at this point that the decision to use Faunus for loading could be a good one.
Faunus is a graph analytics engine that is based on Hadoop and in addition to its role of being an analytic tool, Faunus also provides ways to manage large scale graphs, providing ETL-related functions. By taking advantage of the parallel nature of Hadoop, the loading time for hundreds of millions of edges can be decreased, as compared to a single threaded loading approach with BatchGraph.
The DocGraph data set "shows how healthcare providers team to provide care". DocGraph was introduced in the previous installment to the Powers of Ten series, where the smallest version of the data set was utilized. As a quick reminder of this data set's contents, recall that vertices in this network represent healthcare providers and edges represent shared interactions between two providers. This section will utilize the "365-day Window", which consists of approximately 1 million vertices and 154 million edges.
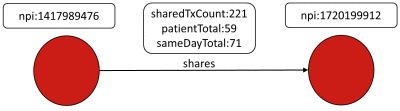
Graphs in the low hundreds of millions of edges, like DocGraph, can often be loaded using a single Hadoop node running in psuedo-distributed mode. In this way, it is possible to have gain the advantage of parallelism, while keeping the configuration complexity and resource requirements as low as possible. In developing this example, a single m2.xlarge EC2 instance was used to host Hadoop and Cassandra in a single-machine cluster. It assumes that the following prerequisites are in place:
- Faunus and Hadoop have been installed as described in the Faunus Getting Started guide.
- Cassandra is installed and running in Local Server Mode.
- Titan has been downloaded and unpacked.
Once the prerequisites have been established, download the DocGraph data set and unpackage it to $FAUNUS_HOME/:
|
|
One of the patterns established in the previous Powers of Ten post was the need to always create the Titan Type Definitions first. This step is most directly accomplished by connecting to Cassandra with the Titan Gremlin REPL (i.e. $TITAN_HOME/bin/gremlin.sh) which will automatically establish the Titan keyspace. Place the following code in a file at the root of called $TITAN_HOME/schema.groovy:
|
|
This file can be executed in the REPL as: gremlin> \. schema.groovy
![]() The DocGraph data is formatted as a CSV file, which means that in order to read this data the Faunus input format must be capable of processing that structure. Faunus provides a number of out-of-the-box formats to work with and the one to use in this case is the ScriptInputFormat. This format allows specification of an arbitrary Gremlin script to write a
The DocGraph data is formatted as a CSV file, which means that in order to read this data the Faunus input format must be capable of processing that structure. Faunus provides a number of out-of-the-box formats to work with and the one to use in this case is the ScriptInputFormat. This format allows specification of an arbitrary Gremlin script to write a FaunusVertex, where the FaunusVertex is the object understood by the various output formats that Faunus supports.
The diagram below visualizes the process, where the script defined to the ScriptInputFormat will execute against each line of the CSV file in a parallel fashion, allowing it to parse the line into a resulting FaunusVertex and related edges, forming an adjacency list. That adjacency list can then be written to Cassandra with the TitanCassandraInputFormat.
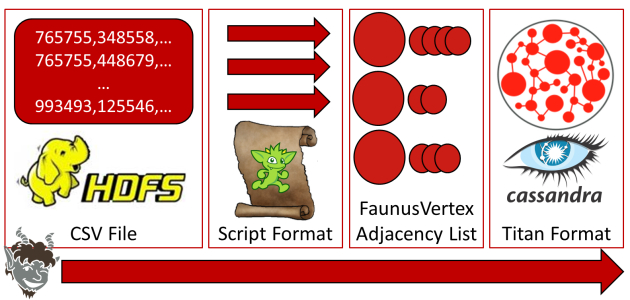
The following script contains the code to parse the data from the CSV file and will be referred to as $FAUNUS_HOME/NPIScriptInput.groovy
|
|
![]() The most important aspect of the code above is the definition of the
The most important aspect of the code above is the definition of the read function at line ten, where the FaunusVertex and a single line from the CSV file are fed. This function processes the CSV line by splitting on the comma separator, setting the property on the supplied FaunusVertex and creating the edge represented by that CSV line. Once the script is created to deal with the input file, attention should be turned to the Faunus properties file (named $FAUNUS_HOME/faunus.properties):
|
|
![]() The above properties file defines the settings Faunus will use to execute the loading process. Lines two through five specify the input format and properties related to where the source data is. Note that the file locations specified are representative of locations in Hadoop's distributed file system, HDFS, and not the local file system. Lines eight through fourteen focus on the output format, which is a
The above properties file defines the settings Faunus will use to execute the loading process. Lines two through five specify the input format and properties related to where the source data is. Note that the file locations specified are representative of locations in Hadoop's distributed file system, HDFS, and not the local file system. Lines eight through fourteen focus on the output format, which is a TitanGraph. These settings are mostly standard Titan configurations, prefixed with faunus.graph.output.titan.. As with previous bulk loading examples in Part I of this series, storage.batch-loading is set to true.
It is now possible to execute the load through the Faunus Gremlin REPL, which can be started with, $FAUNUS_HOME/bin/gremlin.sh. The first thing to do is to make sure that the data and script files are available to Faunus in HDFS. Faunus has built-in help for interacting with that distributed file system, allowing for file moves, directory creation and other such functions.
|
|
Now that HDFS has those files available, execute the Faunus job that will load the data as shown below:
|
|
At line one, the FaunusGraph instance is created using the docgraph.properties file to configure it. Line three, executes the job given the configuration. The output from the job follows, culminating in EDGES_WRITTEN=154568917, which is the number expected from this dataset.
The decision to utilize Faunus for loading at this scale will generally be balanced against the time of loading and the complexity involved in handling parallelism in a custom way. In other words, BatchGraph and custom parallel loaders might yet be good strategies if time isn't a big factor or if parallelism can be easily maintained without Hadoop. Of course, using Faunus from the beginning will allow the same load to scale up easily, as converting from a single machine pseudo-cluster, to a high-powered, multi-node cluster isn't difficult to do and requires no code changes for that to happen.
1 Billion
In terms of loading mechanics, the approach to loading billions of edges, is not so different from the previous section. The strategy for loading is still Faunus-related, however a single machine psuedo-cluster is likely under-powered for a job of this magnitude. A higher degree of parallelism is required for it to execute in a reasonable time frame. It is also likely that the loading of billions of edges will require some trial-and-error "knob-turning" with respect to Hadoop and the target backend store (e.g. Cassandra).
The Friendster social network dataset represents a graph with 117 million vertices and 2.5 billion edges. The graph is represented as an edge list, where each line in the CSV file has the out and in vertex represented as a long separated by a colon delimiter. Like the previous example with DocGraph, the use of ScriptInputFormat provides the most convenient way to process this file.
In this case, a four node Hadoop cluster was created using m2.4xlarge EC2 instances. Each instance was configured with eight mappers and six reducers, yielding a total of thirty-two mappers and twenty-four reducers in the cluster. Compared to the single machine pseudo-cluster used in the last section, where there were just two mappers and two reducers, this fully distributed cluster has a much higher degree of parallelism. Like the previous section, Hadoop and Cassandra were co-located, where Cassandra was running on each of the four nodes.
As the primary difference between loading data at this scale and the previous one is the use of a fully distributed Hadoop cluster as compared to a pseudo-cluster, this section will dispense with much of the explanation related to execution of the load and specific descriptions of the configurations and scripts involved. The script for processing each line of data in the Friendster dataset looks like this:
|
|
The faunus.properties file isn't really any different than the previous example except that it now points to Friendster related files in HDFS in the "input format" section. Finally, as with every loading strategy discussed so far, ensure that the Titan schema is established first prior to loading. The job can be executed as follows:
|
|
The billion edge data load did not introduce any new techniques in loading, but it did show that the same technique used in the hundred million edge scale could scale in a straight-forward manner to billion edge scale without any major changes to the mechanics of loading. Moreover, scaling up Faunus data loads can really just be thought of as introducing more Hadoop nodes to the cluster.
Conclusion
 Over the course of this two post series, a number of strategies have been presented for loading data at different scales. Some patterns, like creating the Titan schema before loading and enabling
Over the course of this two post series, a number of strategies have been presented for loading data at different scales. Some patterns, like creating the Titan schema before loading and enabling storage.batch-loading, carry through from the smallest graph to the largest and can be thought of as "common strategies". As there are similarities that can be identified, there are also vast differences ranging from single-threaded loads that take a few seconds to massively parallel loads that can take hours or days. Note that the driver for these variations is the data itself and that aside from "common strategies", the loading approaches presented can only be thought of as guidelines which must be adapted to the data and the domain.
Complexity of real-world schema will undoubtedly increase as compared to the examples presented in this series. The loading approach may actually consist of several separate load operations, with strategies gathered from each of the sections presented. By understanding all of these loading patterns as a whole, it is possible to tailor the process to the data available, thus enabling the graph exploration adventure.
Acknowledgments
Dr. Vadas Gintautas originally foresaw the need to better document bulk loading strategies and that such strategies seemed to divide themselves nicely in powers of ten.
More Technology
View All
Introducing the DataStax AI Terraform Module


