Property Graph Modeling with an FU Towards Supernodes

Adron Hall

Some notes along with this talk. Which is about ways to mitigate super nodes, partitioning strategies, and related efforts. Jonathan’s talk is vendor neutral, even though he works at DataStax. Albeit that’s not odd to me, since that’s how we roll at DataStax anyway. We take pride in working with DSE but also with knowing the various products out there, as things are, we’re all database nerds after all. (more below video)
In the video, I found the definition slide for super node was perfect.

See that super node? Wow, Florida is just covered up by the explosive nature of that super node! YIKES!
In the talk Jonathan also delves deeper into the vertexes, adjacent vertices, and the respective neighbors. With definitions along the way, so it’s a great talk to watch even if you’re not up to speed on graph databases and graph math and all that related knowledge.

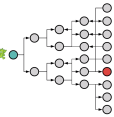
The super node problem he continues on to describe have two specific problems that are detailed; query performance traversals and storage retrieval. Such as a Gremlin traversal (one’s query), moving along creating traversers, until it hits a super node, where a computational explosion occurs.
Whatever your experience, this talk has some great knowledge to expand your ideas on how to query, design, and setup data in your graph databases to work against. Along with that more than a few elements of knowledge about what not to do when designing a schema for your graph data. Give a listen, it’s worth your time.
More Technology
View All
Introducing the DataStax AI Terraform Module


