Rapid read protection in Cassandra 2.0.2

Jonathan EllisTechnology

Rapid read protection allows Cassandra to tolerate node failure without dropping a single request. We designed it for 2.0, but it took some extra time to get the corner cases worked out. It's finished now for the upcoming Cassandra 2.0.2 release.
It's easier to explain how it works after showing what it does. Here's a graph of a small four-node Cassandra cluster with three replicas being stress-tested with five different rapid read protection settings, and one with none at all:
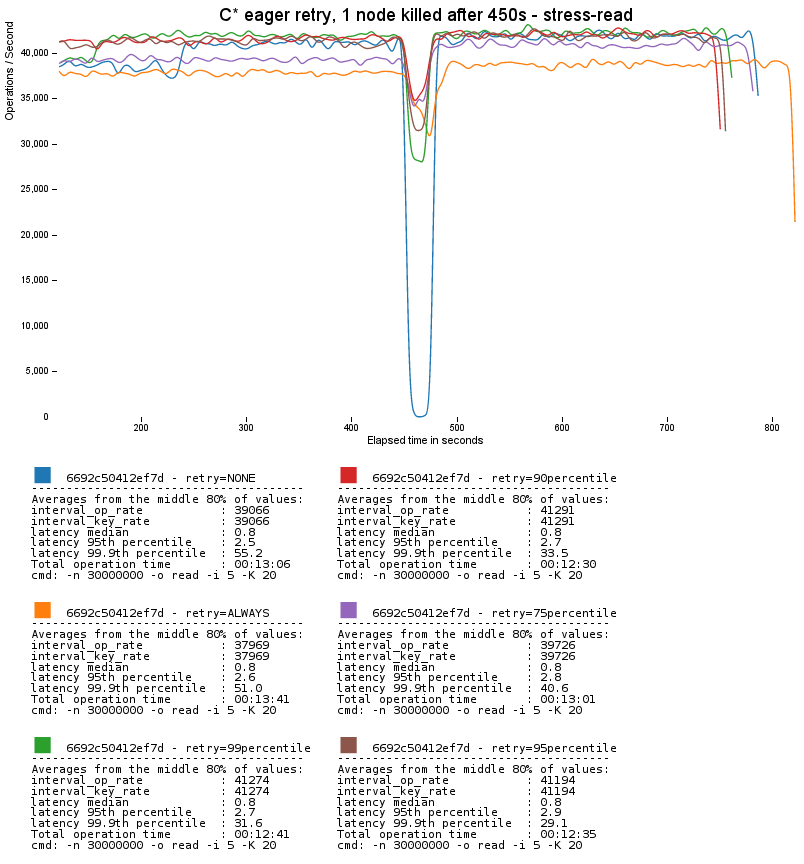
The dip is where we killed one of the nodes with prejudice. With rapid read protection disabled, traffic comes to a standstill until failure detection takes the dead node out of service for client requests.
Why is there a disruption without rapid read protection?
Cassandra performs only as many requests as necessary to meet the requested ConsistencyLevel: one request for ConsitencyLevel.ONE, two for ConsistencyLevel.QUORUM (with three replicas), and so forth. Cassandra uses the dynamic snitch to route requests to the most-responsive replica.
In this diagram, we see the client asking a Cassandra node for some data (1). This node, the request coordinator, then routes it to the best-performing replica (2), then relays the response back to the client (3, 4).
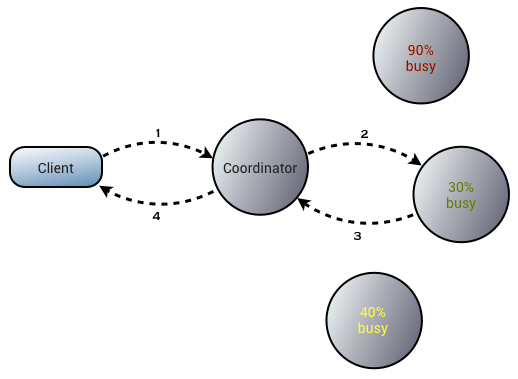
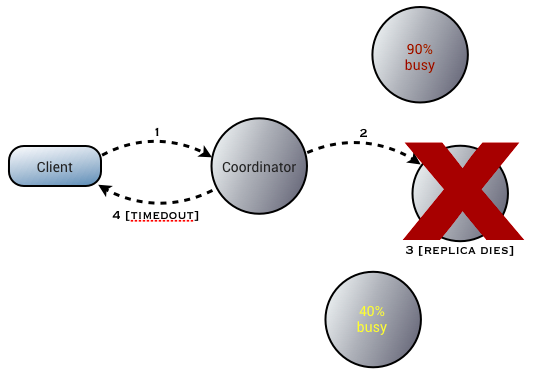
This gives Cassandra maximum throughput, but at the at the cost of some fragility: if the replica to which the request is routed fails before responding, the request will time out:
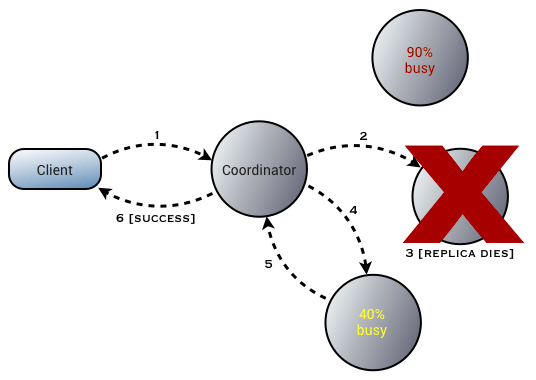
Rapid read protection allows the coordinator to monitor the outstanding requests and send redundant requests to other replicas when the original is slower than expected:
Configuring rapid read protection
Rapid read protection can be configured to do retry after a fixed period of milliseconds or after a percentile of the typical read latency (tracked per table). For example,
ALTER TABLE users WITH speculative_retry = '10ms';
Or,
ALTER TABLE users WITH speculative_retry = '99percentile';
(For those familiar with Hadoop, this is similar to speculative execution, applied to much shorter request latencies. It is the same idea as Jeff Dean's hedged requests, which with all due respect is an even worse name. There are two hard problems in Computer Science...)
By default, 2.0.2 will use 99th percentile. This is a good balance between not performing a lot of extra requests (only 1% more than with no protection at all) while still dealing with the worst problems. As you can see above, extra requests are not free; the more prolific retry settings of 75% and ALWAYS have noticeably lower throughput.
90th percentile can also be a reasonable setting to be more aggressive about reducing latency (see below) while still having a relatively small impact on throughput.
Reducing latency variance with rapid read protection
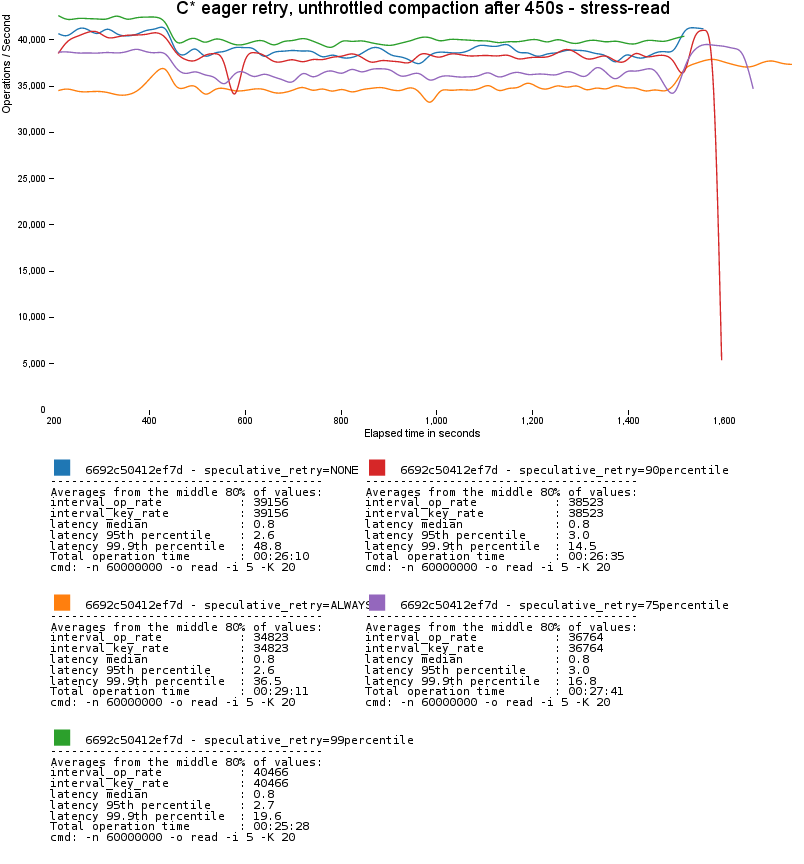
Rapid read protection also helps reduce latency variance in the face of less drastic events than complete node failure. Here's a scenario where we start a full, un-throttled compaction across the cluster. Throughput doesn't improve dramatically since all replicas are equally affected, but notice how much better 99.9th% latency is with with rapid read protection:
Some more subtle points
- Rapid read protection does not help at all with ConsistencyLevel.ALL reads, since there are no "other replicas;" responses from all replicas are required by definition.
- When the node is killed in the first graph, throughput still dips with read protection. This is because in our small four node cluster, we've lost 25% of our capacity and have to redo those requests almost all at once, causing a brief load spike on the surviving nodes. The larger your cluster is, the smaller the impact will be. (Another benefit to spreading replication throughout the cluster with virtual nodes.)
- If you look closely, you'll see that the throughput in the first graph actually recovers to a higher level than initially. This is because we've forced random replica choice to eliminate the dynamic snitch's influence here, so we go from about 1/4 of reads being satisfied locally on the coordinator node to about 1/3.
- In the last graph, latency variance is actually higher for the ALWAYS setting. This is because so many extra reads has pushed us up against our cluster's capacity ceiling. ALWAYS is only recommended if you're sure you'll have the capacity to spare!
More Technology
View All
Introducing the DataStax AI Terraform Module


