

Real-Time AI Done Right: Timely Insight and Action at Scale
In my previous blog post, I laid out the challenges of current AI architectures and the inherent limitations they impose on data scientists and developers. These challenges inhibit our ability to take advantage of the growth in real-time data, address increased consumer expectations, adapt to increasingly dynamic markets, and deliver proven real-time business outcomes. In short, even as AI has delivered some great benefits, it continues to fall short due to:
- Directional forecasting based on broad demographic data that fails to deliver the kind of insights needed to change behavior and drive impact.
- Batch processing and historical analysis that can’t keep pace with rapidly evolving consumer demands.
- Time, cost, and complexity that delays how quickly we can learn new patterns and take actions to meet the needs of evolving markets.
- Lack of visibility across teams and the varying stack of tools that further complicates and delays AI practitioners as they attempt to build applications that deliver value.
Simply put, this out-of-date model of bringing data to your ML/AI systems cannot deliver the type of results needed at the speed required for businesses and consumers. But there is a better way to deliver real-time impact and drive value through AI.
Let’s now explore how organizations can transcend these limitations and join the ranks of businesses that bring their ML to the data to deliver more intelligent applications, with more accurate AI predictions at the exact time to make the biggest business impact.
Rethinking data architecture to drive impact with AI
With real-time AI, it is now possible for developers to build AI powered applications that go beyond predicting behavior to driving actions—at the exact moment it could make the biggest impact. Instead of limitations, with real-time AI you now have possibilities – everything from changing consumer behavior at an individual level, through insights into user intention and context, to taking preventive action that protects manufacturing uptime and supply chain resiliency. Move away from the world where you say, based on a broad demographic understanding of users, this is the percent of users who will churn, and move to a model where you can understand a specific individual and drive decisions, in the moment, to increase engagement.
Making this shift requires changing how AI systems are built. The majority of AI today is based on massive volumes of historical data, delivered in batches collected daily or sometimes weekly. The result is a rear-view-mirror look at historical behavior based on broad patterns and demographics. With real-time AI, you connect to the series of events as they unfold, making it possible to instantly discover key moments, signals, and outcomes as they occur. The result is a highly personalized understanding of consumer behavior, security threats, systems performance, and more, along with the ability to intervene to change outcomes.
For example, the goal of a music application isn’t just to serve the right content, but rather to serve up personalized, engaging content that will make the user stick around longer, explore new areas of music, new artists, and new genres, and keep them so engaged that they renew their subscription. What’s needed is for that app to serve up music not just based on the user’s history, but based on the user’s intention in the application while they are actively engaged.
Think of the listener who has been working all morning to instrumental music that helps with productivity, but now it’s noon and they’re headed to the gym. They want tunes to help motivate them. If the application continues to serve up Beethoven when the user wants to work out to Beyoncé, then the application has fallen short, putting the burden—and potential frustration—on the user to search.
So how can the application detect that shift in intention while the user is in the application? This can be revealed through real-time behaviors and actions. It may be that the user leaves a song they have been listening to and scrolls around selections based on a ranking algorithm, but doesn't make a selection. The user then moves on to one of the carousels served up by the app, but again doesn’t choose any of the options because they were all podcasts. And maybe they then play a song from one of their old workout playlists. Additionally, context matters; it can be gleaned from factors such as the day of the week, or the time of the day and even the location of the user. Now, armed with intent and context, the real-time ML model can more accurately predict content that is desired, now, in session.
Once deployed to the application, real-time AI relies on feature freshness and low latency—how recently were the features updated and how quickly can the application then take action. The right infrastructure eliminates response lag and enables more efficient use of resources with just-in-time computation of these features to get predictions only for active users. This experience provides the listener what they need when they need it, which will drive engagement and an ultimate goal of subscription renewal.
Flexibility and responsiveness
Real-time AI is built for speed and scale; it enables the delivery of the right data on the right infrastructure at the right time. This in turn enables the capture of opportunities in context to train models on historical and real-time data to make more accurate, time-sensitive decisions.
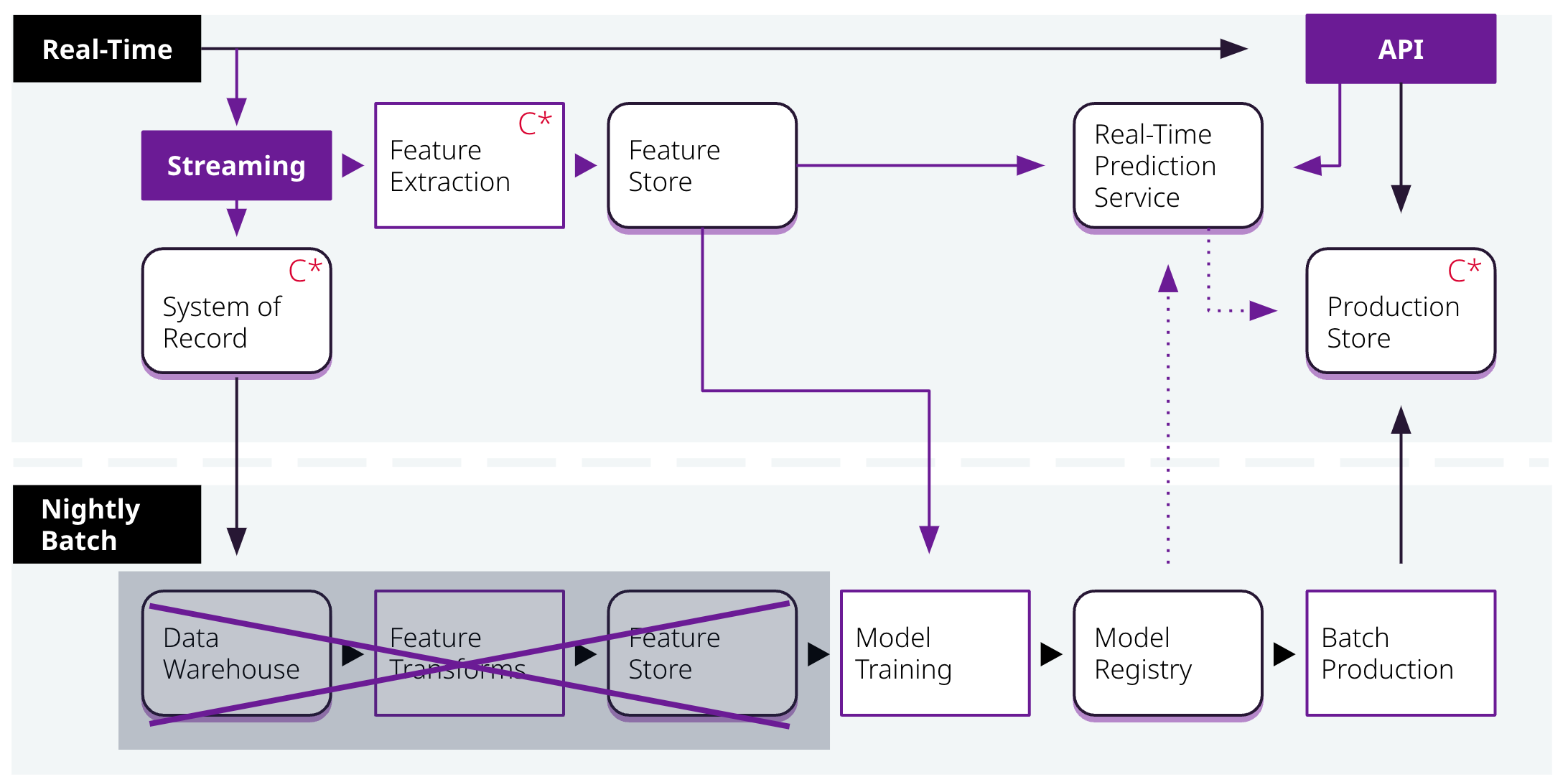
In the most advanced case, real-time AI enables monitoring of the performance of ML models. If the performance of the model dips, it triggers an automatic retraining. Alternatively, “shadow” models can be trained, and if they begin to perform better than the model that’s in production, they can be swapped in for the underperforming model.
Real-time AI also makes it easier to ensure that all demographics are treated equally, allowing monitoring and the ability to adjust for unintended consequences in real-time. Imagine a model in production that begins to fail fairness and bias tests. In real-time, businesses could flip a model out of production and fall back on a rules-based system or a model that represents the standards and guidelines of the business. This is an approach that delivers the flexibility and responsiveness required in a high-stakes context that is changing dynamically.
Reduce time, cost, and complexity
One of the major limitations of traditional AI is the massive effort and costs associated with data transfers and storage. In contrast, bringing ML capabilities to the data itself saves time, cost, and complexity by eliminating these data transfers because with a simplified architecture, you get a single environment to process your event data, features, and models that instantaneously ingest data at scale. In addition, speed and productivity are increased by simplifying complexity and increasing understandability of feature and training data set lineage. In other words, there’s more clarity and visibility into what has happened across multiple pipelines, lakes, views, and transformations. With access to the direct data source, you accelerate understanding—especially when ramping up a team or individual.
Greater cost savings are unlocked by eliminating the need to generate daily predictions across an entire customer base, as many customers are not active every day. If, say, an organization uses a batch system and has 100,000 active daily users, versus 100 million who are going to be active on a monthly basis, it shouldn’t be necessary to rescore 100 million customers every night. To do so adds unneeded and significant costs. And the costs incurred to store this data just keep increasing.
Retraining models to incorporate behavior changes requires either the retention of or the ability to reproduce every training dataset to enable troubleshooting and auditing. To reduce the amount of data duplicated and stored over time, each time a model is retrained, you should be able to access the original, non-transformed version of the data, and be able to reproduce the training datasets with the version of the features used during training. This is exceedingly difficult with a batch system, because data has gone through so many transformations across several systems and languages. In a real-time system, expressing a full feature directly from raw events for training and production makes it possible to reduce the amount of duplications of all of the data that you would normally need stored in multiple places.
Bringing AI/ML to the data source creates a single method of expressing transformations. You can now know you are connected to the right source, you know this is the exact definition of the transformation, and you can more succinctly express what’s needed in the data transformation in a few lines of code—not pipeline to pipeline to pipeline, with the confusion involved in those multiple transfers.
Reduce friction and anxiety
As pointed out in my previous blog post, it is often the case that wide visibility or deep understanding of an ML project is out of reach to team members spanning the data, ML, and application stack. And the tools vary widely based on team members’ place in the stack.
These silos inject friction and confusion into the process and produce a lot of anxiety around questions like, “is this production-ready?” “Is this going to work out once we actually put it into production?” Or, “Despite millions of dollars invested, will these models only achieve a minimal impact - far short of the promise or vision to deliver value?”
Bringing AI/ML to the data enables a unified interface with a single set of abstractions to support training and production. The same feature definition can generate any number of train/test datasets and keep a feature store up to date with new data streaming in. In addition, using declarative frameworks enables the export of feature definitions and the resource definitions they depend on to check things into code repos or CI/CD pipelines, and to spin up new environments with new data in a different region without having to transfer the data out of the region. This makes integrating best practices easy, simplifies testing, and reduces the learning curve. This also inherently lowers friction, provides higher visibility and, through a more standardized format, provides a clearer picture of exactly what is happening in a particular set of code.
Real-time AI done right
A real-time AI solution that brings together real-time data at scale with integrated machine learning in a complete, open data stack purpose-built for developers is a new approach. The right stack, with the right abstractions, holds incredible promise to create a new generation of applications that drive more accurate business decisions, predictive operations, and more compelling, more engaging consumer experiences. This has the potential to unlock the value and promise of AI in a way that has been out of reach for all but a select few businesses. This will produce instant access to data at scale in all forms. With integrated intelligence, real-time AI will produce time-sensitive insight for globally distributed operations, data, and users.
In an upcoming blog post, I’ll discuss the critical role of Apache Cassandra® in this real-time AI stack and some of the exciting new things you can expect from DataStax.
More Company
View All
London Called. RAG++, The AI Event, Answered!

DataStax Named a Leader in The Forrester Wave™: Vector Databases, Q3 2024

Live From New York! It’s RAG++, The AI Event
