The Schema Management Renaissance in Cassandra 1.1

Pavel Yaskevich

The code that handles schema changes has recently undergone its second major rewrite, which could respectfully be called its renaissance.
The first major rewrite added online schema changes back in Cassandra 0.7, but it had some weaknesses:
- Schema updates were ordered, and new members of the cluster had to rebuild the schema in that same order, one update at a time. For a cluster with many (thousands) of schema changes, this could add substantial time to bringing new nodes online.
- Update ordering also meant that simultaneous updates could cause the infamous schema disagreement errors, with some nodes applying one change first, and other nodes, the other change. Thus, schema was assumed to be relatively static; applications were discouraged from using temporary columnfamilies or otherwise adjusting schema at runtime.
- Schema was stored in a custom Avro-based serialization format, so even if you were familiar with the system tables involved, you could not inspect the schema via CQL queries. Instead, we had to add custom Thrift RPC methods to return the schema in a format clients could understand.
Cassandra 1.1 introduces next-generation schema management that solves all of these problems. The remainder of this post will explain how this works at a technical level.
What is Schema?
Schema refers to the organization of data to create a blueprint of how a database will be constructed (divided into keyspaces with nested ColumnFamilies (with nested columns)). If you want to dig deeper this post by Jonathan Ellis describes schema in detail.
Example of the Keyspace definition (in a formal language):
Keyspace Standard: {
"ks_attr_1" : "value_1",
"ks_attr_2" : "value_2",
"ks_attr_3" : "value_3",
ColumnFamilies: [
ColumnFamily "1": {
"cf_attr_1" : "value_1",
...,
columns: [
column "1": {"col_attr_1" : "val_1", ...},
...
]
},
...,
ColumnFamily "N": { - // - }
]
}
Dark Ages
There aren't many good things to say about this period. Everything before 0.7.0 is counted as Dark Ages with regard to the schema. Users had to modify conf/storage-conf.xml and define schema in the <Keyspaces> section for every schema change. It was important to keep the same version of <Keyspaces> section on all of the nodes, and no dynamic modifications were possible, meaning that all of the nodes would having to be restarted before any of the new schema could be used.
Middle Ages
In versions between 0.7 and 1.1 Cassandra had following algorithm of schema modification and distribution which replaced static schema:
(on coordinator):
- User initializes schema modification using RPC.
- Thrift-based KsDef/CfDef were converted into KSMetaData and CFMetaData objects respectively and passed to the newly allocated Migration object (actually, to the subclass of the Migration object, one per operation e.g. Add{Keyspace,ColumnFamily}, Update{Keyspace,ColumnFamily}).
- New time-based UUID was calculated and set as a Migration->ID.
- When Migration.apply() is called by migration executor:
- Keyspace/ColumnFamily metadata is updated by replacing with new instance of {KS,CF}MetaData.
- Internal modifications (e.g. created/deleted directories, snapshot etc.).
- System-wide schema version is set to match Migration->ID.
- Current Migration is serialized (internal {KS,CF}MetaData objects are serialized to Avro) and stored into system.Migrations ColumnFamily.
- All non-system KsMetaData objects are serialized (to Avro) and stored into system.Schema to be used to restore the latest schema on startup.
- Migration in the serialized state distributed to all alive nodes in the ring using "push" method to specific handler.
- New version of the schema is passively announced by Gossip.
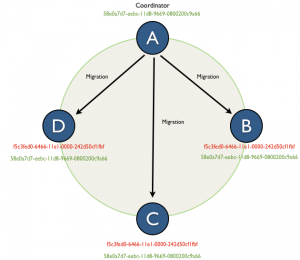
Figure 1. Old schema distribution algorithm when serialized migrations were pushed to the peer nodes.
(on receiving peers):
- Receive a message from coordinator node with serialized Migration.
- Deserialize and apply Migration only if Migration->ID is earlier in time than current schema version otherwise error and leave cluster in possible disagreement.
(on fresh or re-joining nodes):
- On start-up system.Schema is read to determine the lastest version of the schema.
- Deserialize row for the sytem.Schema identified by the schema version from step 1.
- Check if we have the oldest (in time sense) version in the cluster.
- If so, push own migrations to the all alive nodes in the cluster starting from their version and end at local current.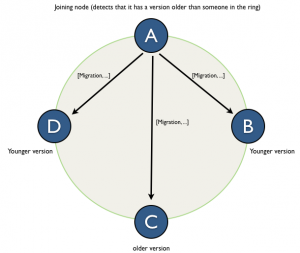
It would be appropriate to give a special note about what "schema version" is - on each of the nodes it is set to match the latest applied migration ID, in other words it is a time-based UUID used to coordinate schema distribution across ring in the naive sequential way.
The main disadvantages:
- Migrations should be applied only sequentially (in the ascending order of the IDs).
- ID collisions are possible as two or more nodes potentially can create Migration at the same time (in millisecond resolution).
- Schema modifications should not be frequent otherwise system won't be able to keep up with migration distribution.
- Almost impossible to coordinate proper schema updates to the new-coming nodes or in the situation when there is "schema disagreement" in the cluster.
- Impossible to query attributes of the specific Keyspace/ColumnFamily programmatically without requesting whole structures using Thrift RPC.
- Storing both migrations and schema snapshots is not optional and wastes disk space.
- New serialization dependency was added to the system.
Renaissance
A major rewrite of how schema changes are handled was made in cassandra 1.1.
First of all, code responsible for tracking the current state of the schema (which was spread to the different classes) was assembled in one dedicated place - Schema class. Next big thing - Avro serialization was dropped, dependency was kept for now because it helps to convert the old schema representation on Cassandra updates. During discussion on the CASSANDRA-1391, a decision was made that the best choice would be to store schema into native storage and serialize attribute names and values using the JSON format for human readability (e.g. it helps with CASSANDRA-2477). Migration objects and schema snapshot serialization were also removed as they became redundant. Upon start-up the nodes would read system.schema_* and re-construct metadata objects accordingly. From the perspective of schema distribution, this would allow them to serialize metadata structures (KsDef/CfDef) into RowMutation objects which are also used for “payload” data distribution across the ring and have the ability to “merge” outdated modifications. After that was settled, the only last two things missing were: a special “merge” mechanism to reload metadata of the Keyspace/ColumnFamily (or create/drop new/deleted Keyspace/ColumnFamily) after the remote RowMutation was applied, and a new method of calculating which schema version should become “content-based” and be calculated as checksum of all rows in the system.schema_* ColumnFamilies.
New algorithm step-by-step (on coordinator):
- User initializes schema modification using RPC or CQL.
- Modified KsDef/CfDef are converted into RowMutation and applied on the native storage (Keyspace: system; ColumnFamilies: schema_keyspaces, schema_columnfamilies, schema_columns).
- Internal modifications (e.g. create/delete directories, snapshot etc.).
- RowMutation from step 2 is distributed to all alive nodes in the ring using "push" method to specific handler.
- Schema version is re-calculated and passively announced via Gossip.
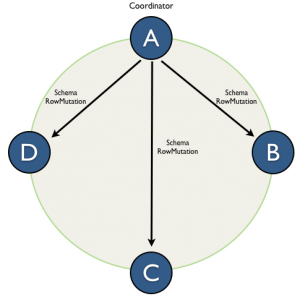
Figure 3. The new way of schema distribution when RowMutations are pushed to the peers by coordinator.
(on receiving peers):
- Receive a message from coordinator node with serialized RowMutation holding modifications.
- Store current schema state to the temporary variables and apply RowMutation from step 1.
- Use special "merge" algorithm which would reload updated attributes and create/drop specific Keyspaces or ColumnFamilies from the system.
- Re-calculate schema version and passively announce it via Gossip.
(on fresh or re-joining nodes):
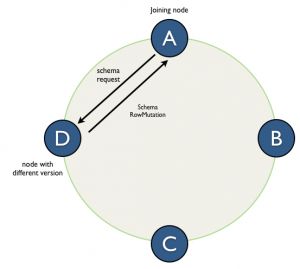
- On start-up calculate and check if the schema version is different from the other nodes in the cluster.
- If so, make a schema request to one of the nodes and when reply is received apply the same steps as (on receiving peers) above.
Figure 4. The new way of requesting/merging schema modifications on the way to schema agreement across the ring.
Conclusion
Schema modification and distribution algorithm with latest modifications included into Cassandra 1.1 was made simpler, more reliable and user-friendly. Users are able to make frequent schema updates without fear that it would cause unresolvable disagreement, modifications are not forced to be sequential and "merge" algorithm takes care of the situations when due to e.g. network failures modifications that were made in the past are propagated in the cluster with delay and applied in incorrect order.
Note
Please note that simultaneously running 'CREATE COLUMN FAMILY' operation on the different nodes wouldn't be safe until version 1.2 due to the nature of ColumnFamily identifier generation, for more details see CASSANDRA-3794.
More Technology
View All
Introducing the DataStax AI Terraform Module


