A Solution to the Supernode Problem

Marko A. Rodriguez

In graph theory and network science, a "supernode" is a vertex with a disproportionately high number of incident edges. While supernodes are rare in natural graphs (as statistically demonstrated with power-law degree distributions), they show up frequently during graph analysis. The reason being is that supernodes are connected to so many other vertices that they exist on numerous paths in the graph. Therefore, an arbitrary traversal is likely to touch a supernode. In graph computing, supernodes can lead to system performance problems. Fortunately, for property graphs, there is a theoretical and applied solution to this problem.
Supernodes in the Real-World
Peer-to-Peer File Sharing
At the turn of the millenium, online file sharing was being supported by services like Napster and Gnutella. Unlike Napster, Gnutella is a true peer-to-peer system in that it has no central file index. Instead, a client's search is sent to its adjacent clients. If those clients don't have the file, then the request propagates to their adjacent clients, so forth and so on. As in any natural graph, a supernode is only a few steps away. Therefore, in many peer-to-peer networks, supernode clients are quickly inundated with search requests and in turn, a DoS is effected.
Social Network Celebrities
President Barack Obama currently has 21,322,866 followers on Twitter. When Obama tweets, that tweet must register in the activity streams of 21+ million accounts. The Barack Obama vertex is considered a supernode. As an opposing example, when Stephen Mallette tweets, only 59 streams need to be updated. Twitter realizes this discrepancy and maintains different mechanisms for handling "the Obamas" (i.e. the celebrities) and "the Stephens" (i.e. the plebeians) of the Twitter-sphere.
Blueprints and Vertex Queries
Blueprints is a Java interface for graph-based software. Various graph databases, in-memory graph engines, and batch-analytics frameworks make use of Blueprints. In June 2012, Blueprints 2.x was released with support for "vertex queries." A vertex query is best explained with an example.
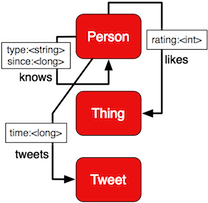 Suppose there is a vertex named Dan. Incident to Dan are 1,110 edges. These edges denote the people Dan knows (10 edges), the things he likes (100 edges), and the tweets he has tweeted (1000 edges). If Dan wants a list of all the people he knows and incident edges are not indexed by label, then Dan would have to iterate through all 1,110 edges to find the 10 people he knew. However, if Dan's edges are indexed by edge label, then a lookup into a hash on
Suppose there is a vertex named Dan. Incident to Dan are 1,110 edges. These edges denote the people Dan knows (10 edges), the things he likes (100 edges), and the tweets he has tweeted (1000 edges). If Dan wants a list of all the people he knows and incident edges are not indexed by label, then Dan would have to iterate through all 1,110 edges to find the 10 people he knew. However, if Dan's edges are indexed by edge label, then a lookup into a hash on knows would immediately yield the 10 people -- O(n) vs. O(1), where n is the number of edges incident to Dan.
The idea of partitioning edges by discriminating qualities can be taken a step further in property graphs. Property graphs support key/value pairs on vertices and edges. For example, a knows-edge can have a type-property with possible values of "work," "family," and "favorite" and a since property specifying when the relationship began. Similarly, likes-edges can have a 1-to-5 rating-property and tweet-edges can have a timestamp denoting when the tweet was tweeted. Blueprints' Query allows the developer to specify contraints on the incident edges to be retrieved. For example, to get all of Dan's highly rated items, the following Blueprints code is evaluated.
|
|
Titan and Vertex-Centric Indices
Blueprints only provides the interface for representing vertex queries. It is up to the underlying graph system to use the specified constraints to their advantage. The distributed graph database Titan makes extensive use of vertex-centric indices for fine-grained retrieval of edge data from both disk and memory. To demonstrate the effectiveness of these indices, a benchmark is provided using Titan/BerkeleyDB (an ACID variant of Titan -- see Titan's storage overview).
10 Titan/BerkeleyDB instances are created with a person-vertex named Dan. 5 of those instances have vertex-centric indices, and 5 do not. Each of the 5 instances per type have a variable number of edges incident to Dan. These numbers are provided below.
| total incident edges | knows-edges |
likes-edges |
tweets-edges |
|---|---|---|---|
| 111 | 1 | 10 | 100 |
| 1,110 | 10 | 100 | 1000 |
| 11,100 | 100 | 1000 | 10000 |
| 111,000 | 1000 | 10000 | 100000 |
| 1,110,000 | 10000 | 100000 | 1000000 |
The Gremlin/Groovy script to generate the aforementioned star-graphs is provided below, where i is the variable defining the size of the resultant graph.
|
|
For the 5 Titan/BerkeleyDB instances with vertex-centric indices, the following code fragment was evaluated. This code defines the indices (see Titan's type configurations).
|
|
Next, three traversals rooted at Dan are presented. The first gets all the people Dan knows of a particular randomly chosen type (e.g. family members). The second returns all of the things that Dan has highly rated (i.e. 4 or 5 star ratings). The third retrieves Dan's 10 most recent tweets. Finally, note that Gremlin compiles each expression to an appropriate vertex query (see Gremlin's traversal optimizations).
|
|
The traversals above were each run 25 times with the database restarted after each query in order to demonstrate response times with cold JVM caches. Note that in-memory, warm-cache response times show a similar pattern (albeit relatively faster). The averaged results are plotted below where the y-axis is on a log scale. The green, red, and blue colors denote the first, second and third queries, respectively. Moreover, there is a light and a dark version of each color. The light version is Titan/BerkeleyDB without vertex-centric indices and the dark version is Titan/BerkeleyDB with vertex-centric indices.
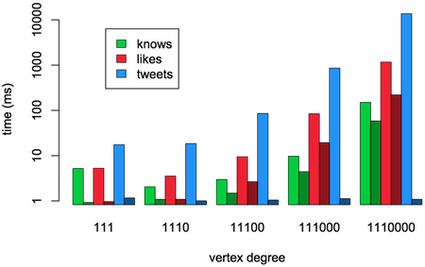
Perhaps the most impressive result is the retrieval of Dan's 10 most recent tweets (blue). With vertex-centric indices (dark blue), as the number of Dan's tweets grow to 1 million, the time it takes to get the top 10 stays constant at around 1.5 milliseconds. Without indices, this query grows proportionate to the amount of data and ultimately requires 13 seconds to complete (light blue). That is a 4 orders of magnitude difference in response time for the same result set. This example demonstrates how useful vertex-centric indices are for activity stream-type systems.
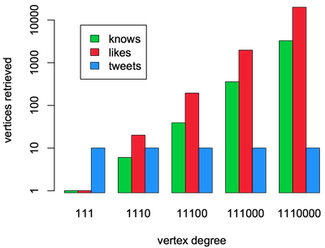 The plot on the right displays the number of vertices returned by each query over each graph size. As expected, the number of
The plot on the right displays the number of vertices returned by each query over each graph size. As expected, the number of tweets stays constant at 10 while the number of knows and likes vertices retrieved grows proportionate to the growing graphs. While the examples on the same graph (with and without indices) return the same data, getting to that data is faster with vertex-centric indices.
Finally, Titan also supports composite key indices. The graph construction code fragment previous assigns a primary key of both type and since to knows-edges. Therefore, retrieving Dan's 10 most recent coworkers is more efficient than, in-memory, getting all of Dan's coworkers and then sorting on since. The interested reader can explore the runtimes of such composite vertex-centric queries by augmenting the provided code snippets.
Conclusion
A supernode is only a problem when the discriminating information between edges is ignored. If all edges are treated equally, then linear O(n) searches through the incident edge set of a vertex are required. However when indices and sort orders are used, O(log(n)) and O(1) lookups can be achieved. The presented results demonstrate 2-5x faster retrievals for the presented knows/likes queries and up to 10,000x faster for the tweets query when vertex-centric indices are employed. Now consider when a traversal is more than a single hop.
![]() The runtimes compound in a combinatoric manner. Compounding at 1 millisecond vs 10 seconds leads to astronomical differences in overall traversal runtime.
The runtimes compound in a combinatoric manner. Compounding at 1 millisecond vs 10 seconds leads to astronomical differences in overall traversal runtime.
The graph database Titan can scale to support 100s of billions of edges (via Apache Cassandra and HBase). Vertices with a million+ incident edges are frequent in such massive graphs. In the world of Big Graph Data, it is important to store and retrieve data from disk and memory efficiently. With Titan, edge filtering is pushed down to the disk-level so only requisite data is actually fetched and brought into memory. Vertex-centric queries and indices overcome the supernode problem by intelligently leveraging the label and property information of the edges incident to a vertex.
Related Material
Rodriguez, M.A., Broecheler, M., "Titan: The Rise of Big Graph Data," Public Lecture at Jive Software, Palo Alto, 2012.
Broecheler, M., LaRocque, D., Rodriguez, M.A., "Titan Provides Real-Time Big Graph Data," Aurelius Blog, August 2012.
More Technology
View All
Introducing the DataStax AI Terraform Module


