Things to Keep In Mind

Robin Schumacher

This is an excerpt from the DataStax whitepaper "Data Modeling in Apache Cassandra™;" which delves into how to choose the right data model for your Apache Cassandra™ application in 5 easy steps. Click here to download the full whitepaper.
Thinking in Relational Terms Can Cause Problems
On the surface, Cassandra’s Query Language (CQL) looks much like SQL but failing to consider how Cassandra stores data can cause serious problems. Consider an example where we decide to partition our user community into groups. We want to be able to retrieve information about all users that belong in a group as shown.

A good table structure to support such a query in Cassandra would use the groupname as a partition key so that members of the same group reside on the same partition for fast lookup.

Someone with a relational database background might be tempted to normalize the database schema by creating tables for users, groups, and user-group relationships as shown.

Now suppose there were 1,000 users in each group, and we wanted to perform the same query retrieving information for all users in a group. In this normalized case, the application would need to read 1,002 partitions—first querying the groups table to retrieve the group_description, then querying the user_groups table to retrieve all userids in the group. After this, the users table needs to be queried for each of the 1,000 userids, each on a separate partition.
Secondary indexes
Consider a table holding user accounts where a unique username identifies an account. The table structure below is ideal for looking up users by username (the partition key).

Now imagine that we need to generate a list of user accounts in a single country. Normally, a query like this would require a full table scan. This is a horrible idea in Cassandra. Depending on the size of the table, a query like this may be very expensive and may consume all the resources on the cluster.
One way to solve this problem is to create another table designed to support the new query, with country designated as the partition key and username as the clustering key. However, such a solution is still problematic because country is a low-cardinality column. As our database scales, we may end up with millions of users in the same country, causing the partition for a country to become very large. In general, we do not recommend creating partitions with more than a few hundred thousand rows. A better practice would be to use a composite partition key with a country, state, city, and so forth to reduce the number of rows per partition.
Another solution, which works better for low-cardinality columns, is to use a secondary index:
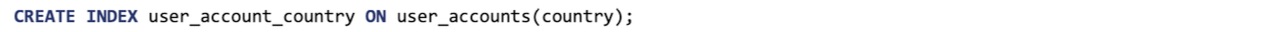
The secondary index allows users to run queries like the following:

This is convenient and looks much like a relational database. So why not always use a secondary index as opposed to creating query-specific tables?
The challenge is how secondary indexes are stored. Replicating a global index for every record on every Cassandra host is not feasible, so instead, Cassandra maintains a secondary index on each host indexing only the data on that host. To use a secondary index to search across all user_accounts in the UK, the query needs to check with every node in the Cassandra cluster, and then use the local index to retrieve only the records where country = “UK”. This is expensive since user accounts stored in the index reside in different partitions, but at least the query only reads records for users known to reside in the UK—far less expensive than a full table scan.
Creating a secondary index on a high-cardinality column like email would be disastrous. Whereas there are only 195 countries, in a table with 100,000,000 rows, every email address would be unique. The index on each host would be enormous, and the amount of work required to support the query on each host would scale accordingly.
Secondary indexes have their place, but they should only be used when queries are expected to return tens or perhaps hundreds of rows at most, and when the indexed column has medium cardinality.
Thanks for reading this excerpt from the DataStax whitepaper "Data Modeling in Apache Cassandra™;" tune in next week when we release another excerpt or click here to download the full asset.
More Company
View All


Introducing Tejas Kumar, Developer Relations Engineer
