A Thrift to CQL3 Upgrade Guide

Sylvain Lebresne

Forewords
This guide only describes version 3 of the CQL language. To avoid confusion, we will try to use the term CQL3 rather than CQL most of the time, but even when we don't, this is implicit.
Furthermore, CQL3 is beta in 1.1 (the language itself is beta, not just its implementation), and will only be final in Cassandra 1.2 (in beta itself at the time of this writing) and there are a few breaking syntax change and added features between CQL3 beta and its final version. This guide describe the final version of CQL3 and in particular may describe/use features that are not available in Cassandra 1.1.
Introduction
CQL3 (the Cassandra Query Language) provides a new API to work with Cassandra. Where the legacy thrift API exposes the internal storage structure of Cassandra pretty much directly, CQL3 provides a thin abstraction layer over this internal structure. This is A Good Thing as it allows hiding from the API a number of distracting and useless implementation details (such as range ghosts) and allows to provide native syntaxes for common encodings/idioms (like the CQL3 collections as we'll discuss below), instead of letting each client or client library reimplement them in their own, different and thus incompatible, way. However, the fact that CQL3 provides a thin layer of abstraction means that thrift users will have to understand the basics of this abstraction if they want to move existing application to CQL3. This is what this post tries to address. It explains how to translate thrift to CQL3. In doing so, this post also explains the basics of the implementation of CQL3 and can thus be of interest for those that want to understand that.
But before getting to the crux of the matter, let us have a word about when one should use CQL3. As described above, we believe that CQL3 is a simpler and overall better API for Cassandra than the thrift API is. Therefore, new projects/applications are encouraged to use CQL3 (though remember that CQL3 is not final yet, and so this statement will only be fully valid with Cassandra 1.2). But the thrift API is not going anywhere. Existing applications do not have to upgrade to CQL3. Internally, both CQL3 and thrift use the same storage engine, so all future improvements to this engine will impact both of them equally. Thus, this guide is for those that 1) have an existing application using thrift and 2) want to port it to CQL3.
Finally, let us remark that CQL3 does not claim to fundamentally change how to model applications for Cassandra. The main modeling principles are the same than they always have been: efficient modeling is still based on collocating that data that are accessed together through denormalization and the use of the ordering the storage engine provides, and is thus largely driven by the queries. If anything, CQL3 claims to make it easier to model along those principles by providing a simpler and more intuitive syntax to implement a number of idioms that this kind of modeling requires.
Vocabulary used in this post
The thrift API has historically confuse people coming from the relational world with the fact that it uses the terms "rows" and "columns", but with a different meaning than in SQL. CQL3 fixes that since in the model it exposes, row and columns have the same meaning than in SQL. We believe this to be an improvement for newcomers, but unfortunately, in doing so, it creates some temporary confusion when you want to switch from thrift to CQL3, as a "thrift" row doesn't always map to a "CQL3" row, and a "CQL3" column doesn't always map to a "thrift" column.
To avoid that confusion, we will use the following conventions (that have already been used in
previous posts too):
- We will always use "internal row" when we want to talk of a row as in thrift. We use the term "internal" because this correspond to the definition of a row in the internal implementation (which thrift exposes directly). Hence the term "row" alone will describe a CQL3 row, though we'll sometime use the term "CQL3 row" to recall that fact.
- We will use the term "cell" instead of "column" for thrift/internal columns. And thus "column" (or "CQL3 column") will always designate CQL3 column.
- We will prefer the term "column family" for thrift and the term "table" for CQL3, though both terms can be considered as synonymous
To sum up, for the purpose of this document, an internal row contains cells while a CQL3 row contains columns, and these two notions do not always map directly; this document will explain when these concepts match and when they do not.
Standard column families
Static Column family
In thrift, a static column family is one where each internal row will have more or less the same set of cell names, and that set is finite. A typical example is user profiles. There is a finite number of properties (though those may evolve over time) in the profiles the application uses, and each concrete profile will have some subset of those properties.
Such static column family would typically be defined in thrift (using the cli) by the following definition (to which we will later refer as definition 1):
create column family user_profiles
with key_validation_class = UTF8Type
and comparator = UTF8Type
and column_metadata = [
{column_name: first_name, validation_class: UTF8Type},
{column_name: last_name, validation_class: UTF8Type},
{column_name: email, validation_class: UTF8Type},
{column_name: year_of_birth, validation_class: IntegerType}
]
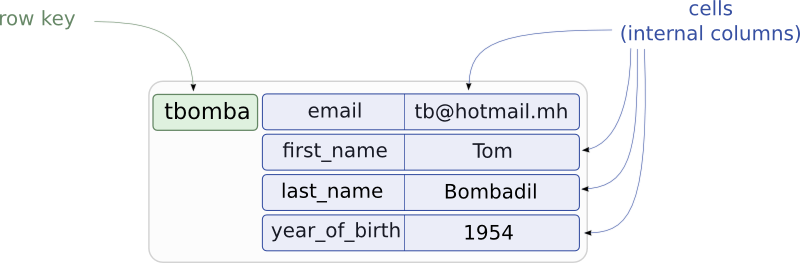
And profile will be internally stored as:
The functionally equivalent definition for such column family in CQL3 is (definition 2):
CREATE TABLE user_profiles (
user_id text PRIMARY KEY,
first_name text,
last_name text,
year_of_birth int
) WITH COMPACT STORAGE
This CQL definition will store data in exactly the same way than the thrift definition above (we will come back to the reason for the use of the WITH COMPACT STORAGE option later, but suffice to say that it is required for the previous statement to be true). So for static column families, an internal/thrift row does correspond exactly to a CQL3 row. But while each thrift cells has a corresponding CQL3 column, CQL3 defines one column (user_id) that doesn't map to a cell, but rather map to the thrift row key (and obviously the PRIMARY KEY annotation is what make that happen).
Now the attentive reader may have noticed that the CQL definition above has a little more information than the thrift one had. Namely, the CQL definition provides a name for the row key (i.e. user_id) that don't exist in the thrift definition. In other words, CQL3 uses more metadata than thrift and those metadata won't be there at first if you try to access the thrift column family created with definition 1. The way CQL3 deals with this is twofold:
- CQL3 picks a default name for the row key if none exists. This will be the case if you try to access (from CQL3) the column family created with definition 1. For the row key, that default name key. In other words, definition 1 is strictly equivalent to the following CQL definition:
CREATE TABLE user_profiles ( key text PRIMARY KEY, first_name text, last_name text, year_of_birth int ) WITH COMPACT STORAGEAnd by equivalent, we mean that if you create user_profiles using definition 1, then from cqlsh you will have:
cqlsh:test> SELECT * FROM user_profiles; key | email | first_name | last_name | year_of_birth --------+---------------+------------+-----------+--------------- tbomba | tb@hotmail.mh | Tom | Bombadil | 1954 - If you want to declare a more user friendly name than the default one, you can do so using
ALTER TABLE user_profiles RENAME key TO user_id;Such statement declares the missing metadata to CQL3. It has no impact on the thrift side, but after that statement, you will be able to access the table from CQL3 as if it had been declared using definition 2 above.
Dynamic Column family
A dynamic column family (or column family with wide rows) is one where each internal row may contain completely different sets of cells. The typical example of such a column family is time series. For example, keeping for each user a timeline of all the links on which the user has clicked. Such a column family would be defined in thrift by (definition 3):
create column family clicks
with key_validation_class = UTF8Type
and comparator = DateType
and default_validation_class = UTF8Type
And for a given user, its clicks will be internally stored as:

In other words, all the urls clicked by one user will be stored in a single internal row. And because internal rows are sorted according to the comparator, and because the comparator in that case is DateTime the clicks will be in chronological order, allowing very efficient requests of all the clicks for a given user in a given time interval.
In CQL3, the functionally equivalent definition would be (definition 4):
CREATE TABLE clicks (
user_id text,
time timestamp,
url text,
PRIMARY KEY (user_id, time)
) WITH COMPACT STORAGE
That definition will store data in exactly the same way than definition 3 does. The difference with the static case is the compound primary key. The way CQL3 works, it will map the first component (user_id) of the primary key to the internal row key and the second component (time) to the internal cell name. And the last CQL3 column (url) will be mapped to the cell value. That is how CQL3 allows access to wide rows: by transposing one internal wide rows into multiple CQL3 rows, one per cell of the wide row. This is however just a different way to view the same information.
Now, as in the static case, this definition has more information than its thrift counterpart (definition 3) as it provides user friendly names for the row key (user_id), the cell names (time) and the column values (url). And in that case too, CQL will pick default names if those don't exist: key for the row key as before, column1 for the cell name, and value for the cell value.
In other words, the clicks column family defined in thrift by definition 3 is in fact strictly equivalent to the following CQL3 table:
CREATE TABLE clicks (
key text,
column1 timestamp,
value text,
PRIMARY KEY (key, column1)
) WITH COMPACT STORAGE
Again, "equivalent" means that you can access the column family created from thrift in CQL3 as if it had been defined with the preceding definition. So for instance, you can retrieve a time slice of clicks (making use of the internal sorting of wide rows) with:
cqlsh:test> SELECT column1, value
FROM clicks
WHERE key = 'tbomba'
AND column1 >= '2012-10-25 14:31:00'
AND column1 < '2012-10-25 18:00:00';
column1 | value
--------------------------+-------------------------
2012-10-25 14:33:14+0000 | http://www.amazon.fr
2012-10-25 17:47:05+0000 | http://www.datastax.com
And this query will internally translate to a simple get_slice call.
But of course you can define more use friendly name here again:
ALTER TABLE clicks RENAME key TO user_id
AND column1 TO time
AND value TO url;
after which the query above can be wrote as:
cqlsh:test> SELECT time, url
FROM clicks
WHERE user_id = 'tbomba'
AND time >= '2012-10-25 14:31:00'
AND time < '2012-10-25 18:00:00';
time | url
--------------------------+-------------------------
2012-10-25 14:33:14+0000 | http://www.amazon.fr
2012-10-25 17:47:05+0000 | http://www.datastax.com
Mixing static and dynamic
In the majority of cases, column families are used in either the static or the dynamic way describe above, both of which CQL3 handles natively as we've seen. In a few cases however, it can be useful to have a bit of dynamicity in otherwise static column families.
A typical example is if you want to add tags to our user_profiles example above. There is two main ways to model this.
- You can create a separate tags dynamic column family that for each user stores its tags. In that case, this column family can simply be accessed through CQL3 as explained in the preceding section.
- Or you can directly add the tags to the user_profiles column family.
That second technique has the advantage that reading an entire user profile with its tags requires only one read instead of two if you were to use the 2 column family solution. Technically, if you want to add the tags 'good guy' and 'friendly' to a user profile, you would insert a cell named 'tag:good guy' and one called 'tag:friendly' (both with empty values) to that user profile, and internally the profile would look like:

As explained in a previous blog post, CQL3 provides a native way to perform that kind of technique with its support of collections. In fact, CQL3 sets are implemented with exactly the same technique as the tag example above: each element of the set is internally a separate cell with an empty value. The only difference is that with thrift, you have to prepend the string 'tag:' to each tag cell manually, and regroup all tags cells together on read, while CQL3 handles all that transparently for you when you use a set.
Note that this why "exposing collections to Thrift" doesn't really make sense. Collections are exposed to Thrift, it's just that Thrift directly exposes the internal storage engine and thus exposes each element of the collection in its bare format. Another way to put it is that collections in CQL3 are just syntactic sugar for a (very) useful pattern. And such sugar can only be provided because the API is an abstraction over the storage engine.
So, for people starting a new project in CQL3 directly, they should use collections when they need to mix static and dynamic behavior. Collections are a better interface for such things than doing it manually à la Thrift.
However, if you have used something similar to the thrift tag example above, the upgrade to CQL3 will be less straightforward than in the case of pure static or pure dynamic column families. Namely, CQL3 still consider the column family static because the definition of user_profile is still the one of definition 1. But since the tag columns themselves are not declared (and cannot be, they are dynamically created), you will not be able to access them for CQL3 by default. The only solution to be able to access the column family fully is to remove the declared columns from the thrift schema altogether, i.e. to update the thrift schema with:
update column family user_profiles
with key_validation_class = UTF8Type
and comparator = UTF8Type
and column_metadata=[]
Once you have done this, you will be able to access the column family as in the dynamic case, and so, after that update, you will have:
cqlsh> SELECT * FROM user_profiles WHERE key = 'tbomba'
key | column1 | value
--------+---------------+---------------
tbomba | email | tb@hotmail.mh
tbomba | first_name | Tom
tbomba | last_name | Bombadil
tbomba | year_of_birth | \x07\xa2
This does have some downsides however:
- From an API perspective, a user profile will be exposed as multiple CQL rows (again, this is only the view the API exposes; internally the layout hasn't changed). This is mainly cosmetic, but is arguably uglier than having one CQL row per profile.
- Some server side validation of the static column values have been lost in the operation.
- Since the static column values validation types have been dropped, they are not available to your client library anymore. In particular, as can be seen in the output above, cqlsh display some value in a non human-readable format. And unless the client library exposes an easy way to force the deserialization format for a value, such deserialization will have to be done manually in client code.
It is clear that upgrading to CQL3 from thrift if you have lots of existing column families that mix static and dynamic behavior (in the same column family) is a tad inconvenient. This is unfortunate but let's recall that:
- Thrift isn't going anywhere. What CQL3 brings is a much more user-friendly API. But CQL3 doesn't do anything that is fundamentally unachievable with thrift. Therefore, if you do have a lot of existing column families in which you mix static and dynamic behavior, it might be simpler to stick to thrift for those (you won't be worse off than if CQL3 did not exist) and keep CQL3 for new applications/projects.
- If you really want to upgrade to CQL3 and can afford it, a data migration from your existing column families to a standard (non-compact, see below) CQL3 table with the use of collections is obviously always possible.
Composites
There is one sub-case of dynamic column families that is worth discussing: the case where the comparator is a CompositeType. Say for instance that you need to store some events for users and you are interested in grouping said events by day (the day number of the year) and for each day, by the minute within a day the event occurred. This is a basic time series example so you could model it as the clicks column family from earlier on, but allow me this slightly artificial example and say you want to separate the day number from the minute within that day. You might define the following thrift column family:
create column family events
with key_validation_class = UTF8Type
and comparator = 'CompositeType(IntegerType, IntegerType)'
and default_validation_class = UTF8Type
and for one user, its events may internally look like:
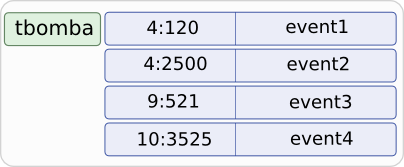
where 4:120 represents the composite cell name composed of the two component 4 and 120.
If you query this column family from CQL3, you will get:
cqlsh:test> SELECT * FROM events;
key | column1 | column2 | value
--------+---------+---------+---------
tbomba | 4 | 120 | event 1
tbomba | 4 | 2500 | event 2
tbomba | 9 | 521 | event 3
tbomba | 10 | 3525 | event 4
In other words, as far as CQL3 is concerned, this column family is equivalent to:
CREATE TABLE events (
key text,
column1 int,
column2 int,
value text,
PRIMARY KEY(key, column1, column2)
) WITH COMPACT STORAGE
As you can see, the composite type is handled natively by CQL3, that maps one CQL3 column for each component of the composite cell name. Of course, as in the previous examples, you can rename those default names to more user friendly ones:
cqlsh:test> ALTER TABLE events RENAME key TO id
AND column1 TO day
AND column2 TO minute_in_day
AND value TO event;
cqlsh:test> SELECT * FROM events;
id | day | minute_in_day | event
--------+-----+---------------+---------
tbomba | 4 | 120 | event 1
tbomba | 4 | 2500 | event 2
tbomba | 9 | 521 | event 3
tbomba | 10 | 3525 | event 4
Do note that in that case it is advised to rename all the columns in one ALTER TABLE statement like done above. Due to a technical limitation, if you rename the colums one by one, you could end up in a wrong situation.
Non compact tables
All the CQL3 definitions above have used the COMPACT STORAGE option. Indeed, column families created from Thrift will always map to a so-called compact table. To explain how non-compact CQL3 table differs from compact ones, consider the following non-compact CQL3 table:
CREATE TABLE comments (
article_id uuid,
posted_at timestamp,
author text,
karma int,
content text,
PRIMARY KEY (article_id, posted_at)
)
This table stores comments made on some articles. Each comment is a CQL row that is identified by the article_id it is a comment of, and the time at which it has been posted, and each thus identified comment is composed of an author name, a content text and a 'karma' integer (some value representing what how much users like this comment).
As in the dynamic column family example from the previous section, we have a composite primary key, and here again, article_id will be mapped to the internal row key and posted_at will be mapped to (the first part of) the cell name. However, in the previous section, the definition had just one CQL3 column not part of the primary key (and it would have been a bug to declare more than one column, due to the use of compact storage) which was mapped internally to the cell value. But here we have 3 CQL3 columns not part of the primary key. The way this is handled is that internally this comments table will use a CompositeType comparator whose first component will be mapped to posted_at, and the second one will be the name of the column the cell represents. That is, for a given article, the internal layout of the definition above will be:
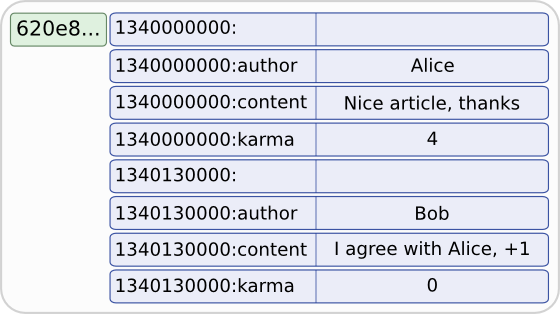
So this comment table uses wide rows internally, but each CQL3 row actually maps to a small slice of internal cells (note that the first "empty" cell for each CQL3 row internal slice is not a mistake, but is here for implementation details).
In other words, non-compact CQL3 tables map rows to static slices within wide ordered internal rows. This is very useful for things like materialized views that are common in Cassandra. And yes, this is very similar to what super columns give you in thrift (see below for a discussion on super columns), but is somewhat better than super columns in that in this example, some of the CQL3 columns are text (author, content), while others are integers (karma), which you cannot do with super columns (you would have to use BytesType as sub-comparator or store the karma integer as a string).
This also allows updating and deleting each individual column since they are broken out into individual storage engine cells.
But what about truly static tables. How does the definition 2 from the first section (that uses COMPACT STORAGE) differs from:
CREATE TABLE user_profiles (
user_id text PRIMARY KEY,
first_name text,
last_name text,
year_of_birth int
)
i.e, the same definition but without the COMPACT STORAGE option. The difference is that the definition above will internally use a CompositeType comparator with a single UTF8Type component, instead of an UTF8Type comparator. This may seem wasteful (technically, the use of CompositeType adds 2 bytes of overhead per internal cells (hence the compact/non-compact terms)), but the reason for that is collections support. Internally, collections require the use of CompositeType. In other words, with the definition above you can do:
ALTER TABLE user_profiles ADD tags TYPE set
but you cannot do so if COMPACT STORAGE is used.
Please do note that while non-compact table are less "compact" internally, we highly suggest using them for new developments. The extra possibility of being able to evolve your table with the use of collections later (even if you don't think you will need it at first) is worth the slight storage overhead -- overhead that is further diminished by sstable compression, which is enabled by default since Cassandra 1.1.0.
A word on super columns
As we've seen in the previous section, CQL3 natively supports the same use cases that super columns are able to support, and the CQL3 way has less limitations than super columns have. However, existing super column families cannot, at the time of this writing, be accessed from CQL3. CASSANDRA-3237 is open to internally replace super columns by an equivalent encoding using composite columns. That encoding will be the encoding of non-compact CQL3 table described in the previosu section. Hence, as soon as that patch lands, super columns will be fully available through CQL3 as normal CQL3 table. This is on the roadmap for Cassandra 1.3.
More Technology
View All
Introducing the DataStax AI Terraform Module


