

One of the new features slated for Cassandra 1.2's release later this year is virtual nodes (vnodes.) What are vnodes? If you recall how token selection works currently, there's one token per node, and thusly a node owns exactly one contiguous range in the ringspace. Vnodes change this paradigm from one token or range per node, to many per node. Within a cluster these can be randomly selected and be non-contiguous, giving us many smaller ranges that belong to each node.
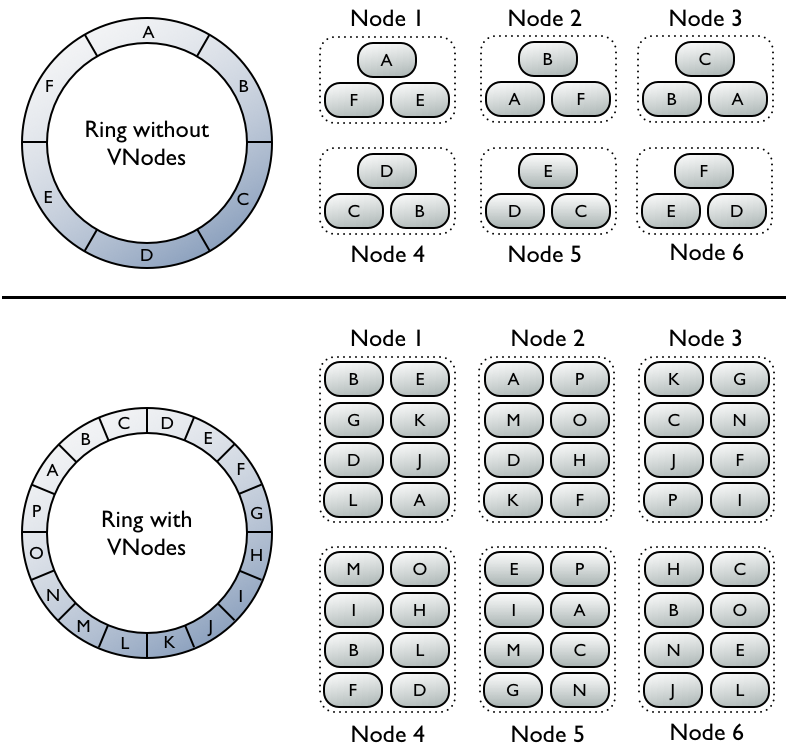
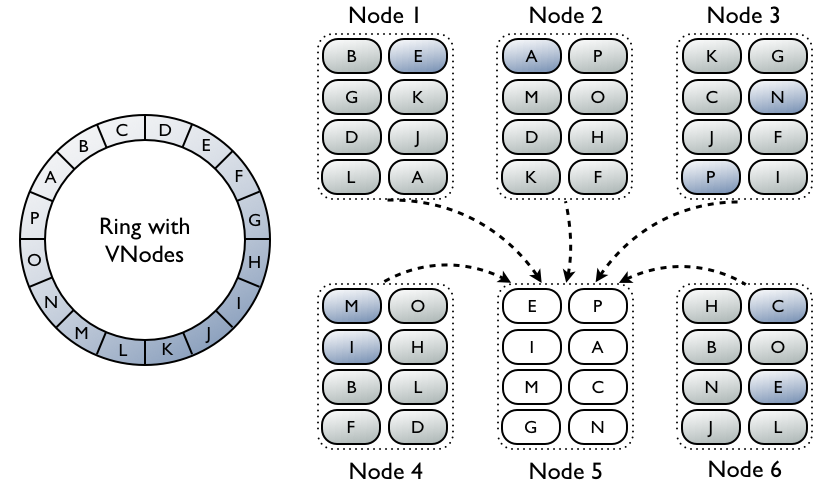
What advantages does this bring to the table? Let's consider the following scenario: we have 30 nodes and replication factor of 3. A node dies completely, and we need to bring up a replacement. At this point the replacement node needs to get a replica for 3 different ranges to reconstitute not only the data it is the first natural replica for, but also data that it is a secondary/tertiary natural replica for (though do recall no replica has 'priority' over another in Cassandra, this terminology is strictly to illustrate placement on the ring.) Since our RF is 3 and we lost a node, we logically only have 2 replicas left, which for 3 ranges means there are up to 6 nodes we can stream from. In current practice though, Cassandra will only use one replica from each range, so we'll stream from 3 other nodes total.

We want to minimize how long this operation is going to take, because if we lose another node while this is happening there's a chance we'll be down to 1 replica for some ranges, and then all operations for that range with a consistency level greater than ONE would fail. Even if we used all 6 possible replica nodes, we'd only be using 20% of our cluster, however.
If instead we have randomized vnodes spread throughout the entire cluster, we still need to transfer the same amount of data, but now it's in a greater number of much smaller ranges distributed on all machines in the cluster. This allows us to rebuild the node faster than our single token per node scheme.
Cassandra has worked toward increasing the amount of data that can be reasonably stored per node in many releases, and of course 1.2 will be no different with its new disk failure handling. One last wrinkle though is if you lose one disk, you'll have to wait on repair before anything will begin to be restored to the new disk. Repair is two phases, first a validation compaction that iterates all the data and generates a Merkle tree, and then streaming when the actual data that is needed is sent. The validation phase might take an hour, while the streaming only takes a few minutes, meaning your replaced disk sits empty for at least an hour. Much like the node replacement scenario I began with, with vnodes you'll gain two distinct advantages in this situation. The first is that since the ranges are smaller, data will be sent to the damaged node in a more incremental fashion instead of waiting until the end of a large validation phase. The second is that the validation phase will be parallelized across more machines, causing it to complete faster.
Another nice advantage vnodes bring is easing the use of heterogeneous machines in a cluster. As time goes on, everyone is going to come to a point where it's time to replace older, weaker machines with newer, more powerful ones. While in transition however, it would be nice if the newer nodes could bear more load immediately. You might be able do this today with very careful planning and range calculation, but it would be cumbersome and error prone. If you have vnodes it becomes much simpler, you just assign a proportional number of vnodes to the larger machines. If you started your older machines with 64 vnodes per node and the new machines are twice as powerful, simply give them 128 vnodes each and the cluster remains balanced even during transition.
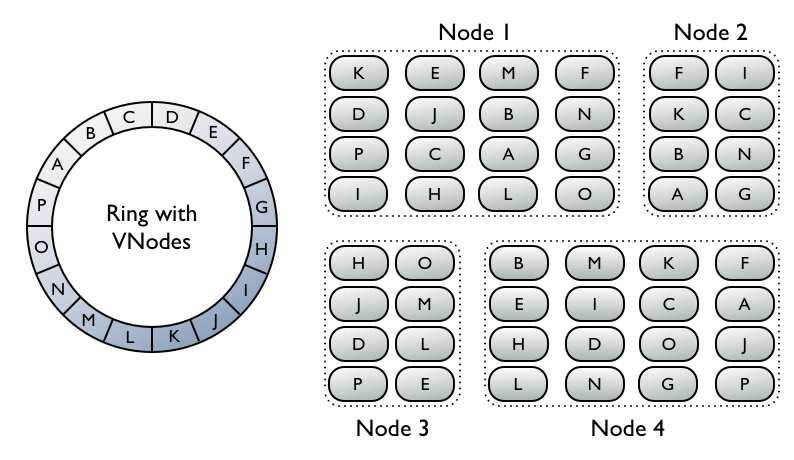
As you can see, virtual nodes are a large feature addition for 1.2, but don't worry if you have an existing cluster, they won't be forced on you and everything will work the way it did before. If you'd like to upgrade an installation to virtual nodes, that's possible too, but I'll save that for a later post. If you want to get started with vnodes on a fresh cluster, however, that is fairly straightforward. Just don't set the initial_token parameter in your conf/cassandra.yaml and instead enable the num_tokens parameter. A good default value for this is 256.
More Technology
View All


