What’s New in Cassandra 2.1: Better Implementation of Counters

Aleksey Yeschenko

TL;DR
Apache Cassandra 2.1 will have a safer, simpler, and often faster distributed counters implementation. The crucial difference is that rather than logging counter deltas (increments) directly to the commit log – making replay non-idempotent and potentially unsafe – Cassandra will now read the current value for every counter update and apply the delta. The final result is then added to the memtables. You should expect more accurate values and more consistent performance from the new implementation. The price for all the improvements is increased latency for RF=1/CL.ONE/replicate_on_write=false counter tables (the latter being an anti-pattern and heavily recommended against even in pre–2.1 era). In fact, the replicate_on_write option is entirely gone.
This also lays the foundation for Cassandra 3.0 to bring even better performance for counters users.
Intro
Apache Cassandra introduced fast, distributed counters back in version 0.8.0 – almost 3 years ago. Cassandra is still one of the only databases that allows race-free increments with local latency across multiple datacenters simultaneously, but through Cassandra 2.0 some limitations in the original counters’ design continued to cause headaches, notably topology changes potentially leading to bad counters and the infamous invalid counter shard detected problem.
These problems and the extra complexity caused by the counters-related special cases in the code base have been fixed in the upcoming Cassandra 2.1 release. The new implementation also creates many fewer objects for the JVM to garbage-collect, so use of counters will not cause pathological behaviour under heavy load anymore.
How Counters Used to Work
Internally, counters are split into fragments that we call ‘shards’. A shard is basically a 3-tuple of {node’s counter id, shard’s logical clock, shard’s value}.
Counter id is a unique value (a timeuuid) uniquely identifying the node that created the shard. Logical clock is the monotonically increasing version of the shard, and value is the size of the increment or the total value, depending on the shard type.
A counter’s value is calculated as the sum of all the shards’ values of the counter in its replica set.
Finally, a counter cell can (and will) contain multiple shards, packed into a binary blob as a counter context.
To illustrate how counters used to work before 2.1, let’s start with a simple 1-node (A) clean-state cluster as an example, with initial counter id of A0, and assume that there is only one counter foo. Shards are grouped into counter contexts, outlined in dotted lines, below.
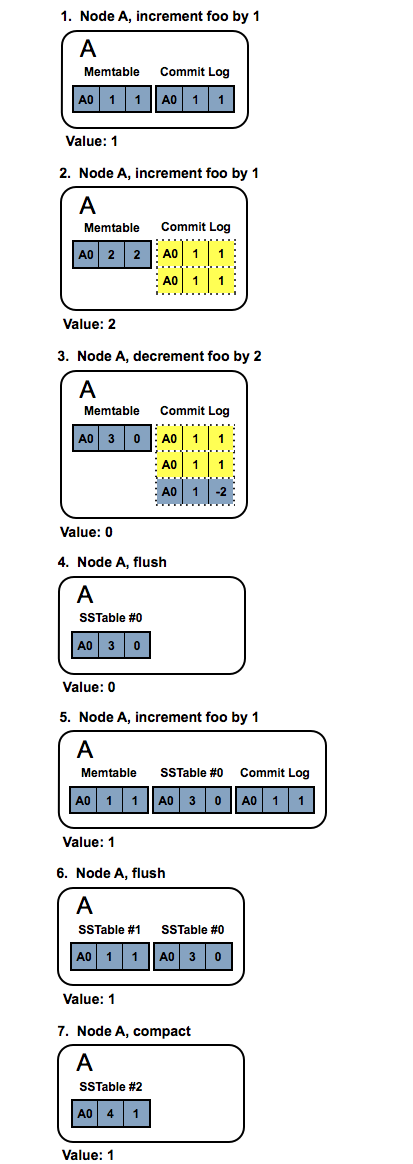
As you can see, to get the counter value you need to merge all the contexts from all the sstables and the memtable, and sum up the shards’ values. Simple as that.
Things get complicated, however, once we introduce another node and replication.
Let’s add node B with an initial counter id of B0, increase the RF (replication factor) to 2, and run repair. Now, when a write requests hits node A, we have to replicate the update to node B (and vice versa). This is where the pain begins, because we can’t simply replicate the delta itself, for several reasons. Instead, after writing the delta to the local memtable and commitlog, the coordinator sums up its local shard values, and sends the total, not the delta, to its neighbours. From now on, the deltas will be called ‘local shards’ and the totals - ‘remote shards’.

Let’s see at the result of some writes to the counter executed at node B:
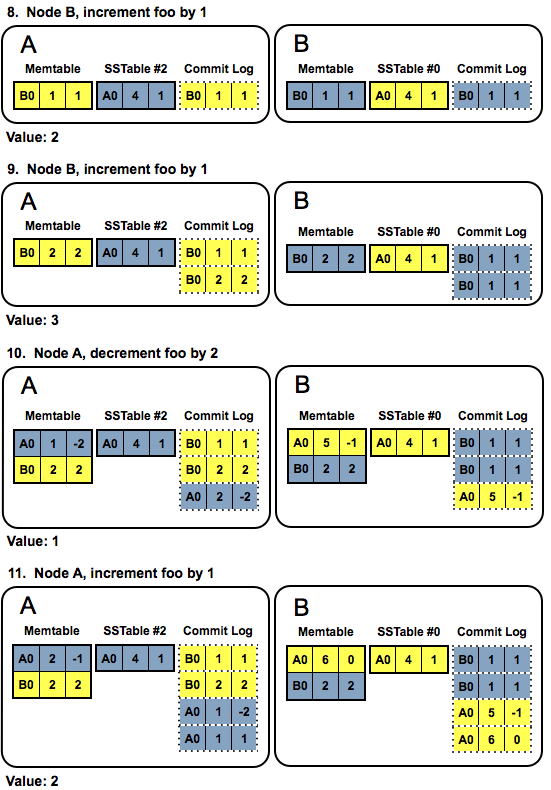
Looks complicated? It should, because it is. One node’s local shard is another node’s remote shard, and the merge rules are different for local and remote shards. Every time a local shard is sent to another node, it must be converted into a remote one - this includes any streaming, not just regular writes.
This local/remote distinction doesn’t just create a lot of edge case complexity in the codebase - it also leads to several practical issues for Cassandra users.
Pre–2.1 Issues
Topology changes at RF=1 will lead to bad incorrect results. The problem is described in details in this JIRA issue.
Losing some data because of a corrupt sstable or replaying the commit log can lead to invalid counter shards.
To properly repair a counter column family, or even to run scrub, you need to renew the node’s counter id, which leads to growth of counter contexts and means that you need more space, and to send more data over the network with time if you repair or cleanup.
Reconciling two counter cells (two counter contexts) requires allocating a third counter cell, large enough for the combined counter shards of the two cells being reconciled. This means N extra cells allocated for a counter read from N sstables and one memtable, for example. This is also true for the write process when racing to the memtable update. Concurrent updates to a small group of partitions can lead to pathological GC behaviour under heavy load.
The 2.1 Solution
To deal with the listed issues, Cassandra 2.1 gets rid of the local shards entirely. Instead, we grab a (local) lock for each counter being updated, read the current value, then write the incremented value (not the increment itself as in C* 2.0) to the commitlog and to the memtable.
We no longer have to convert between local and remote shards when sending data between the nodes.
We don’t have to renew nodes’ counter ids, ever, ensuring that the counters’ size doesn’t grow unbounded.
For an illustration, let’s see the result of the same write sequence in 2.1:
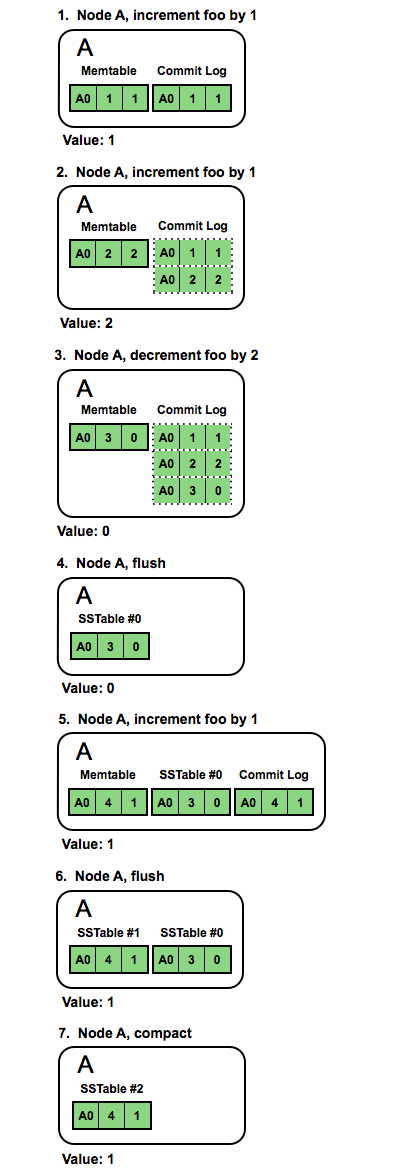
We no longer need to sum the sub-counts of the node’s shards - we can just pick the shard with the largest logical clock and stop there. Without the local/remote distinction, the distributed case is also a lot simpler:
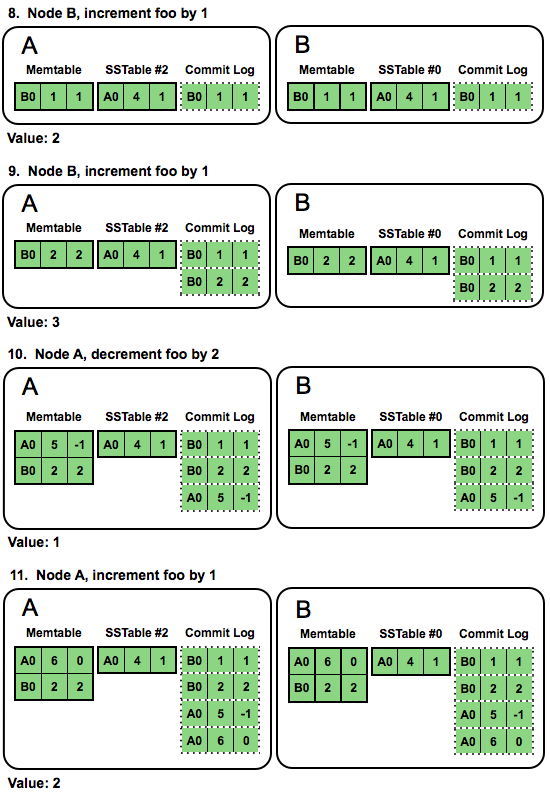
Eliminating local shards simplifies almost every counters aspect - from writes and reads to streaming and cleanup.
As a bonus, we have to allocate a lot fewer objects on reads and writes, since often we are just able to pick the context with shards with larger timestamps instead of having to sum them up, making bursts of garbage collection activity a thing of the past.
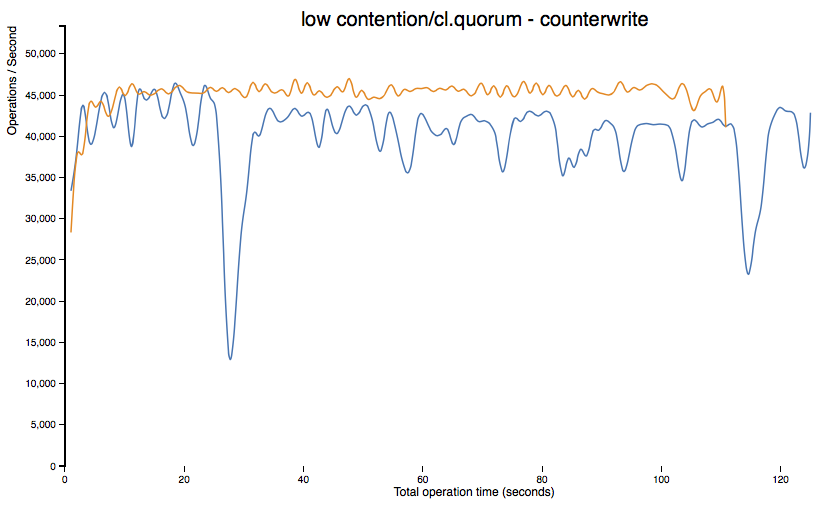
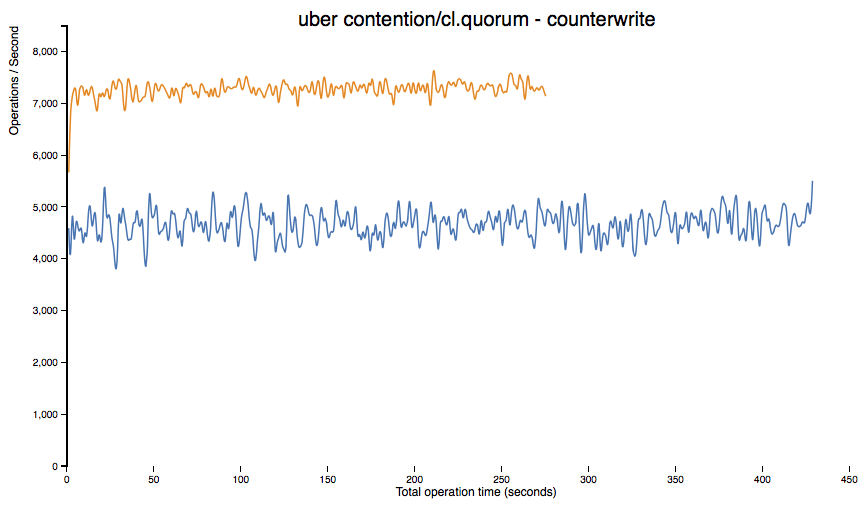
Performance Implications
The new implementation does come with a price. Because we perform a mutexed read-before-write now, latency for CL.ONE (or RF=1) to would suffer with a naive implementation, particularly for many updates contenting for few counter objects. To mitigate this, Cassandra 2.1 introduces a new form of cache, counter cache, to keep hot counter values performant. Counter cache size and save period can be configured in cassandra.yaml.
Removing legacy local/remote shards entirely in Cassandra 3.0 and implement CASSANDRA–6506 will eliminate the need for the counter cache.
Other use cases should see uniformly better and more predictable performance, both with and without counter cache enabled (orange for Cassandra 2.1, blue for Cassandra 2.0):
Future work
Cassandra 3.0 will finalise what was started in Cassandra 2.1. The primary task left is CASSANDRA–6506 - split counter context shards into separate cells, that will simplify counters implementation even further, and bring even more performance improvements for counters.
More Technology
View All
Introducing the DataStax AI Terraform Module


