Your Ideal Performance: Consistency Tradeoff

Paul Cannon

The term eventual consistency often seems to bother newcomers to distributed data storage systems. Hopefully this post will be able to put a more concrete face on it.
(If you are already familiar with the nature of eventual consistency, you may want to skip a bit.)
Eventual consistency refers to a strategy used by many distributed systems to improve query and update latencies, and in a more limited way, to provide stronger availability to a system than could otherwise be attained.
There are a lot of parameters which come into play when trying to predict or model the performance of distributed systems. How many nodes can die before data is lost? How many can die without affecting the usability of the system? Are there any single points of failure? Can the system be used if, for some period of time, half of the nodes can't see the other half? How fast can I get data out of the system? How fast can it accept new data?
Since Apache Cassandra's distributed nature is based on Dynamo, let us consider here Dynamo-style systems. These allow the user to specify how many nodes should get replicas of particular classes of data (the replication factor, commonly called N in the literature). At the same time, it also allows the user to specify the number of nodes which must accept a write before it is considered successful (W) and the number of nodes which are consulted for each read (R). By varying N, W, and R, one can obtain a wide variety of scenarios with different properties of availability, consistency, reliability, and speed.
For example, Abby's top priority is that data never, ever be lost or out of date, and she has determined that she wants her system to be able to tolerate the loss of two nodes without going down. She may want to go all the way up to N=5, W=3, and R=3. Since W+R > N, any node set chosen for reading will always intersect with any node set chosen for writing, and so Abby's data is guaranteed to be consistent- even if she loses up to two nodes within a replication set. (Note that N is not the same as the number of nodes in the whole system; it's just a lower bound.)
Meanwhile, Bart's top priorities are speed, low hardware costs, and/or disk costs, and he doesn't care much if he incurs downtime or data loss when a hardware failure occurs. He might then want N=W=R=1. He is also guaranteed data consistency, as long as the nodes stay available and working, but he only keeps one copy of each piece of data, so he only needs 1/5 of the hardware that Abby would need for the same amount of data.
Charlotte's app demands speed above all else. Her data is vital to her business, but there is a vast amount of it (maybe, like Netflix, she will be seeing around a million writes per second), and she needs to keep costs down as much as possible. So she does some math, and determines that she must have 90% of reads up-to-date within 50 ms, and 99.9% of reads up-to-date within 250 ms.
Is Cassandra a good fit for Charlotte? She is going to be running at a pretty large scale- let's say 1000 nodes. Her MTTF numbers indicate she should expect a hardware failure about every 10 days, so she can't afford to use N=1 like Bart. She has so much data that N=5 would be cost-prohibitive. N=3 may be an option, but should she use R=W=2 for full strong consistency, or R=W=1 for faster and cheaper eventual consistency? Or maybe R=1, W=2 or vice versa? Surely the "eventual" in eventual consistency means that she won't be able to meet her consistency requirements stated above, will she? Just how "eventual" will it be?
Up until now, this question would largely have been a matter of intuition, guesswork, or large-scale profiling. But some folks in the EECS department at UC Berkeley threw a whole bunch of math and simulation at the problem in an effort to get a more objective handle on "How Eventual is Eventual Consistency?" You can read a summary of their results here, and a much deeper technical report here.
The best part is that they also provided the world with an interactive demo, which lets you fiddle with N, R, and W, as well as parameters defining your system's read and write latency distributions, and gives you a nice graph showing what you can expect in terms of consistent reads after a given time.
See the interactive demo here.
This terrific tool actually runs thousands of Monte Carlo simulations per data point (turns out the math to create a full, precise formulaic solution was too hairy) to give a very reliable approximation of consistency for a range of times after a write.
It even goes as far as to model parts of the anti-entropy provided by Dynamo (and Cassandra): expanding partial quorums, which refers to writes being sent to all N nodes in a replication set, even when only the first W nodes will be waited for. I.e., with N=3 and W=1, the effective latency of a write will be the latency of whichever of three nodes is fastest, but the write is still sent to all the nodes, if available. Cassandra also provides ongoing read repair and Merkle tree data repair (when requested) as additional anti-entropy measures which increase consistency even more, but this model does not take those into account. So it's on the conservative side.
Let's investigate using the demo to determine Charlotte's cheapest mode of operation. The four sliders at the bottom allow specifying some various latency distributions:
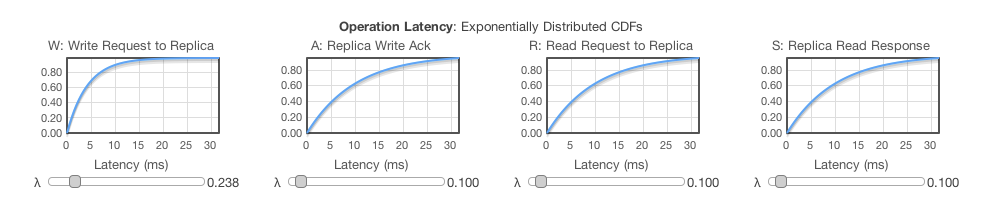
These four latency measurements are modeled as following an Exponential distribution. If you determine that your latency distribution doesn't fit, you can pretty easily modify the PBS simulation code to get a better model.
The W latency represents the amount of time between a client issuing a write, and the write actually being received by a node. The A latency models the amount of time between a node receiving a write and the reception by the coordinator of the write acknowledgement. R is for the latency between issuing a read and the read arriving at a node, and S is the latency between a read arriving on a node and the response arriving at the coordinator.
Cassandra isn't tooled to give straightforward average or histogram values for each of these metrics, although the Berkeley authors did make a patch for Cassandra to do so (we've requested a copy and may incorporate it back into stock Cassandra). However, you can get reasonable approximations if you have things like metrics showing average read and write latencies from your client software's perspective, read and write latencies as derived from the StorageProxyMBean, and nodetool cfstats output.
The parameter for the exponential distribution is λ, the rate. The rate is the inverse of the mean, so you can divide 1 by your determined average for each latency metric in milliseconds to get λ. Then just move the slider in the demo to get as close as you can to that value (the slider controls are a little bit finicky, but there doesn't seem to be a whole lot of change in the output over small differences in λ).
Here are some reasonable values I plugged in for Charlotte (although your numbers may vary considerably based on application, network, hardware, etc):
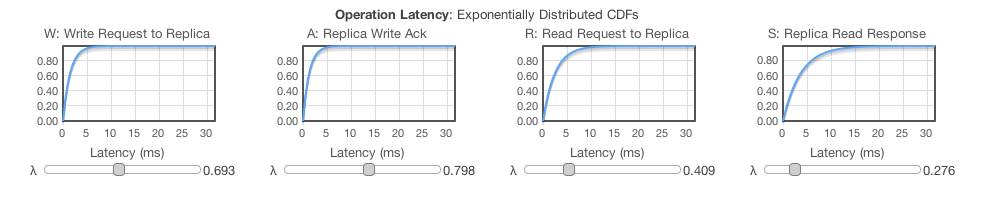
Charlotte wants to see, first, if she can get away with R=W=1, to get the best possible read and write latencies and expected availability. So we tune the Replica Configuration sliders:

And she wants to see the probability of reading any data that's not the absolute latest version, so she sets Tolerable Staleness to 1.

And voilà, myriad calculations are performed, and answers are given.
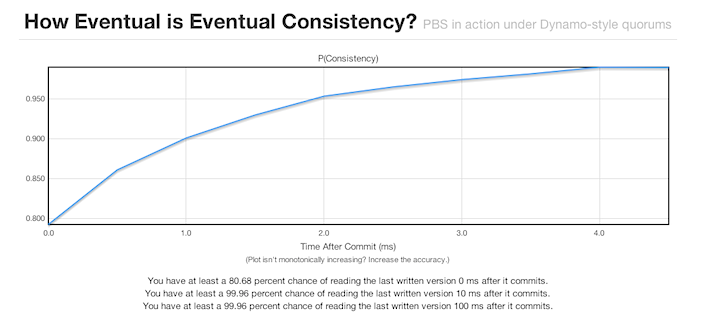
Wow- so it turns out that even with N=3 and R=W=1, under "eventual consistency" semantics, Charlotte can expect a remarkable amount of "real consistency". The numbers exceed her requirements!
Go ahead and explore the demo. You'll find that often, the write latency (W) distribution is a particularly strong factor in determining ideal consistency. This works out great for Cassandra, which is absurdly fast at performing writes.
Keep in mind that the demo shows a conservative lower bound on consistency probabilities, and the actual distribution is likely to be noticeably higher, if the latencies are correct.
More Technology
View All
Introducing the DataStax AI Terraform Module


