Modern Data Architectures: Kafka, Cassandra, & Spark

Rich Edwards
Apache Kafka, Apache Cassandra, with a dash of Apache Spark Streaming, is a potent combination. Working in tandem in your architecture, the technologies can take on many otherwise troubling use cases. Cliff Gilmore has worked extensively with strategic users of these technologies and seen repeated patterns where they’re successful. Currently a principal solutions architect and streaming data specialist at AWS, he was a senior solutions architect at Confluent when he gave a talk about the topic at DataStax Accelerate. It was a bit of a homecoming, as he’s also a former member of the DataStax team.
In this post, we’ll provide an overview and some of the key points from Cliff’s presentation, starting with a little Kafka 101, before diving into common Kafka/Cassandra use cases, along with situations where Spark can help.
What is Apache Kafka?
Kafka is a massively scalable pub/sub messaging system designed to handle modern event streaming. It was originally created at LinkedIn to solve the problem of not being able to get their data everywhere it needed to be in real time, including NoSQL databases, operational systems, and a data lake. It was later open sourced and has been widely adopted.
First and foremost, Kafka is a log. It’s persistent and distributed, with the ability to scale and handle millions of writes per second. And it’s designed to have many different consumers of a given event, across the organization, without impacting each other's ability to read.
Why use Kafka?
Kafka has many advantages. It’s distributed by design with the scalability of a file system. It can run at 100 megabytes, even gigabytes, per second, and can scale with low-cost commodity hardware. While it’s not a database—you can’t query Kafka—it makes some similar guarantees. The order within a particular partition can be set in advance and it also provides a persistence guarantee not common in legacy messaging technologies. Since it’s also a distributed system, it provides replication, partitioning, horizontal scalability, continuous availability, and fault tolerance. This design enables high throughput, without bottlenecks on a single machine.
How does Kafka work?
Kafka captures an ordered set of events over time, at very high volumes, without having to sync to disk on every write. This allows data to be ingested from across the organization at very high rates of messaging, while also providing durability. Depending on how much storage you want to use, you can set Kafka’s retention to a time-period of your choice—an hour, a week, a month, forever. This allows you to replay events from the past or rehydrate a database when you spin up a new application. Events become the core element the system and can be used to scale out the data infrastructure on demand.
And an event could be just about anything. It could be an online order, a customer changing their email, or an IoT sensor reading. There are countless types of events. From these events, you can build views of data. There’s still a lot of data on mainframes and Oracle databases. Kafka provides the log necessary to get that information out of legacy systems and into your modern tier.
Connectors provide a convenient way to quickly get data in and out of Kafka. Since it's a general-purpose framework, anyone can write a connector and there’s a rich ecosystem of choices. That makes it very easy to connect different systems. For example, you can map a topic in Kafka directly to tables in Cassandra and have the data format transformed to be usable with Cassandra Query Language (CQL).
How does Kafka scale?
Kafka scales by distributing on partitions. For instance, let’s assume we have a topic called orders. We can distribute its data across multiple partitions based on a key. If we have data for orders by user, user ID could be the key. Kafka also enables serialization—to keep track of the sequence of certain events. This is important because there are some things that shouldn’t be done out of order. You shouldn’t ship something before you’ve checked that the customer’s credit card is valid. If you have a lot of concurrency, you could have a thousand partitions, but you still want to have ordering within the message tier.
How does Kafka handle streams?
Kafka also provides a streaming layer. Called Kafka Streams, it’s a stream processing library and isn’t a replacement for Apache Spark Streaming. It’s not a cluster and isn’t a continuously deployable set of nodes that you work with. It's a different technology for a different problem. Kafka Streams is built for transforming and enriching data in flight and making sure it gets to its destination fast—in the correct structure. As an example, you could use Kafka Streams to add customer data to a set of orders in motion and have it delivered in the proper format for Cassandra. The source is always one or more topics, and the destination is also one or more topics. In a lot of cases, the source has normalized data or data that doesn’t come in a format that matches your query patterns. Kafka Streams takes care of that for you. If the source is a relational database, Kafka Streams denormalizes the data for you so it can be used in a NoSQL database like Cassandra. Kafka Steams allows you to join information together and create many different views, including aggregations and filters. You can easily filter out anything not important. For an orders topic, you could filter out everything that's not from Washington D.C., and make a new topic out of that. Kafka Streams also allows everyone in the organization to access the enriched data in parallel. And this is all done with code, not infrastructure.
Architecture with Kafka + Cassandra + Spark
It’s clear one of the things Kafka is best at is getting data out of legacy systems. Cassandra is a common destination for Kafka data because, once there, it can be used with modern application or microservices and you can interact with customers in real-time. Kafka and Cassandra just fit well together. As Cliff put it, they’re “kind of best friends.”
Kafka uses connectors to populate Cassandra tables, providing a new home for the business logic that was previously trapped in legacy systems. From there, Cassandra can make that data and logic available to other services using APIs, and can provide a high availability, quality user experience to customers. Data is modelled to serve reads in Cassandra, and it’s common to have many different tables that are effectively views into the same data set. We could have tables like customers by order, order by customer, orders by location, and so on. Cassandra can serve out those views with very high performance and scalability.
So, together, Kafka and Cassandra solve a large challenge—moving data from where it sits today to destinations where it is accessible and useful to modern architecture. Along the way, Spark Streaming can help enrich that data, making it more meaningful and useful.
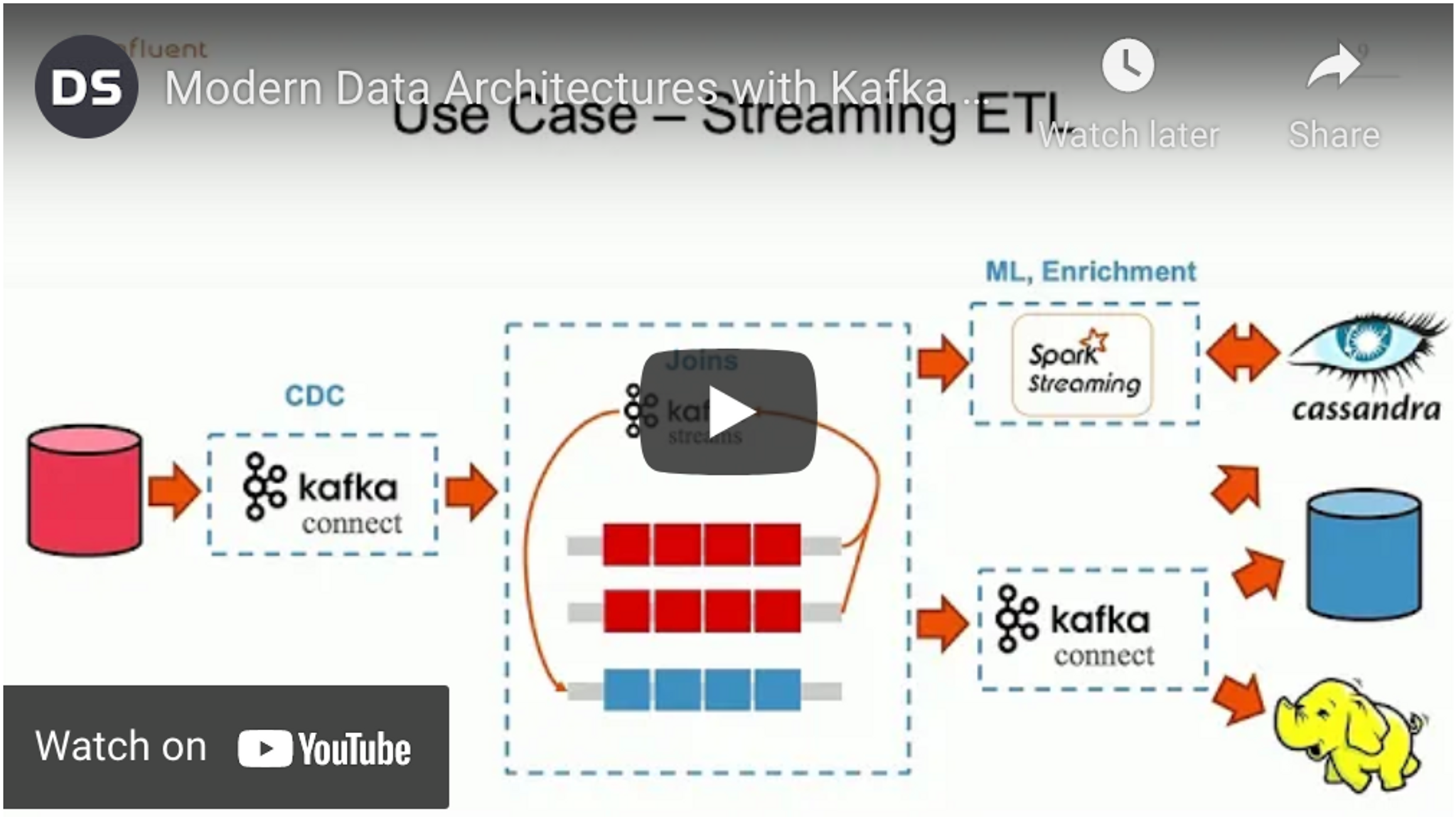
Use case – Streaming ETL (extract, transform, load)
ETL, or extract, transform, load, is, by far, the most common Kafka/Cassandra use case Cliff comes across. When it comes to data and databases, systems often don’t talk to one another. Maybe the order system doesn’t talk to the inventory system, which doesn’t communicate with IoT events, and so on. It’s important to move that data to a solution that can handle and scale reads. It might need to land in a data lake or even a relational database, if you need to run complicated queries.
Different pipelines can be used to integrate the data into Cassandra. You might have a Spark Streaming ingest feed running a scoring algorithm based on machine learning, while, at the same time, use a raw data feed coming in through Kafka Connect to serve different tables and answer query questions. If needed, the raw data can go through, along with the enriched data. You can have both a stream processor and a raw connect feed, both feeding your downstream systems. From there, you can fan the data out in many ways to wherever it needs to go.
When change data capture (CDC) information is coming in from a relational database, what does it look like? Is it buttoned-up, nicely packaged, enriched data? Nope. It’s much more likely to be a mess with many fragmented tables all updated at different times or as part of one transaction. Imagine this kind of scenario when dealing with orders: The order has a customer ID and that customer ID maps to an address table, which has five different addresses for that customer and that maps to the customer master table. That data needs to be stitched back together. It needs to be denormalized into something usable. That's where Kafka Streams comes in. It provides a layer that can take two topics coming in, stitch them back together, and then output them into another topic which then feeds all downstream systems.
Another option is to deploy a filter, where you create a new stream that's a subset of the data coming in to answer a specific question in Cassandra. Kafka can become a data catalog of streams that you can land wherever they are needed. This keeps things clean and simple, instead of the norm of battling a spider web of ETL. It’s much better than dealing with one-off ETL point-to-point integrations, all across the organization, each one with a different instance of a messaging technology. Instead, with Kafka, you could have five different Cassandra tables, all sourcing from the same topic. That solves a lot of database hydration challenges.
And, if you have a lot of data, using compacted topics in Kafka is another great way to hydrate things. It does a lot of the same things a Cassandra table does (but not querying, since Kafka isn’t a database). It provides the latest value for every key.
You can spin up a Cassandra cluster, stand up a connector, hydrate that database and have it up and running in less than a day—without initial bulk loads and some of the harder parts of standing up a new application database. This can be an on-demand thing for teams that want to build new apps with Cassandra. That team could simply be given permissions for that topic and, as owners of the application database, they can stand up their Cassandra database and push a button to get data flowing into it. And they can quickly rebuild views. The team may have a totally different structure they want and can configure their connector to meet their needs. They could run a streams job and use Spark Streaming or Kafka Streams to enrich their data.
Other Apache Cassandra + Kafka Use Cases
Let’s look at other common use cases Cliff has seen where the Kafka plus Cassandra combination has proven to be beneficial.
Use case – APIs
Even though we need to find efficient ways of moving data out of legacy systems, the reality is most of those dinosaurs aren’t going extinct any time soon. That means, if a change occurs through an API, the modified data also needs to reside in the original legacy system because that’s the source of truth for many organizations. Let’s say a customer changes their email on the website. We would capture that interaction and write it back into Kafka. From there, we can both write to Cassandra, to have the latest value being served out, and to the source of truth system that is our master system. Obviously, we’d prefer to have the API just write to modern systems, with nothing going back to the source system. However, these legacy systems have built up over decades and rewriting them is no fun. For the time being, Kafka allows you to deal with this nuisance by fanning out updates to both your new and old systems, ensuring they stay in sync over time.
Kafka can also help solve an issue it’s easy to run into with microservices where you have a messy mesh of things all calling each other. Cliff recalled seeing numerous microservices 1.0 projects fail because of this problem. Consider an API for orders. Do we want it calling on customer data for every single order? That’s not very scalable. Instead, what if the order service also had access to all the changes to customer data? That way, the order service in the Cassandra database can effectively build in the customer metadata. If order data is needed, just call order. If customer data is needed, just customer. They don’t have to talk to each other. This creates a decoupling of your services that allows for independent scalability. Kafka removes these microservices meshes. Otherwise, the situation might require writing custom software to track the flow of your application through it.
The costliness of reads is another area the Kafka/Cassandra team up can help. According to Cliff, reads are the most expensive aspect of a relational database. He said they just crush the database. Cassandra is the perfect place to move them. Cliff also said he often hears about organizations saving tens of millions of dollars by pulling reads off their relational databases.
Use case – IoT Event Enrichment
Many like to use Cassandra for time series data and IoT use cases are common. And IoT events often need to be enriched with data. Otherwise, a reading from a particular sensor wouldn’t mean much. You need additional data, such as its purpose and location. As these events come in, you can join them together, transform them, enrich them with metadata, and push them downstream in a very read-optimized way to Cassandra. And you can do it all without an external call. It enables joins, aggregations, and filters to be conducted in flight.
You can also use this pattern to prefilter the data so that what remains is what people actually want to query. That keeps the footprint small, makes it easier to manage, and allows you to serve more queries.
Your read system no longer has to deal with data you don’t care about. Of course, that doesn’t mean you have to lose your raw data. You can move it into a file system and save it in perpetuity.
Use case – Log Management
Log management is critical for visibility into what's going on across all your networks and applications. Luckily, Kafka makes it easy. There are connectors that will listen to syslog messages, format them, and put them in Kafka, allowing you to join them with your reference data. Kafka’s aggregation layer enables you to join data as it flows through and then make it easily available downstream. Then, you can build a search index to visualize your logs and look for errors. You could also run Spark for anomaly detection or to match some of your models.
Indexing is computationally expensive, and data is not smooth. It comes in in bursts. That spiky nature makes it difficult to size for as it flows in. Fortunately, Kafka is great at throttling for you. If the data can’t be read, Kafka will keep holding it and until you can catch up at some later point. Otherwise, it’s difficult to keep the flow of data from overwhelming the search indexer. Kafka allows building search indexes that have consistent performance over time.
Kafka and Cassandra: A great combination for modern architectures
An architecture that combines Kafka and Cassandra can certainly make life easier, especially if you’re dealing with legacy systems. And, when it comes to data ingestion and enrichment, Spark Streaming and Kafka Streams integrate smoothly into these environments. As we’ve seen, together, these technologies can tackle several key use cases that otherwise might keep you up at night.
As Cliff Gilmore emphasized, “I see it repeated over and over in the field. If you have a mission-critical, user-facing application…if you work with Kafka and Cassandra, you're able to provide the best customer experience, the best latency between when that data was generated to when it's available to serve out…And your modern applications can integrate right in with everything else…This kind of synergy allows for solving some things that were extremely hard to do in the past.”
What is Apache Kafka?
Why use Kafka?
How does Kafka work?
How does Kafka scale?
How does Kafka handle streams?
Architecture with Kafka + Cassandra + Spark
Use case – Streaming ETL (extract, transform, load)
Other Apache Cassandra + Kafka Use Cases
Use case – APIs
Use case – IoT Event Enrichment
Use case – Log Management
Kafka and Cassandra: A great combination for modern architectures
More Company
View All

The Top 5 DataStax Stories from 2023

