The Year in Real-Time for Apache Pulsar and Streaming

The rate of growth, and the need for global deployment of data is skyrocketing. Yet the most powerful data of all is real-time data. How did open source projects like Apache Pulsar make real time data more accessible for developers in 2022?
In part one of this blog series, we examined why real-time data is so hard for organizations to leverage and practitioners to implement. In this part two, and the next part three, we’ll look at how Pulsar and Cassandra have made an impact in 2022.
Streaming Data in Real-Time
A majority of active event streams deployed today range from incomplete to nonexistent. That’s because the historically common mechanisms used to capture these events, like JMS and MQ messaging platforms, predate the widespread need for real-time data. Their designs were optimized for reliable event delivery/broadcast, after which events are immediately purged out of existence. Modern real-time systems persist a record of event streams so that there is an immutable record of state changes/events for your code to work against. That’s why using traditional messaging makes it difficult for developers to generate real-time event streams, and devalues the applications built that way. Most importantly, their monolithic designs also predate cloud-scale, and will break down as volume of data increases.
Apache Pulsar™ is a multi-tenant, high-performance messaging and streaming platform for managing billions of events in real-time. It supports multiple clusters in a Pulsar instance, built in geo-replication of messages across clusters, low latency transmission, and scales to over a million topics. Pulsar was designed with a modular, non-monolithic architecture for geo-replication, durability, and horizontal scaling using commodity hardware. It combines the best features of traditional messaging with those of pub-sub systems and can scale up and down dynamically. If you’re new to Pulsar and/or messaging/streaming, this video quickly explains why it’s becoming a very popular choice for real-time, cloud-scale data in about 5 minutes:
The Pulsar community made a lot of progress in 2022, with more than 1600 commits across five releases:
2022 saw a dramatic increase in activity across monthly active contributors and commits versus 2021. Also, the community also completed a benchmark using Linux Foundation’s Open Messaging Benchmark, showing some impressive results compared to Apache Kafka, updating the 2019 version of the benchmark. DataStax is very active in the Pulsar community today, and is excited to help move the project forward by contributing to the project, pushing the limits, taking a dependency on Pulsar for DataStax’s cloud-native, event streaming service built on Apache Pulsar: Astra Streaming.
Streaming Data in Real-Time (as-a-service)
Like so many things today, streaming systems are also being re-imagined to be fully cloud native: modular & serverless. This past year saw the debut of Astra Streaming, a cloud-native, event streaming service built both on the distributed architecture of Apache Pulsar and Astra’s serverless operating model. At cloud scale, building on a non-monolithic and scale-to-zero-if-idle foundation is a key ingredient in changing unit economics for streaming—while maintaining real-time performance levels. Delivered as SaaS that runs on AWS, Google Cloud, and Azure, your team won’t have to develop the expertise needed to operate Apache Pulsar, or be on the hook for the SLA/SLO.
Through a wide range of connectors, Astra Streaming is connected to your data ecosystem, enabling real-time data to flow instantly from data sources and applications to streaming analytics and machine learning systems. It's used for everything from data integration, event-driven architecture, edge computing and IoT, and operational machine learning to real-time analytics.
Traditional Messaging in Real-Time
The Pulsar ecosystem is a vibrant place that is extending the core project. Among many other awesome projects, it’s home to three “Starlight” Apache-licensed ecosystem projects. Starlight provides wire-level compatibility with traditional messaging APIs, enabling your existing applications to take advantage of Pulsar’s incredible performance and horizontal scalability without requiring them to be rewritten.
- Starlight for JMS is the first highly compliant JMS implementation designed to run on a modern streaming platform like Apache Pulsar.
- Starlight for Kafka brings native Apache Kafka protocol support to Apache Pulsar by introducing a Kafka protocol handler on Pulsar brokers.
- Starlight for RabbitMQ acts as a proxy between your RabbitMQ application and Apache Pulsar.
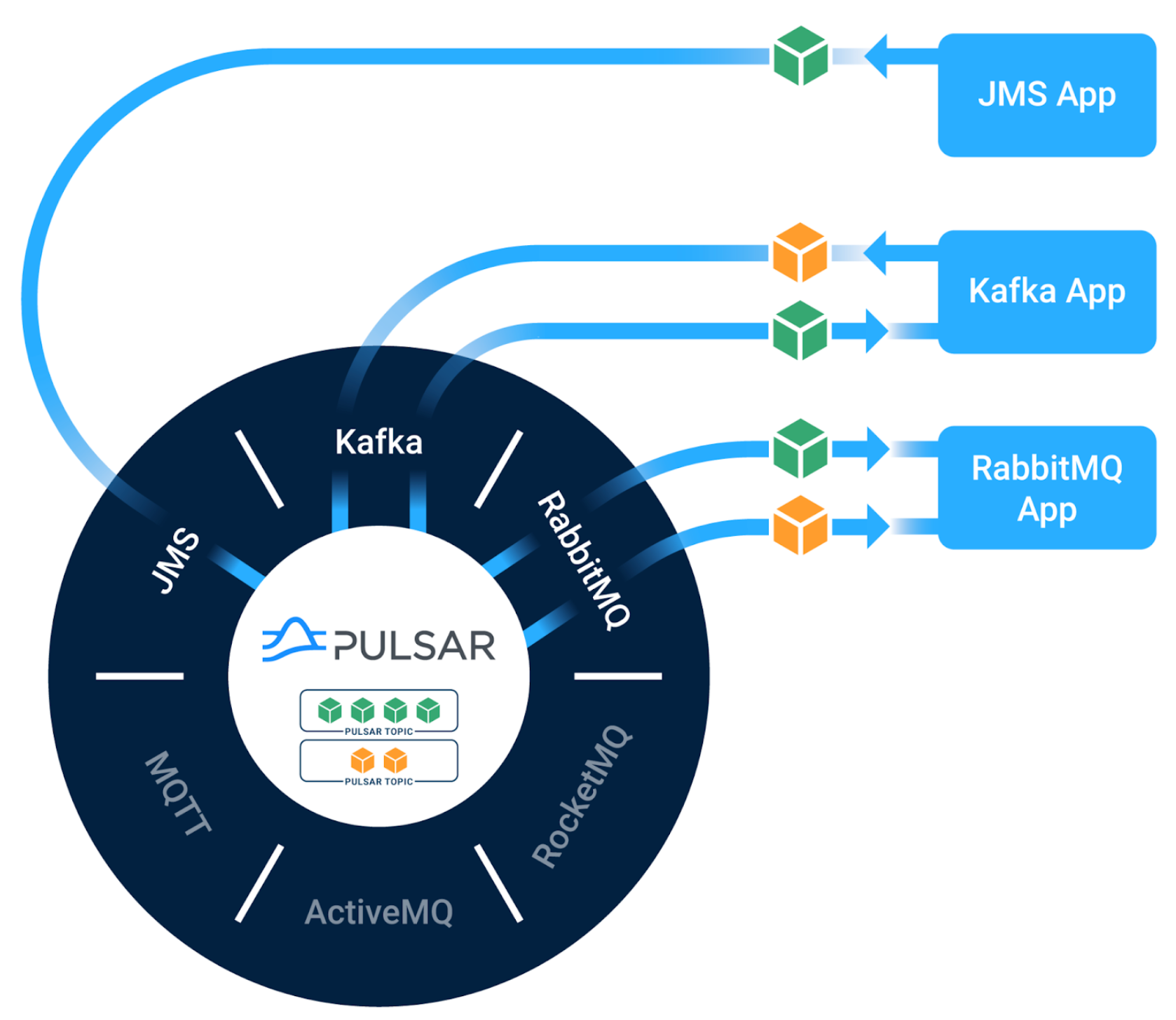
Astra Streaming integrated the Starlight projects into its managed cloud service when it launched in 2022, bringing full wire-level API support for Kafka, RabbitMQ, and JMS (Java Message Service). Development teams get a single messaging and streaming approach, exiting entire realms of operational complexity via a managed, multi-cloud service.
So what gains should you expect to see? Let’s ignore the added Starlight features for the moment and just focus on raw performance. Starlight for JMS clocked in some impressive results using the Linux Foundation's Open Messaging Project, a vendor neutral benchmark kit:
- One million messages per second over a two hour duration, sustained on both the producer and consumer workers, on a modestly-sized Pulsar cluster.
- A 99th percentile publishing latency under 10 milliseconds. A larger Pulsar cluster will be able to achieve even lower latencies on the tail of the curve.
- Over 80% of the end-to-end latency is between six milliseconds and 14 milliseconds, and is remarkably stable.
Apache Pulsar Functions are another area of open source innovation in 2022. Pulsar Functions abstract away the details normally handed by dedicated stream processing engines like Apache Storm. This includes the function’s execution environment, resilience, handling message delivery guarantees. They also emulate the serverless operating and programming model of cloud functions (AWS Lambda, Google Cloud Functions, Azure Functions). The processing logic can be anything that you can fit in a function, including data transformations, dynamic routing, data enrichment, analytics. Function logic can be written in Java, Python, and Golang. By locating the function inside the Pulsar cluster, overall latency is added to get the value of the operating and programming model, but is minimized versus an external cloud function.
DataStax also improved the Pulsar Functions framework with DataStax Pulsar Transformations that allow it to run advanced data manipulation without writing code. With the DataStax Luna Streaming distribution and the upcoming Apache Pulsar 2.12, users are able to run a Function next to a Pulsar Sink (see PIP-193) in order to eliminate the need for intermediate topics when you need to preprocess your data before pushing it to the final destination.
Want to get started with Pulsar? This next video shows you how to get started with a free Astra Streaming instance in about 5 minutes.
Astra Streaming also powers the ability for Astra DB to synchronize disparate data systems using change data capture (CDC) reimagined for cloud native systems.
Change Data Capture in Real-Time
Ever embedded an object into a google or microsoft office document? Whenever the original copy gets changed, all the downstream embeds are automatically updated. Pretty nice, right? Now imagine the same thing for enterprise data and you’ve got the essence of change data capture (CDC). It's great when you want to keep data in sync between systems, across a variety of use cases like:
- Data integration
- Machine learning
- Advanced search
- Reporting and analytics
- Security monitoring, notifications
CDC is an evolution of the traditional ETL (Extract Transform and Load) technique for getting data from a source to potentially multiple target systems using batch processing. With CDC, database events are replicated to other databases or downstream systems in real-time, keeping them in sync. Unlike ETL, CDC does not attempt to process data in large batches. Data is continuously loaded as the source database changes and kept in sync to the target. With the volume and velocity of modern data, this approach isn’t just more efficient — it’s the only way to keep pace. Messaging and Streaming is a common companion for delivering these database change events: data-in-flight needs delivery guarantees, ordering semantics, retry logic, queuing, pub-sub, and more to ensure data integrity between source and target.
Streaming isn’t the only thing being re-imagined to be fully cloud native: this year also introduced CDC for Astra DB, built on both Astra’s modular, serverless foundation, and Astra Streaming. Using a simple configuration driven approach, you can enable CDC on one or more of your Astra DB tables and publish the changes to an event topic in Astra Streaming. From there, your real-time applications can subscribe to change events using client libraries in Java, Golang, Python, or Node.js. Additional endpoints support direct subscription via websocket interface or using a standard JMS client.
If the destination of your CDC data is another platform such as Snowflake, ElasticSearch, Kafka or Redis (to name just a few), Astra Streaming also allows you to create real-time data pipelines through a simple configuration-driven interface using the built-in connector library. A very common usage for CDC with Cassandra-based systems is to replicate data to Elasticsearch for full text search and other analysis as you will see in the demo below:
CDC for Astra DB can also be used to keep multiple Cassandra tables / keyspaces / databases in sync as well:
With CDC for Astra DB powered by Astra Streaming, a ton of heavy lifting is handled for you so you can focus on authoring business logic – not plumbing, boilerplate, or glue code.
In the next blog in this series, we’ll talk about the impact of a non-volatile (durable) operational database for real-time, cloud scale developers.
More Company
View All

The Top 5 DataStax Stories from 2023

