“Finding specific policies and operating procedures is time-consuming and challenging due to scattered storage across various platforms. Using Astra DB's vector search capabilities, SkyPoint can leverage these benefits to enhance its services, offering users real-time, contextual, and personalized solutions. This leads to accurate predictions and personalized healthcare outcomes at a lower cost.”
Astra platform
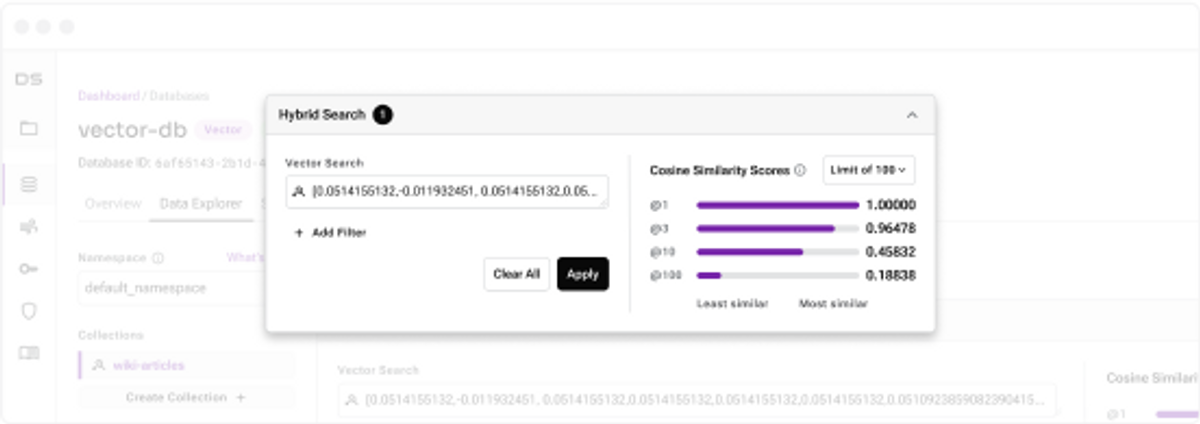
Vector Search for Real-world GenAI
An easy-to-use API with all of the vector and structured data for production Retrieval Augmented Generation (RAG) applications.

Analyst Study
GigaOm Vector DB Comparison: Astra DB 9x’s Pinecone in Throughput, 74x in Latency, 20% in Relevance, and 80% better TCO.
Learn more
Blog
Build AI apps compatible with the new Open-AI Assistants API using Astra and your own data.
Learn MoreBuild accurate AI with real-time data and streaming.
Astra DB vector is for mixed workloads with vector, non-vector, and streaming data.
Only Astra DB vector gives you simultaneous query/update with ultra-low latency.

Support your entire app, not just vector search.
You’ll need to use your vector, tabular, and streaming data for accurate LLM replies.
Astra DB vector is a natively unified database for your entire application. Standalone vector databases require stitching and moving data from system to system.
Deploy production-level security and compliance.
Protect users and data with the depth enterprise security features and compliance certifications for production AI.
Standalone vector databases were designed for simple applications and workloads - not for enterprise-scale requirements.
Developer-friendly APIs, pricing and community support.
Code today and launch tomorrow with vector-native APIs and ecosystem integrations.
Astra DB gives developers the industry’s most generous developer plans, APIs, community support, and choice of deployment options.
Market leaders shaping their industries with Vector Search from Datastax






Developers
RAG Made Easier
An intuitive API and powerful integrations for production-level RAG and FLARE.
Install
Install the AstraPy library
pythonjavascriptjava
pip install astrapy
npm install @datastax/astra-db-ts
Maven:
<dependency>
<groupId>com.datastax.astra</groupId>
<artifactId>astra-db-client</artifactId>
<version>1.2.4</version>
</dependency>
Gradle:
dependencies {
implementation 'com.datastax.astra:astra-db-client:1.2.4'
}Create
Create or connect to existing collection
pythonjavascriptjava
# The return of create_collection() will return the collection
collection = astra_db.create_collection(
collection_name="collection_test", dimension=5
)
# Or you can connect to an existing connection directly
collection = AstraDBCollection(
collection_name="collection_test", astra_db=astra_db
)
# You don't even need the astra_db object
collection = AstraDBCollection(
collection_name="collection_test", token=token, api_endpoint=api_endpoint
)
// Create a vector collection
const collection = await db.createCollection("collection_test", {
vector: {
dimension: 5,
metric: "cosine",
},
});
// Or you can connect to an existing collection
const collection = await db.collection('collection_test');
AstraDB db = new AstraDB("token", "endpoint");
AstraDBCollection collection = db.createCollection("vector_test", 5);Insert
Inserting a vector object into your vector store (collection)
pythonjavascriptjava
collection.insert_one(
{
"_id": "5",
"name": "Coded Cleats Copy",
"description": "ChatGPT integrated sneakers that talk to you",
"$vector": [0.25, 0.25, 0.25, 0.25, 0.25],
}
)
const doc = await collection.insertOne({
"_id": "5",
"$vector": [0.25, 0.25, 0.25, 0.25, 0.25],
"name": "Coded Cleats Copy",
"description": "ChatGPT integrated sneakers that talk to you",
});collection.insertOne(new JsonDocument()
.put("text", "ChatGPT integrated sneakers that talk to you")
.vector(new float[]{0.1f, 0.15f, 0.3f, 0.12f, 0.05f}));Find
Find documents using vector search
pythonjavascriptjava
documents = collection.vector_find(
[0.15, 0.1, 0.1, 0.35, 0.55],
limit=100,
)
const results = await collection.find(null, {
sort: {
$vector: [0.15, 0.1, 0.1, 0.35, 0.55],
},
limit: 100,
})
.toArray();
float[] embeddings = new float[] {0.1f, 0.15f, 0.3f, 0.12f, 0.05f};
Filter metadataFilter = new Filter().where("text", EQUALS_TO, "ChatGPT");
Stream<JsonDocumentResult> rag =
collection.findVector(embeddings, metadataFilter, 10);Try for Free
$300/year in free credit and no credit card required.
Explore examples
Tutorials and sample Generative AI apps with best practices.
DOCS
Get started in minutes with Generative AI and RAG.
Vector crash course with Ania Kubow
Build a chatbot with LangChain, Open AI and Astra DB chatbot.

Key vector search use cases
Generate real-time AI applications with Vector Search, empowered by advanced Language Models (LLMs) and Chat AI Agents.
Integrations
Enhance your AI/ML applications and ecosystem with contextual data insights and automations.




CassIO
Library seamlessly connects Apache Cassandra and Generative AI frameworks like LangChain
Join the Community
Plug into the real-time conversation on the community’s Planet Cassandra Discord channel.
FAQ
FAQ
What is a vector database?
Vector databases like Datastax Astra DB (built on Apache Cassandra) are designed to provide optimized storage and data access capabilities specifically for vector embeddings, which is the mathematical representation of data. Vector databases provide multi-dimensional representation of structured and unstructured data and enable functions like vector search on large corpora of data.
What is vector search and how does it relate to a vector database?
Vector search associates similar mathematical representations of data, and vector representations, converting queries into the same vector representation. With both query and data represented as vectors, finding related data becomes a function of searching for any data representations that are the closest to your query representation, known as nearest neighbors. Vector databases provide the storage and retrieval of data representations for vector search called vector embeddings. Since data is represented across multiple dimensions, vector databases need to be highly scalable and highly performant.
How does vector search work?
The concept of nearest neighbor is at the core of how vector search works and there are a number of different algorithms that can be used for finding nearest neighbors depending on how much compute resources you want to allocate and/or how accurate you are looking for your result to be.
Is Vector Search compatible with cloud-based and on-premises data environments?
Vector search doesn’t have a concept of where the data is stored so can be used for cloud-based or on-premise data environments. Solutions like Astra DB are built to provide a cloud-native data platform ideally suited for building generative AI applications powered by vector search, however, on-premise solutions like Datastax DSE are also being used for vector search capabilities.
Cloud-based solutions tend to be more commonly deployed as they provide the scalability for additional storage and compute resources on demand depending on the application's requirements.
Which industries can benefit from vector search?
Vector search is not limited by a specific industry and can be leveraged by use cases across all industries. Building recommendation engines using vector search offers improved customer engagement and visibility. Vector search can also be used to build natural language processing chatbots that interact with product documentation in real time to provide the right answer at the right time.
Vector search is the latest approach to data organization and access and allows applications the ability to leverage generative AI across all industries.
Is Vector Search suitable for large-scale data sets?
Vector search can be used on small, medium, or large data sets interchangeably. However, the important thing to remember is that with small datasets a lot of the compute and storage overhead can be maintained in the application space. For medium to large datasets applications, you should leverage a high-performance vector database like AstraDB, allowing for the decoupling of data storage from the application. This allows for applications to reuse and leverage vector data across multiple application instances and frees up resources in the application.
What sets DataStax's Vector Search apart from other similar solutions on the market?
One of the primary differences between DataStax vector search and other offerings in the market is that DataStax AstraDB is built on Apache Cassandra, which for over 15 years has been used to provide a highly scalable, highly performant approach to unstructured data storage and retrieval via NoSQL functionality. Most of the solutions in the market today are single-solution approaches to providing vector databases for vector storage. DataStax provides a proven/hardened solution to handling the massive scalable and performance demands generative AI applications need.
In addition, while many solutions are available for vector search, DataStax Astra provides a completely integrated platform for building generative AI applications. More than just a vector database, more than just vector search, DataStax Astra provides the ability to leverage orchestration frameworks like LlamaIndex and LangChain to simplify the generative AI application development and enable end-to-end vector lifecycle management.