Airbyte and DataStax Simplify GenAI and RAG App Development

Aaron PloetzDeveloper Relations

When developing retrieval augmented generation applications, the process of ingesting data and creating embeddings can be a real pain for developers, significantly extending the time it takes to get an app to production. Shortening development cycles, simplifying data loading, and accelerating the creation of vectors are key ways to lighten the load that so many face when building generative AI apps.
That’s why we’re excited to tell you about a new partnership between DataStax and Airbyte that offers a DataStax Astra DB data destination in the Airbyte Cloud data pipeline. This enables Airbyte’s community of 40,000 developers to easily move data and generate embeddings within Astra DB, helping them to quickly build powerful AI-driven applications. This post will discuss how Airbyte Cloud and Astra DB work together to supercharge the development process of AI-driven applications.
What is Airbyte Cloud?
Airbyte Cloud is a cloud data pipeline that helps developers find solutions to difficult ETL (Extract, Load, and Transform) problems. It can be deployed as open source or as a managed service, and can be customized to the required scale. Airbyte Cloud is a low-code solution, and has a wide variety of connectors that allow for easy integration with multiple data sources.
How does Airbyte Cloud work with Astra DB?
Essentially, Airbyte Cloud works as an ingest source for Astra DB. In this way, the data set can be prepared and kept up-to-date asynchronously from the overall application. Figure 1 below shows how Airbyte Cloud interacts with large language model (LLM) providers like OpenAI, and persists its data and embeddings into Astra DB.
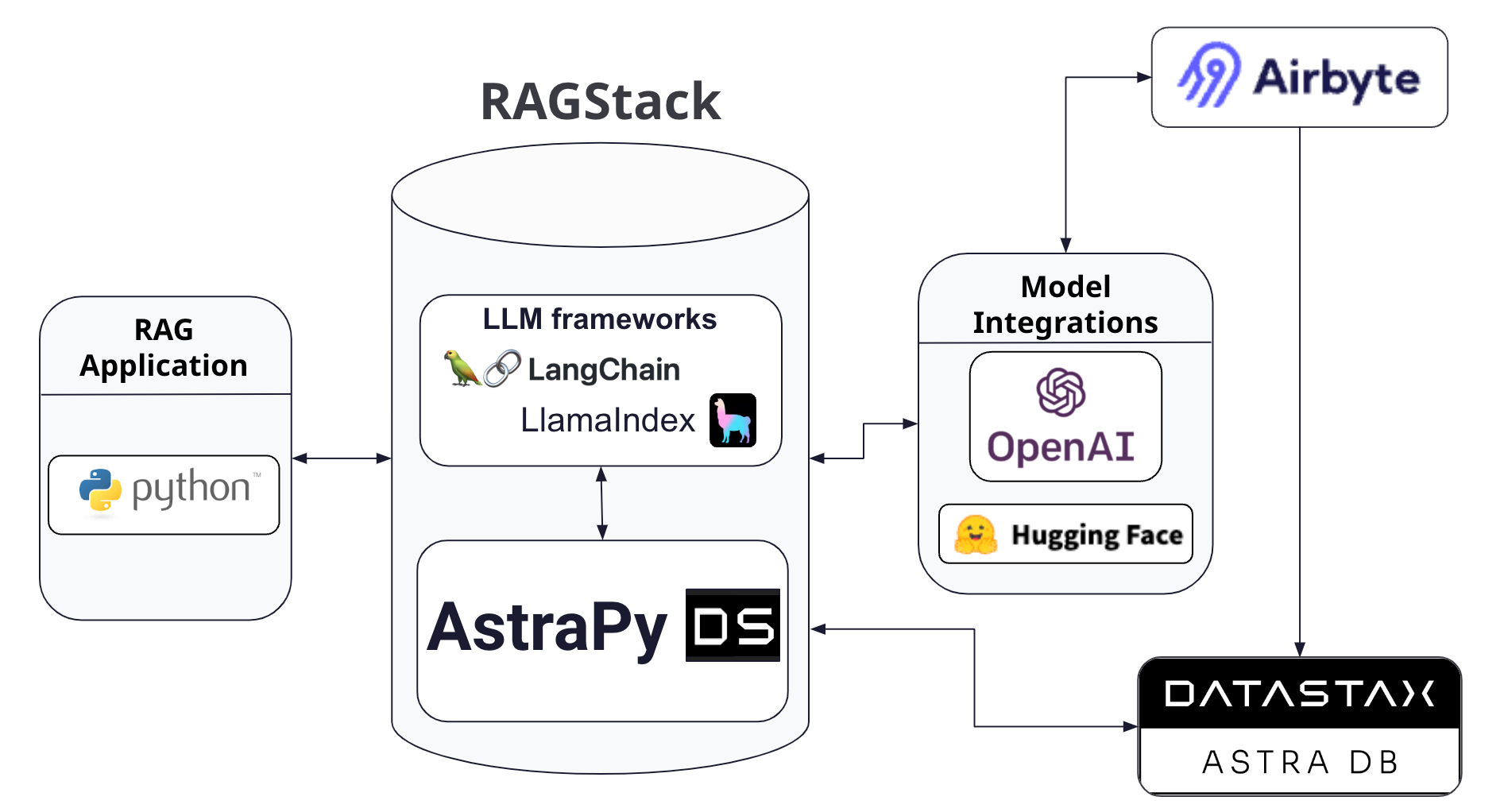
Figure 1 - An architecture diagram showing how Airbyte works with DataStax RAGStack.
Building a simple GenAI application with Airbyte Cloud and Astra DB
Here we’ll walk through how to build a simple application using a data pipeline from Airbyte Cloud. Our Airbyte Cloud pipeline will pull webcomic data from the XKCD API, and store it in Astra DB. Our application will then be able to run similarity searches on the vector embeddings to bring back data on the most-similar XKCD webcomic (example webcomic shown in Figure 2).
 Figure 2 - A sample XKCD comic, which is “a webcomic of romance, sarcasm, math, and language.”
Figure 2 - A sample XKCD comic, which is “a webcomic of romance, sarcasm, math, and language.”
Setup
Before we can code our Python application, we need to set some things up. We’ll need to create accounts with Airbyte and Astra DB. And of course, we’ll need to add a few libraries to our Python environment. We will need:
- A development environment with Python 3.9 or higher.
- A free account with Astra DB.
- A free account with Airbyte.
- An OpenAI API key.
Astra DB
First, we should sign up for a free Astra DB account, and create a new vector database. Once the database comes up, be sure to copy your application token and API Endpoint.
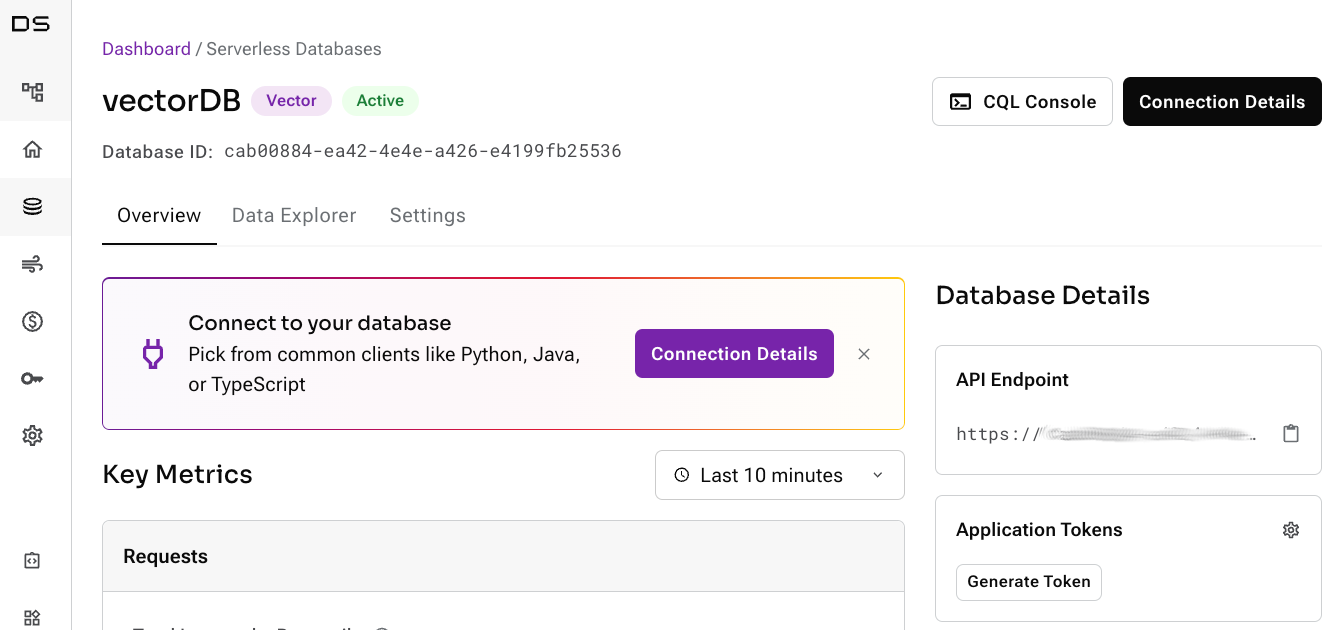
Figure 3 - The Astra DB dashboard, showing where to obtain the Application Token and API Endpoint.
Airbyte
Next, we can navigate to https://airbyte.com and create a new, free account. Once our account is set up, we can then navigate to our Airbyte Cloud workspace at https://cloud.airbyte.com, and set up a source in our data pipeline.
The XKCD data source
Click on “Sources” in the left nav, and click the “New source” button. Search or scroll to the “XKCD” community source connector, and click on it. The XKCD source connector doesn’t have any special parameters, other than “Source name.” This can be left as “xkcd.”
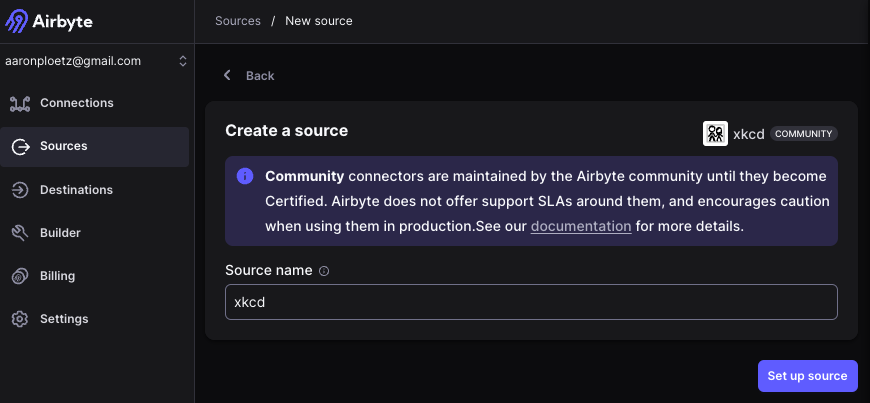
Figure 4 - The XKCD source connector in Airbyte.
With the parameters set, we can click the “Set up source” button. We can now set up a new destination for Astra DB.
The Astra DB destination
Click on “Destinations” in the left nav, and click the “New destination” button. Search or scroll to the “Astra DB” destination. On the “Settings” tab, set the following parameters:
- Destination name: “Astra DB”
- Chunk size: “512”
- Fields to store as metadata: “title” “img” “alt”
- Text fields to embed: “title”
- Embedding: “OpenAI”
- OpenAI API key: our OpenAI API key should go here
- Astra DB Application Token: Our Astra DB Application Token from above should go here
- Astra DB keyspace: “default_keyspace”
- Astra DB collection: “airbyte”
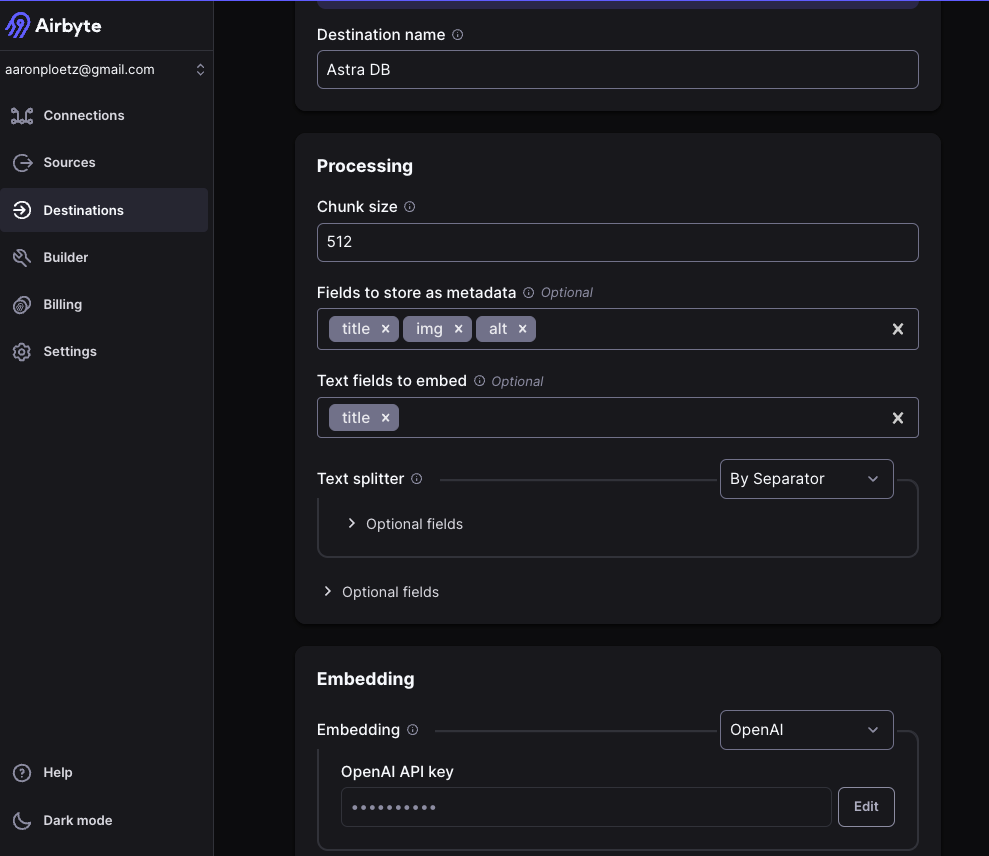
Figure 5 - A partial view of the Astra DB destination connector in Airbyte, showing the properties to be set for text processing and embedding generation.
Important points to note about this process:
- If a parameter is not mentioned, it is fine to leave it as is.
- Specifying “OpenAI” for the embedding parameter will use the “text-embedding-ada-002” model to generate the vector embeddings with 1,536 dimensions.
- The vector embeddings will be generated from the “title” property of each comic.
- The metadata fields of “title,” “img,” and “alt” should be specified to keep the document size low. Some of the “transcript” field entries in particular can exceed Astra DB’s limit of 8000 bytes.
- Do not worry about creating the “airbyte” collection, as our Airbyte connection will take care of that for us.
With the parameters set, we can click the “Set up destination” button.
Create a connection
With both our source and destination defined, we can create a new connection. Click on “Connections” in the left nav, and click the “New connection” button. Select XKCD as the source, and Astra DB as the destination. When the new connection has completed processing, we can adjust the parameters concerning data residency and synchronization. For now though, we can just click on the “Set up connection” button (at the bottom).
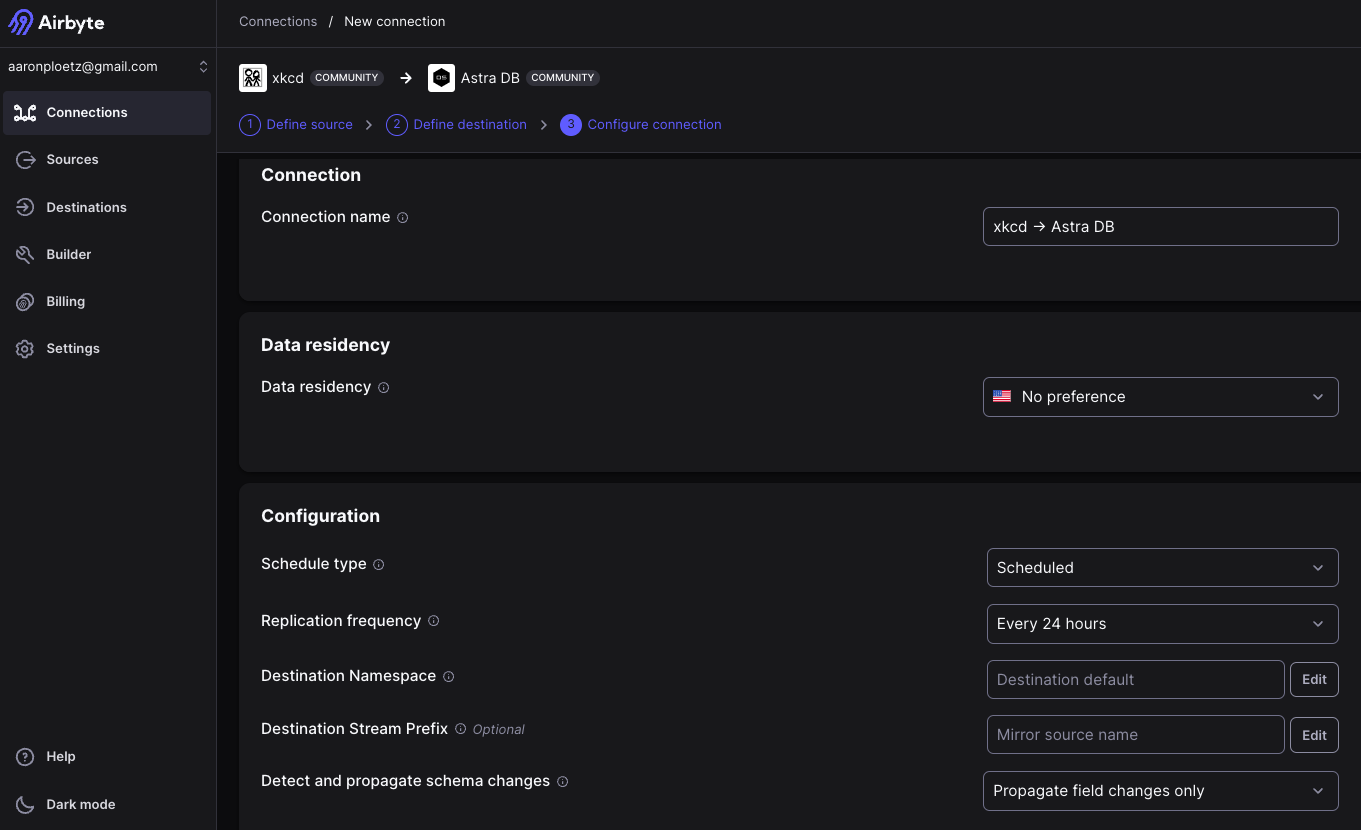
Figure 6 - Creating a connection in Airbyte, using our XKCD source and Astra DB destination.
Once the connection has finished data synchronization (this could take up to five minutes), we should be able to see data in the “airbyte” collection from the “default_keyspace” namespace in Astra DB. We can now move on to our simple application.
Python environment
For our application, we require libraries for LangChain and AstraPy. Fortunately, DataStax’s RAGStack Python library has everything that we need—already tested end-to-end for compatibility. We will also want to use Python’s DotEnv library (to read from an .env file). We can them both with this command:
pip install ragstack-ai python-dotenv
We will also want to create a new file named “.env” and define the following environment variables:
ASTRA_DB_APPLICATION_TOKEN=AstraCS:blahblah:blahblahYourTokenGoesHere ASTRA_DB_API_ENDPOINT=https://your-endpoint.apps.astra.datastax.com ASTRA_DB_KEYSPACE_NAME=default_keyspace ASTRA_DB_COLLECTION_NAME=airbyte OPENAI_API_KEY=sk-blahblahYourOpenAIKeyFromAbove
Additionally, we will make an entry for the “.env” file in our .gitignore file. This will prevent our credentials from being uploaded to our GitHub repository.
Building the application
Now we can build a simple application to query our new dataset. We will start by creating a new Python file named “airbyte_query.py” with the following imports:
import os from dotenv import load_dotenv from astrapy.db import AstraDB from langchain_openai import OpenAIEmbeddings
Next, we will use the DotEnv library to bring in the variables defined on our .env file, and initialize our model to use OpenAIEmbeddings:
load_dotenv() model = OpenAIEmbeddings()
With that complete, we can define our connection to Astra DB, using the variables brought in by the load_dotenv() method:
db = AstraDB(
token=os.environ["ASTRA_DB_APPLICATION_TOKEN"],
api_endpoint=os.environ["ASTRA_DB_API_ENDPOINT"],
namespace=os.environ["ASTRA_DB_KEYSPACE_NAME"],
)
collection = db.collection(os.environ["ASTRA_DB_COLLECTION_NAME"])With that in place, we can check for a query from the command line, and default to the simple query string of “Kepler” if one is not present. We will also create a vector embedding for it:
if (len(sys.argv) > 1):
query = sys.argv[1]
else:
query = "Kepler"
vector = model.embed_query(query)Finally, we can execute a vector similarity search using our vector embedding, and print the results:
res = collection.vector_find_one(vector,fields=['title','img','alt']) print(res)
Demo
If we run our code, we should see the following output:
> python airbyte_query.py
Query="Kepler"
{'_id': 'f3201311-f41c-40ac-be3f-ca1679be8242', 'title': 'Kepler', 'img': 'https://imgs.xkcd.com/comics/kepler.jpg', 'alt': 'Science joke. You should probably just move along.', '$similarity': 0.96341634}We can also run our code with an argument on the command line. This example shows the output when we provide a quoted string of “orbital mechanics”:
> python airbyte_query.py "orbital mechanics"
Query="orbital mechanics"
{'_id': '05f8c7ac-1aa4-429f-a9b3-d97f398514f4', 'title': 'Orbital Mechanics', 'img': 'https://imgs.xkcd.com/comics/orbital_mechanics.png', 'alt': "To be fair, my job at NASA was working on robots and didn't actually involve any orbital mechanics. The small positive slope over that period is because it turns out that if you hang around at NASA, you get in a lot of conversations about space.", '$similarity': 0.96553665}Points to remember
- Airbyte Cloud is an easy to use, low-code solution to ETL data processing.
- Remember to define environment variables in a
.envfile, and add that to the.gitignorefile so that it does not get propagated online. - Specifying OpenAI as the embedding API defaults to the 1536 dimensional “text-embedding-ada-002” model.
- Data synchronization from the XKCD API to Astra DB can take around 5 minutes.
- A Colab Notebook for the application can be found at: https://colab.research.google.com/github/datastax/genai-cookbook/blob/main/Airbyte_xkcd.ipynb
- The GitHub repo for the code shown here can be found at: https://github.com/aar0np/airbyteTest/tree/main
Wrapping up
In this post, we have introduced the Airbyte Cloud managed data pipeline and discussed how it interacts with Astra DB as a “destination.” We then built a simple Python application on Astra DB, leveraging data from a “low code” pipeline that we built using Airbyte Cloud. This clearly demonstrates how quickly and easily an Airbyte Cloud pipeline can be constructed to provide valuable data to an application with a minimal amount of code.
For more information, be sure to check out our Colab notebook and GitHub repository for this project. If you liked this post, be sure to follow me on LinkedIn for similar content.
Join DataStax and Airbyte's April 2 livestream where we'll demonstrate how this new integration simplifies data prep and vectorization. Save your spot now!
What is Airbyte Cloud?
How does Airbyte Cloud work with Astra DB?
Building a simple GenAI application with Airbyte Cloud and Astra DB
Setup
Astra DB
Airbyte
The XKCD data source
The Astra DB destination
Create a connection
Python environment
Building the application
Demo
Points to remember
Wrapping up
More Technology
View All
Introducing the DataStax AI Terraform Module


