What is LangChain? Understanding Key Components and Principles
LangChain aids in implementing the Retrieval Augmented Generation (RAG) pattern in applications, simplifying data retrieval from various sources. How does this contribute to more contextually aware AI applications?
David Dieruf
AI Developer Advocate

What is LangChain?
LangChain is a Python framework designed to streamline AI application development, focusing on real-time data processing and integration with Large Language Models (LLMs). It offers features for data communication, generation of vector embeddings, and simplifies the interaction with LLMs, making it efficient for AI developers.
When you refer to an application as “AI” that usually means it includes interactions with a learning model (like a large language model LLM). The [not so] interesting fact is that the use of an LLM is not actually what makes the app intelligent. It’s the use of a neural network in real time that makes it special. It just so happens that LLMs are built using neural networks. An AI application typically processes data in real-time. That means, that while it has a lot of pre-trained knowledge, it can take in data as it’s submitted to the application and give the LLM up-to-date information.
Alternatives to an “AI Application” are those that include the use of a machine learning model(s). Those apps are still very intelligent but their data processing is more limited to what it has already been trained on. There’s not much real-time information. Pre-training a model versus using a neural network might seem like a minor subtlety because they both appear to be doing the same thing; however, in the data science field, this is a big difference.
AI applications are usually a group of steps that process data as it’s received. When you click to view an item on an e-commerce website, that click event is sent to the website and is processed through an AI Application to decide on other “suggested items” that should be shown on the page. In case you were wondering, yes they are watching. The application would be given the context of what the item being viewed is, what’s in your cart, and the previous things you have viewed and shown interest in. All that data would be given to an LLM to decide on other items you might be interested in.
When you’re building an application like this, the steps in the pipeline choreograph what services should be included, how they will be “fed” the data, and what “shape” the data will take. As you can imagine these are complex actions that require APIs, data structure, network access, security, and a whole lot more.
LangChain is a Python framework that helps someone build an AI Application and simplify all the requirements without having to code all the little details. An example of this is interacting with an LLM. Once all the information is together in a nice neat prompt, you’ll want to submit it to the LLM for completion. LangChain provides pre-built libraries for popular LLMs (like OpenAI GPT) so all a programmer has to do is provide their credentials and the prompt and wait for a response. They don’t need to worry about any of OpenAI’s API specifics like endpoints, protocols, and authentication.
But… LLM interaction is just the beginning of what LangChain can help with. Let’s look at why it is important before diving into some of the framework’s key features.
Why is LangChain Important?
LangChain is important because it represents a significant advancement in the field of natural language processing (NLP). It offers an innovative framework for integrating various language models and tools. This integration enables the construction of more complex and sophisticated AI applications than previously possible. By leveraging LangChain, developers can create AI systems capable of understanding, reasoning, and interacting in ways that closely mimic human communication. This capability is crucial for applications requiring a deep comprehension of language and context.
The significance of LangChain extends to its potential impact across multiple industries. In areas such as customer service, content creation, and data analysis, LangChain can enhance the efficiency, accuracy, and contextual relevance of AI interactions. Its ability to bridge the communication gap between humans and machines opens up new possibilities for the integration of AI into everyday tasks and processes. LangChain's contribution lies in making AI more accessible, intuitive, and useful in a wide array of practical applications.
What are the Key Components of LangChain?
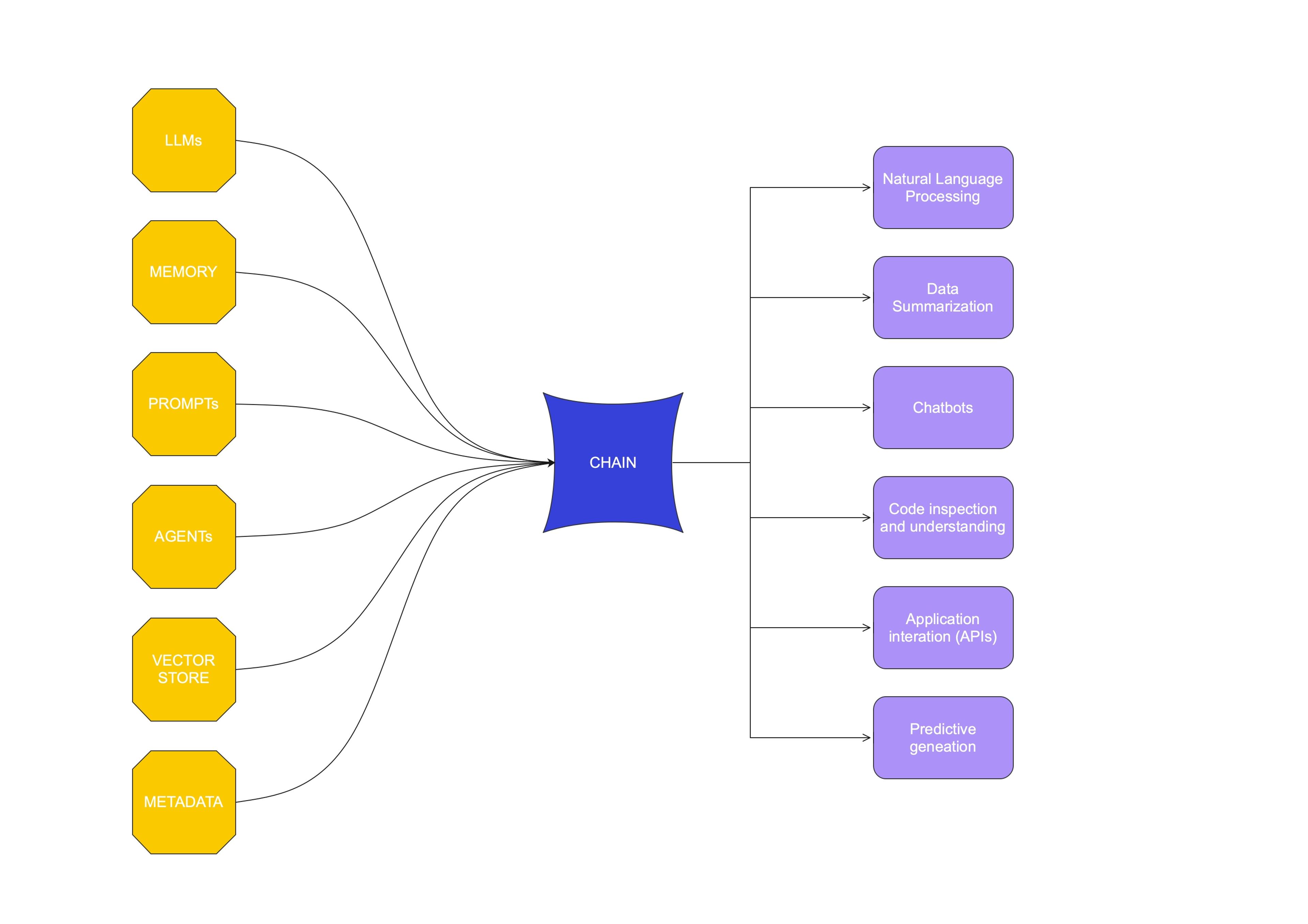
LangChain is a sophisticated framework comprising several key components that work in synergy to enhance natural language processing tasks. These components enable the system to effectively understand, process, and generate human-like language responses. Each component plays a distinct role in the overall functionality of LangChain.
LLMs (Large Language Models)
LLMs are the backbone of LangChain, providing the core capability for understanding and generating language. They are trained on vast datasets to produce text that is coherent and contextually relevant.
Prompt Templates
Prompt templates in LangChain are designed to efficiently interact with LLMs. They structure the input in a way that maximizes the effectiveness of the language models in understanding and responding to queries.
Indexes
Indexes in LangChain serve as databases, organizing and storing information in a structured manner. This enables efficient retrieval of relevant data when the system processes language queries.
Retrievers
Retrievers work alongside indexes. Their function is to quickly fetch the relevant information from the indexes based on the input query, ensuring that the response generation is informed and accurate.
Output Parsers
Output parsers process the language generated by LLMs. They help in refining the output into a format that is useful and relevant to the specific task at hand.
Vector Store
The vector store in LangChain handles the embedding of words or phrases into numerical vectors. This is crucial for tasks involving semantic analysis and understanding the nuances of language.
Agents
Agents in LangChain are the decision-making components. They determine the best course of action based on the input, the context, and the available resources within the system.
What are the Main Features of LangChain?
Below is a summary of the most popular features of LangChain. This is not an exhaustive list of all that LangChain has to offer, but a curated list to call out some of its best features.
Communicating with Models
When building AI applications you’ll need a way to communicate with a model. Probably a large language model (LLM). In addition, you might want to generate vector embeddings when your app is following a RAG pattern, submit a prompt for the LLM to complete, or open a chat session with the model. LangChain has specifically focused on common interactions with a model and made it very easy to create a complete solution. Learn more about models and which LLMs LangChain supports
Typically the application is going to be doing the same action again and again. The prompt used to communicate with a model will have certain text that stays the same no matter what the real-time data is. LangChain has a special prompts library to help parameterize common prompt text. That means the prompts can have placeholders for areas that will be filled in right before submitting the LLM. Instead of doing a very inefficient string replacement on the prompt, you provide LangChain with a map of each placeholder and its value. It will take care of efficiently getting the prompt ready for completion. Learn more about prompts
Once the model has done its job and responded with the completion, there’s a good chance the application is going to need to do some post-processing before continuing. There might be some simple cleanup of characters or (most likely) the completion needs to be included in a parameter of a class object. LangChain's output parsers make quick work of this by offering a deep integration between how the LLM will respond and the application’s custom classes. Learn more about output parsers
Data Retrieval
When a model is created, it’s trained with some data set. A model is considered small or large based on the amount of data that was used during training. For example, LLMs like GPT have been trained on the entire public internet. That amount of data deserves the “Large” label. The challenge is that no matter how much data a model is trained with it’s still a fixed amount. The data doesn’t stop following after the model is finished.
Retrieval augmented generation (RAG) is an application design where the application first compares input data to other recent data to gain a better context. Then that up-to-date context is provided to the LLM to provide an up-to-date response. But it’s not as simple as a quick query and continuing to interact with the LLM. There are a few intermediate steps that have to happen. Also, data has to be stored in an understood format so that retrieval of that data is simple and consistent.
LangChain offers a few libraries to aid in implementing the RAG pattern in an application. First, to gain the right context, data might need to come from different sources. Each source likely follows a different schema. LangChain offers the “document” object as a way to “normalize” data coming from multiple different sources. As a document, data can easily be passed between different chains in a very structured way.
The store that is used to look up up-to-date context is not your typical relational database. It’s a special version of the database that offers to store and retrieve vectors. Most modern databases like AstraDB offer a vector option. There are also vector-specific databases that are built for only the purpose of storing vector embeddings. LangChain offers integrations for all of the popular vector stores, including AstraDB. It also takes things quite a bit further by offering some very convenient features specific to vector search, like Similarity search and Similarity search by vector. You can tune your vector searches with Maximum marginal relevance search. This comes in quite handy when you want to get that context just right - not too much data and not too little data provided to the LLM.
Chat Memory
These days chatbots are all the rage. It’s the “hello world” of AI application development. Thinking about the “chat” concept, when you are chatting with a friend, the conversation has a certain flow to it. As it progresses you both share the history of what has already been said. This helps move the conversation forward.
When an AI Application is chatting with an LLM, it needs to give the LLM some historical information (context) about what is being asked. If no context is given the conversation is going to be quite dry and not very productive. In the previous data retrieval section the RAG pattern was described as a way to add this context.
Sometimes, though, the context needs to be in the moment. When you are chatting with your friend chances are you are not taking notes, trying to remember every word that was said. The conversation becomes a lecture if you were to do this - which is not that much fun. The same goes for a chat with the LLM.
LangChain offers a special memory library where the application can save a chat’s history to a fast lookup store. The data is stored in a specific way, in a type of store that can offer very quick lookups. Typically is not a relational database. It’s usually a NoSQL or in-memory store.
Having the ability to quickly retrieve a chat’s history and inject it into the LLM’s prompt is a powerful way of creating very intelligent contextual applications.
How Does LangChain Work?
When you pay with a credit card for something, certain steps need to happen in a specific order. First, the card information needs to be gathered and secured. Then it needs to be transmitted to a processor. The processor makes sure the card account is valid and that the funds are available. The processor transfers the funds from your account to the merchant’s account. Finally, a confirmation of all this is transmitted back and you are given a receipt. Each of those steps must be followed in a specific order. You can’t withdraw the funds from an account with no money in it. The same goes for interacting with an LLM. You can’t send a prompt to the LLM with no context. You’re just doing an internet search at that point.
The “chain” in LangChain brings the idea of putting AI actions together in order, to create a processing pipeline. Each action, or chain, is a needed step in the pipeline to complete the overall goal. Thinking about the RAG pattern, it starts with the user submitting a question. An embedding is created from that text, a lookup is done on a vector database to gain more context about the question, then a prompt is created using both the original question and the context from the retrieval. The prompt is submitted to the LLM, which responds with an intelligent completion of the prompt.
All the steps in the RAG pattern need to happen in succession. If anything errors along the way, the processing should stop. LangChain offers the “chain” construct to attach steps together in a specific way with a specific configuration. All LangChain libraries follow this chain construct to make it very easy to move steps around and create powerful processing pipelines.
What are the Benefits of Using LangChain?
Using LangChain offers several benefits in the realm of natural language processing.
Enhanced Language Understanding and Generation
LangChain's integration of various language models and tools allows for more sophisticated language processing. This leads to better understanding and generation of human-like language, especially in complex tasks.
Customization and Flexibility
The modular structure of LangChain offers significant customization options. This adaptability makes it suitable for a wide range of applications, allowing users to tailor language processing solutions to specific needs.
Streamlined Development Process
LangChain's framework simplifies the development of language processing systems. By chaining different components together, it reduces complexity and accelerates the creation of advanced applications.
Improved Efficiency and Accuracy
The use of LangChain in language tasks enhances both efficiency and accuracy. The framework's ability to combine multiple language processing components leads to quicker and more accurate outcomes.
Versatility Across Sectors
LangChain's adaptability makes it valuable across various sectors, including content creation, customer service, and data analytics. Its ability to handle diverse language tasks makes it a versatile tool in the AI toolkit.
Examples of LangChain Applications
LangChain provides a lot of power by providing a framework that can be used to build generative AI applications. There are a number of different types of genAI applications where LangChain has been purpose built to facilitate.
Retrieval-Augmented Generation (RAG)
LangChain offers a few different scenarios that implement the RAG pattern. There is a simple question/answer example that is a classic use of adding context to a prompt. There is also the RAG over code example that aids developers while writing code. The Chat History example creates a very intelligent chat experience with the LLM. Visit LangChain’s use cases area for more.
Chatbots
Chatbots are the cornerstone of LLM interactions. LangChain offers a getting-started example, to help you create an AI Application in just a few minutes.
Synthetic Data Generation
While developing applications, an engineer writes tests to ensure all their functions are working as expected. These are referred to as unit tests. There are also load tests a developer does to ensure the application can handle the load it will see in production. To run either of these tests you need data. Sometimes lots of data. LangChain’s Synthetic data generation example uses an LLM to artificially generate data. A developer could then use that data to test their application.
Interacting with a Database Using Natural Language
Writing SQL queries is not as much fun as it sounds. As one writes a query, they are taking a real-world question and transforming it into SQL syntax. A simple question like “How many chunks can a woodchuck chuck” would be transformed into “select count(chunk) from chunks where animal like ‘woodchuck’”. LangChain’s SQL example uses an LLM to transform a natural language question into a SQL dialect.
Getting Started with LangChain
Whether you have an existing Python app that needs to be taught new AI tricks or you’re starting from scratch, you’ll want to add the LangChain library to the requirements.
- 1
- 2
- 3
pip install langchain # conda install langchain -c conda-forge
Assuming that you plan to interact with an LLM, the next step would be to install its supporting library. View the full list of LLMs here.
- 1
pip install openai
With that, the fun begins! You could create a PromptTemplate + LLM + OutputParser or you could create a simple Prompt template application. Read more about interaction with models, data retrieval, chains, and memory in LangChain documentation.
Discover How Datastax and Langchain Work Better Together
DataStax provides the real-time vector data and RAG capabilities that Gen AI apps need, with seamless integration with developers’ stacks of choice (RAG, Langchain, LlamaIndex, OpenAI, GCP, AWS, Azure, etc).
To get started with LangChain and to see how DataStax and LangChain are better together check out our recent blog post on Build LLM-Powered Applications Faster with LangChain Templates and Astra DB
Also, you can find more information on how to set up and deploy Astra DB on one of the world’s highest performing vector stores, built on Apache Cassandra, which is designed for handling massive volumes of data at scale.


