Balancing Your Cassandra Cluster

Nick Bailey

One of Cassandra's many strong points is its approach to keeping architecture simple. It is extremely simple to get a multi node cassandra cluster up and running. While this initial simplicity is great, your cassandra cluster will still require some ongoing maintenance throughout the life of your cluster.
The aspect of that maintenance covered by this blog post will be token management. There are two main aspects of token management in Cassandra. The first and somewhat more straightforward aspect, is the initial token selection for the nodes in your cluster. The second aspect being the maintenance of nodes and tokens in your production cluster in order to keep your cluster balanced (and consequently keep your Ops team happy). Addressing this second task was one of the things we at DataStax wanted to help address with OpsCenter, our management tool for Cassandra. In this post we'll cover the steps and considerations involved in balancing a Cassandra cluster. The first few parts of this post may be elementary for experienced Cassandra users, they can feel free to jump ahead.
A Note on Consistent Hashing
The core of Cassandra's peer to peer architecture is built on the idea of consistent hashing. This is where the concept of tokens comes from. The basic concept from consistent hashing for our purposes is that each node in the cluster is assigned a token that determines what data in the cluster it is responsible for. The tokens assigned to your nodes need to be distributed throughout the entire possible range of tokens. As a simplistic example, if the range of possible tokens was 0-80 and you had four nodes, you would want the tokens for your nodes to be: 0, 20, 40, 60.
For further in depth explanation of consistent hashing, refer to the wikipedia article on the subject. The specifics of data distribution in Cassandra are also slightly more complex than described above. For further explanation, the DataStax documentation on the subject is very helpful.
Initial Token Selection
The easiest time to ensure your cluster is balanced is during the intial setup of that cluster. Changing tokens once a cluster is running is a heavy operation that involves replicating data between nodes in the cluster. Once again, the DataStax documentation explains this subject in depth, so we won't cover the exact details here.
Inevitably though, you are going to want to add (or even remove) nodes from your cluster. This is where the balancing process comes into play.
Balancing a Live Cluster
So at some point you will need to rebalance the tokens in your cluster. Here, we'll go through the steps OpsCenter follows when balancing the cluster, but the concepts are applicable using OpsCenter, another tool, or a manual process. Before we start it is worth nothing the multi-datacenter capabilities that Cassandra provides. In terms of balancing a cluster, each datacenter within the cluster can be considered a separate ring, and balanced individually. We will walk through the steps necessary for balancing a single datacenter, but the process for balancing a multi-datacenter cluster simply requires repeating these steps for each datacenter that exists.
Determining the new tokens
The first step in the process is to determine what the tokens in your cluster should be. At first glance this step may seem straightforward. Using the example above, if I have a token range of 80 and 4 nodes, my tokens should be: 0, 20, 40, 60. Actually though, this is just one set of possible tokens that are valid. It is really the distribution of the tokens that matters in this case. For example, the tokens 10, 30, 50, 70 will also provide a balanced cluster.
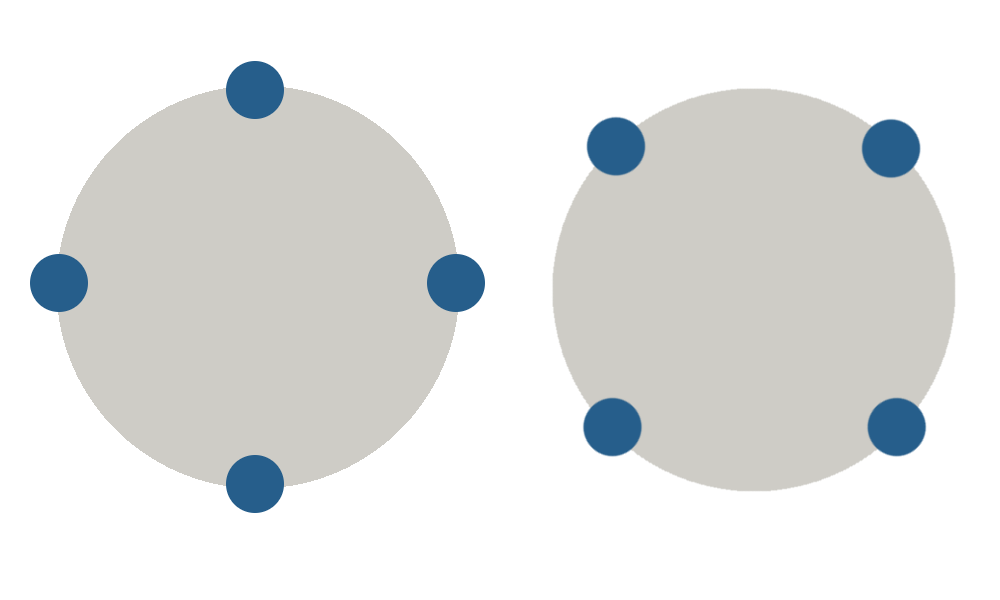
- Two balanced Cassandra clusters.
Optimizing for the smallest number of moves
So, in the case of balancing a live cluster, you want to find the optimal set of tokens taking into consideration the tokens that already exist in your cluster. This allows you to minimize the number of moves you need to do in order to balance the cluster. The process actually involves examining each token in the ring to see if it is 'balanced' with any other tokens in the ring.

- An unbalanced cluster, with two possible ways to balance the cluster.
In the above example we can see that we have an unbalanced cluster. When balancing the cluster, we want to minimize the number of tokens that we need to change. In this case, while you can see it is possible to balance the cluster by changing 3 tokens and leaving one, but the optimal way is to only change two of our tokens.
Optimizing for the smallest amount of data transferred
After narrowing down the possible sets of new tokens for you cluster, it is possible that there may be multiple sets of tokens that can balance a cluster and require the same number of moves. In this case we want to further narrow down our options by picking the set of tokens that requires the last amount of data transfer in our cluster. That is, the set of tokens that require the shortest total distance to move.
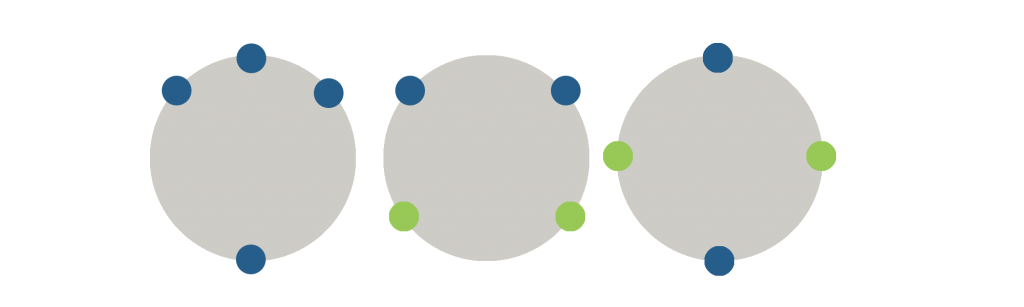
In this example, there are two ways to balance the cluster, both of which will require changing two of our tokens. The first example will require moving a node from token 0 to token 30, and a node from token 40 to token 50. The total distance moved in this case will be 40. In the last image we see that we can also balance the cluster by moving token 10 to token 20, and token 70 to token 60. the total distance moved in this case is 20, so this is the better approach.
A note when dealing with multiple racks
In order to achieve the best fault tolerance, it can be a good idea to distribute your data across multiple racks in a single datacenter. To achieve this in Cassandra, you alternate racks when assigning tokens to your nodes. So token 0 is assigned to rack A, token 1 to rack B, token 2 to rack A, token 3 to rack B, etc. It is necessary to take this into account in the above two steps if you are dealing with a rack aware cluster.
Moving the nodes
At this point, we've determined the optimal set of new tokens, and the nodes in our cluster that need to move to these tokens. The rest of the process is fairly simple, but involves some additional Cassandra operations besides just the command to move tokens. Each move is done synchronously in the cluster. The first step is to initiate the move using the JMX method exposed by Cassandra. If you were doing this manually you would use the nodetool utility provided by Cassandra, which has a 'move' command. The move operation will involve transferring data between nodes in the cluster, but it does not automatically clean up data that nodes are no longer responsible for. After each move, we also need to tell Cassandra to cleanup the old data nodes are no longer responsible for. We need to cleanup the node that has just moved, as well as any nodes in the cluster that have changed responsibility. Internally OpsCenter determines these nodes by comparing the ranges each node was responsible for before the move, with the ranges each node is responsible for after the move.
This process of move followed by cleanup is repeated until we've filled all the necessary tokens for balancing the cluster, at which point we are done. All the steps we've outlined so far are done automatically once you initiate a rebalance through the OpsCenter UI. The button for initiating a rebalance can be found in any of the three cluster views OpsCenter presents.
Rebalance button in OpsCenter
Once you choose to start a rebalance, OpsCenter will display a preview window outlining the moves that OpsCenter will make to balance the cluster. Additionally it will let you visually see the state of the ring currently and after the rebalance completes.
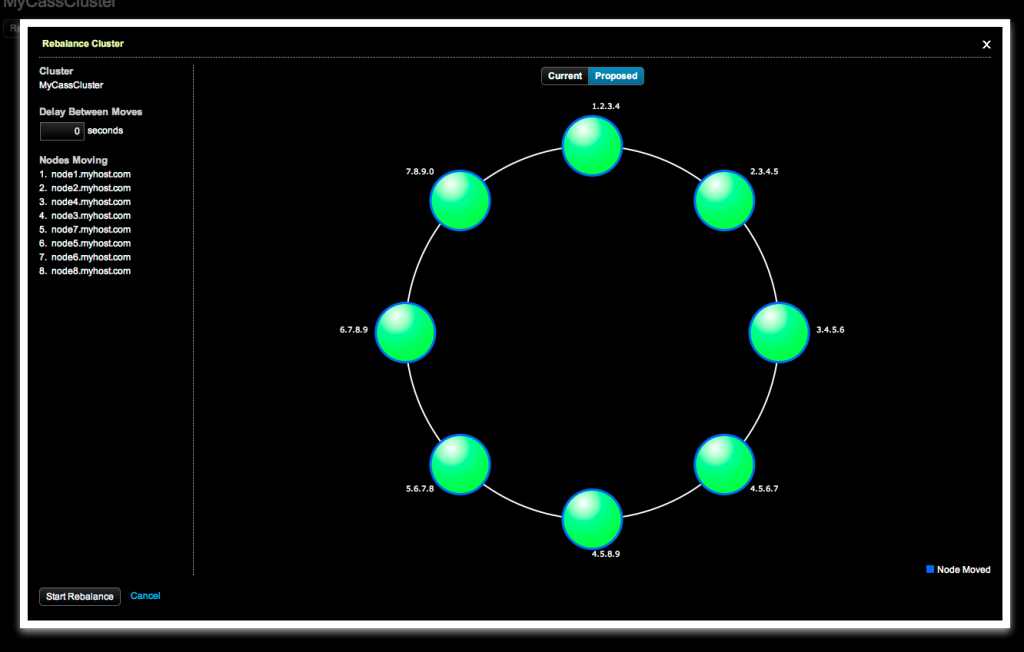
OpsCenter rebalance preview window
Final Notes
That outlines the considerations involved with balancing a live Cassandra cluster. The task can seem somewhat daunting at first, but luckily tools like OpsCenter exist to help automate some of the steps involved. Even if you are using an external tool to help automate a process like this, knowing what is going on underneath the hood can help provide general insight into your cluster and how it works. Hopefully you found this post useful even if you don't currently have any issues with balancing your Cassandra cluster.
More Technology
View All
Introducing the DataStax AI Terraform Module


