How to Build an Image Search App with Astra DB and CLIP Models

Aaron PloetzDeveloper Relations

The recent boom of generative AI (GenAI) has already changed the way many applications are built. The probability of a user getting what they want by having a conversational interaction with a system or application has never been higher. Let’s take a look at using GenAI to help us shop for a car.
Of course, shopping for a car online is nothing new. If you (as a buyer) know what you want, finding it is as easy as specifying a make and model, or searching on other specific parameters. But with the recent advances in GenAI, we can now shop for cars using a natural language interface against a corpus that’s solely built with image data.
We’ll demonstrate this by building a car shopping web application in Python. It’ll be backed by the DataStax Astra DB vector database, which enables the application to do the following:
- Leverage the Contrastive Language Image Pretraining (CLIP) model.
- Create and store vector embeddings of images.
- Create vectors of the provided search criteria at runtime.
- Use vector search to show an image of the car which most-closely matches the searched vector.
What is CLIP?
CLIP is short for “Contrastive Language Image Pretraining.” It is a sentence transformer which was originally built by OpenAI. The CLIP model is pre-trained with both images and their text descriptions.
When encoded as vector embeddings, the images and text exist in the same, shared vector space. This allows us to return results based on approximations of either image or text input.
Requirements
Before building our application, we will need to create and install a few things. First of all, we should make sure that our local Python installation is at least on version 3.9. We can verify this from a terminal session:
python --version Python 3.9.6
Next, we'll need the following Python libraries:
- AstraPy: Helps us connect to and execute vector search operations on Astra DB.
- Flask and Flask-WTF: For building our web front-end.
- Sentence Transformers: Library for working with certain kinds of large language models (LLMs), including CLIP.
Fortunately, we can easily install all of these libraries by leveraging the requirements.txt file found in this project’s Git repository:
pip install -r requirements.txt
Our project will also need the following directory structure, with carImageSearch as the “root” of the project:
carImageSearch/
templates/
static/
css/
images/
input_images/
web_images/Loading image data
The first step is getting the data into the vector database. First, sign up for a free Astra DB vector database account and create a new vector database. Be sure to do that before proceeding to the Python code in the next step.
carImageLoader.py
Let’s build a specific Python data loader, named carImageLoader.py. Before getting into the code, we will define environment variables for our Astra DB token and endpoints. Once we have created our Astra DB account and a new vector database, we can copy our token and API endpoint to define them in a terminal session:
export ASTRA_DB_APP_TOKEN=
AstraCS:abcdefNOTREALghijk:lmnopqrsBLAHBLAHBLAHtuvwxyz
export ASTRA_DB_API_ENDPOINT=
https://b9aff773-also-not-real.apps.astra.datastax.comThen from within our data loader code, we can use the AstraPy library to open a connection to our Astra DB instance.
ASTRA_DB_APPLICATION_TOKEN =
os.environ.get("ASTRA_DB_APPLICATION_TOKEN")
ASTRA_DB_API_ENDPOINT= os.environ.get("ASTRA_DB_API_ENDPOINT")
db = AstraDB(
token=ASTRA_DB_APPLICATION_TOKEN,
api_endpoint=ASTRA_DB_API_ENDPOINT,
)We can then create a new collection named “car_images.” As the CLIP model works with 512-dimensional vectors, we will need to make sure that our collection is configured to use the same size dimensions. While the metric for vector comparison allows for dot-product and Euclidean-based indexes, the default cosine-based index will work just fine:
col = db.create_collection("car_images", dimension=512,
metric="cosine")Next, we will initialize our model to be the clip-ViT-B-32 sentence transformer:
model = SentenceTransformer('clip-ViT-B-32')For the images, we’ll create a local directory called “static,” and inside that another directory called “images.” Now we can copy images of cars into the static/images/ directory. Images for this dataset are available in the Git repository mentioned at the end of the article; most of those images are from Car Images Dataset on Kaggle.
Note: The “static” directory is used by the Flask web framework to work with local files.
With all of the preliminary setup complete, we can now iterate through all files in the (local) static/images/ directory. One-by-one we will encode it to create a vector embedding, and store it in our “car_images” collection in Astra DB:
IMAGE_DIR = "static/images/"
for id, imageName in enumerate(os.listdir(IMAGE_DIR)):
img_emb = model.encode(Image.open(IMAGE_DIR + imageName))
strJson = '{"_id":"' + str(id) + '","text":"' + imageName +
'","$vector":' + str(img_emb.tolist()) + '}'
doc = json.loads(strJson)
col.insert_one(doc)Assuming that the car images are already present in the static/images/ directory, they can be loaded into Astra DB with the following command:
python carImageLoader.py
Building the application
Now that the data has been loaded, we can turn our attention to the main application. For this application, we’re going to use the model-view-controller (MVC) pattern. The MVC pattern helps us keep our code functionally separated, while also allowing us the flexibility to swap out a layer’s underlying libraries in the future, without impacting the overall application. Figure 1 shows a high-level view of the application architecture.
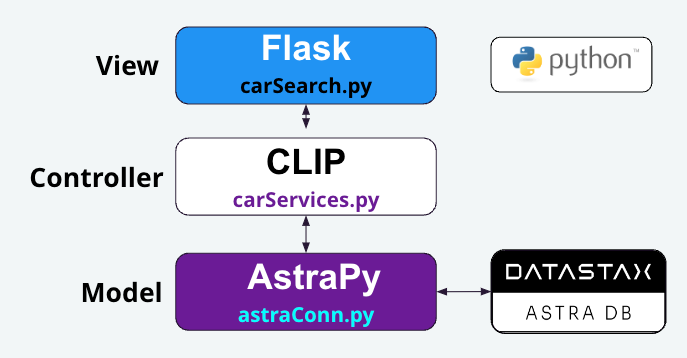
Figure 1 - A high-level view of the Car Search application, demonstrating the layers of the MVC pattern.
carSearch.py
We will stand-up a simple web interface using the Flask library to act as our “view.” That interface will have some simple components, including a search form that will call services defined in the “controller” layer.
Note: As web front-end development is not the focus, we’ll skip the implementation details. For those who are interested, the code can be accessed in the project repository listed at the end of the article.
carServices.py
The service layer of this application will contain two very similar methods:
- get_car_by_text
- get_car_by_image
Both of these methods will use the clip-ViT-B-32 sentence transformer to generate a vector embedding for the search criteria. That embedding is then passed to the “model” layer and used in a vector search. This can be seen in code for the get_car_by_text method below:
async def get_car_by_text(search_text):
global model
if model is None:
model = SentenceTransformer('clip-ViT-B-32')
# generate embedding from search_text
text_emb = model.encode(search_text)
# execute vector search
results = await get_by_vector(COLLECTION_NAME,text_emb,1)
# should only be one result returned
return IMAGE_DIR + results[0]["text"]It’s important to note the following:
- Both
get_car_by_textandget_car_by_imageare defined to be asynchronous. - The result of this method is an image filename. This filename is then returned to the “view” layer where it is loaded from disk.
- The
get_car_by_imagemethod really only differs from the get_car_by_text method by the fact that the filename passed from the “view” layer is opened. This enables a vector embedding to be generated for the image provided.
astraConn.py
The astraConn.py file represents the “model” layer of the application, and it is primarily responsible for connecting to and interacting with the Astra DB vector database. It contains one method named get_by_vector and its code is shown below:
async def get_by_vector(table_name, vector_embedding, limit=1):
global db
global collection
if collection is None:
db = AstraDB(
token=ASTRA_DB_APPLICATION_TOKEN,
api_endpoint=ASTRA_DB_API_ENDPOINT,
)
collection = db.collection(table_name)
results = collection.vector_find(vector_embedding.tolist(),
limit=limit, fields={"text","$vector"})
return resultsAside from maintaining the connection to Astra DB, the main part of this method is in how it uses AstraPy’s vector_find method on the collection object. As this method only works with vectorized data, it can be used by both the get_car_by_text and get_car_by_image methods from the “controller” layer.
Deployment
For deployment, we decided to use web hosting at PythonAnywhere. Like many web hosting sites, PythonAnywhere has instructions for deploying applications which use the Web Server Gateway Interface (WSGI) specification. As Python applications built using Flask are WSGI compatible, deployment was simply a matter of uploading the source code and images, and then updating the WSGI configuration file.
Note: If you want to see the application in-action, you can find it at the following link: https://aploetz68.pythonanywhere.com/
Demo
Let’s see this in action. First, we will run the application:
flask run -p 8000
If it starts correctly, Flask should display the address and port that it is bound to:
* Serving Flask app 'carSearch' * Debug mode: off WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Running on http://127.0.0.1:8000 Press CTRL+C to quit
If we navigate to that address in a browser, we should be presented with a simple web page and search interface. In the search box, we can simply type “red tesla” and we should see something similar to figure 2.
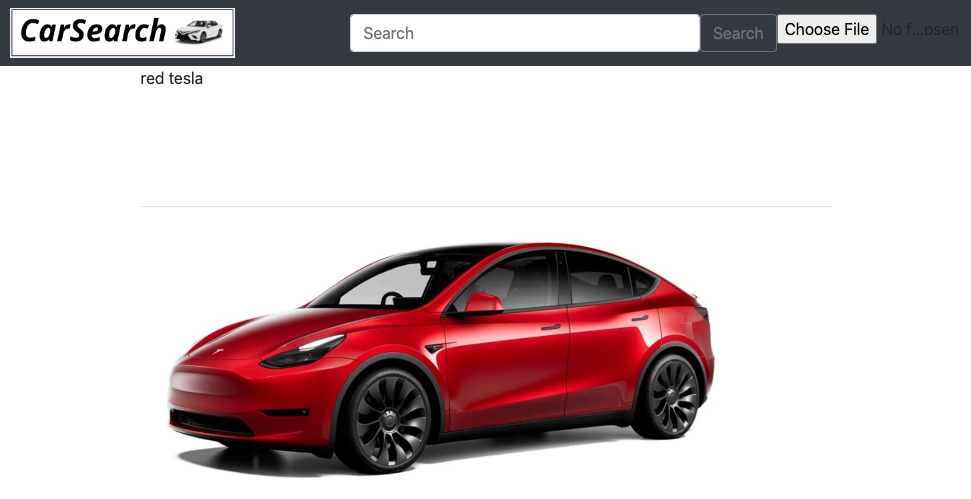
Figure 2 - A simple, text-based search for a “red tesla.”
Of course, we can also search with an image, too. For example, maybe I like the car that I drive and just want something similar? I could take a picture of it (Figure 3), and use it to search with. To do that in our web interface, we would just need to click on the “Choose File” button, and then select the picture of our car.

Figure 3 - In retrospect, buying an 8-foot ladder (without my wife’s SUV) was not a wise decision.
Once the search is initiated, our application quickly processes and loads a thumbnail of our image. When the vector search operation completes, it should show the closest match to our image, given all of the vectorized images stored in the database (Figure 4).
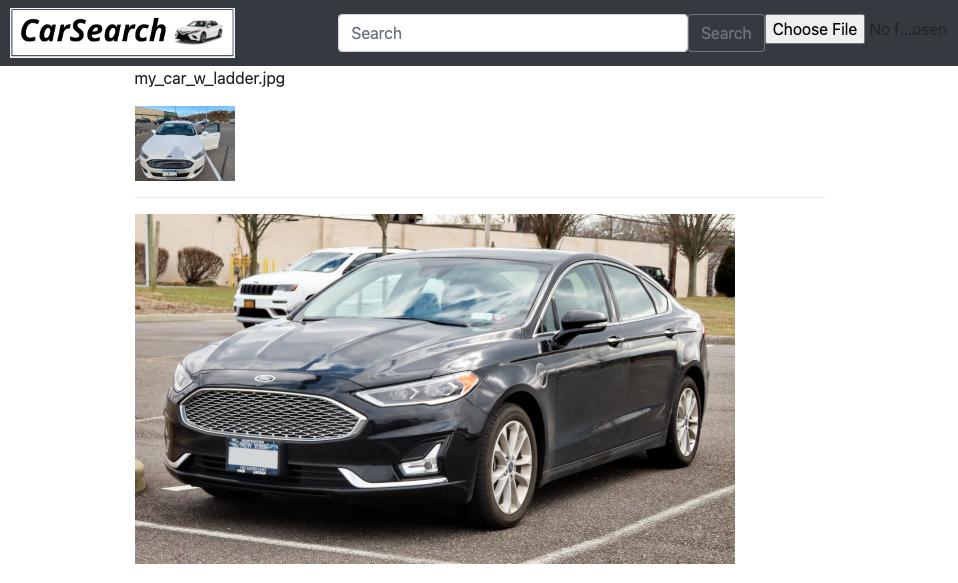
Figure 4 - Searching with an image of a car matches with a car of the same model!
As shown in Figure 4, searching with an image of my personal Ford Fusion does indeed match-up with a picture of the same make and model. This is also despite the fact that the image we used to search with was taken from a slightly different angle, and has some other factors (ladder sticking out the window, open door, etc) which had the potential to cause matching issues for the vector search.
Points to remember
- The CLIP sentence transformer model gives us the flexibility to search by text or by image.
- The MVC pattern was used here to illustrate the proper separation of code functionality. No matter which language is being used, LLM models should never be instantiated in the “view” layer.
- As with many distributed databases, connection objects for Astra DB should be defined once and used for the entire lifecycle of the application.
- All methods in both carServices.py and astraConn.py were defined to be asynchronous. It is important not to mix synchronous and asynchronous methods. Once a method is defined to be asynchronous, all of the methods called from it should be asynchronous as well.
- The vector embeddings are generated using the (pretrained)
clip-ViT-B-32model. For more information, have a look at its model card on HuggingFace: https://huggingface.co/sentence-transformers/clip-ViT-B-32 - The complete code for this project can be found in the following Github repository: https://github.com/aar0np/carImageSearch
Conclusion
We’ve demonstrated how to leverage the CLIP sentence transformer model to store and search for images with Astra DB. We showed how the image data was loaded, and how the vector embeddings were created and stored. Next, we walked through each layer of our Python MVC application, showing how to produce results with some simple searching. The most interesting part of course, is the ability to use the CLIP model’s embeddings to search by text or by image.
Searching by image has some profound implications. Think about this: How much more relevant could our search results be if we didn’t need to rely on the user to accurately describe what they want? Using an image as search input transcends spoken language, and can lead us to interact in ways that we haven’t thought of. In this example, our users can simply use a picture from their phone and let Astra DB’s vector search handle the rest.
We are just beginning to explore the use cases for GenAI. As shown here, many industries could benefit from it today; even from something as simple as exploring new ways to search images. As the future unfolds, we will certainly see GenAI applied in new and exciting ways. Backing this new paradigm of applications with a powerful vector database like Astra DB will help to ensure that they’ll be able to withstand the demands of the present, while also being able to grow with the future.
Note: If you want to see this application in-action, you can find it hosted here on PythonAnywhere: https://aploetz68.pythonanywhere.com/
More Technology
View All
Introducing the DataStax AI Terraform Module


