


What is Langflow used for?
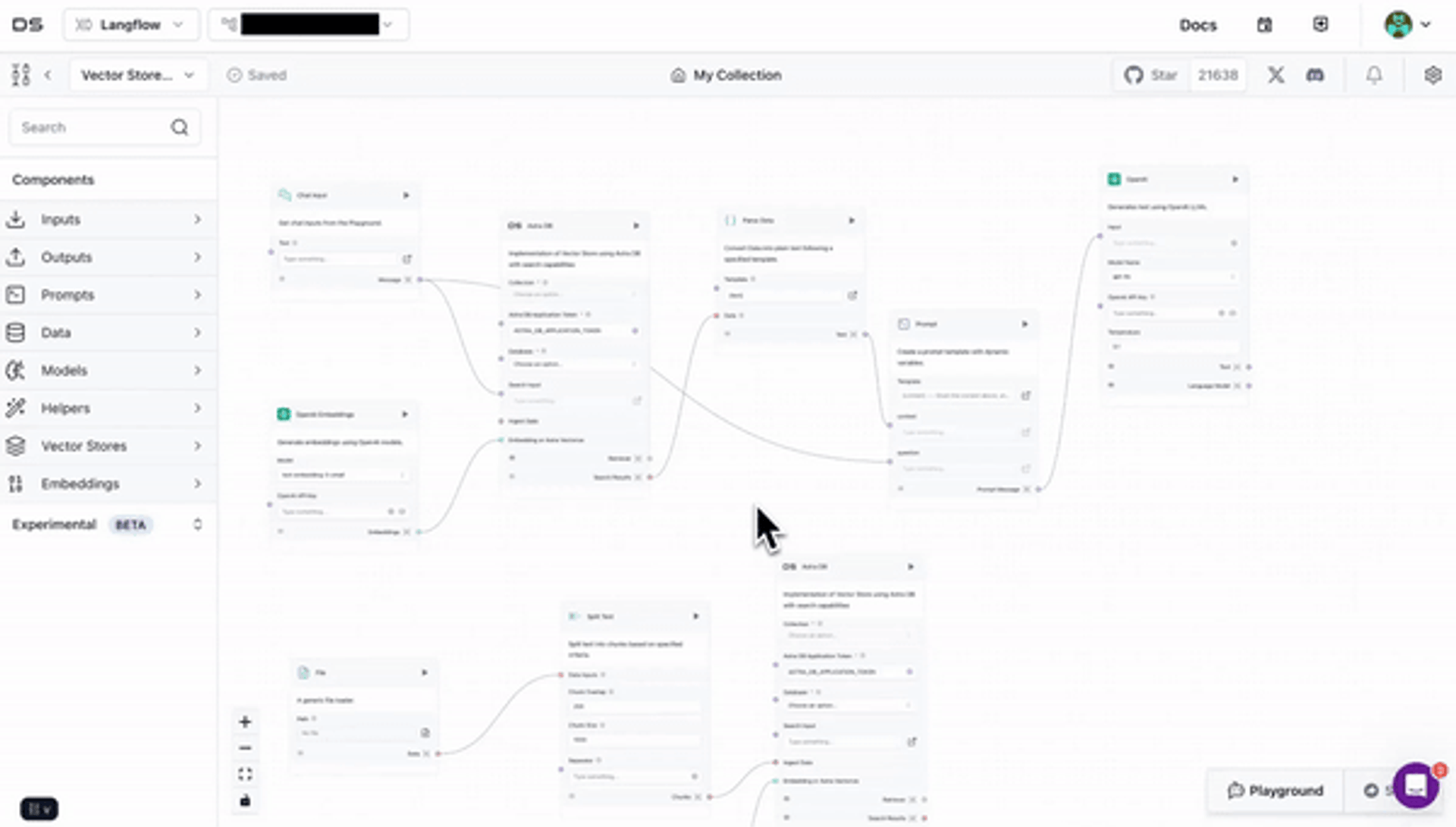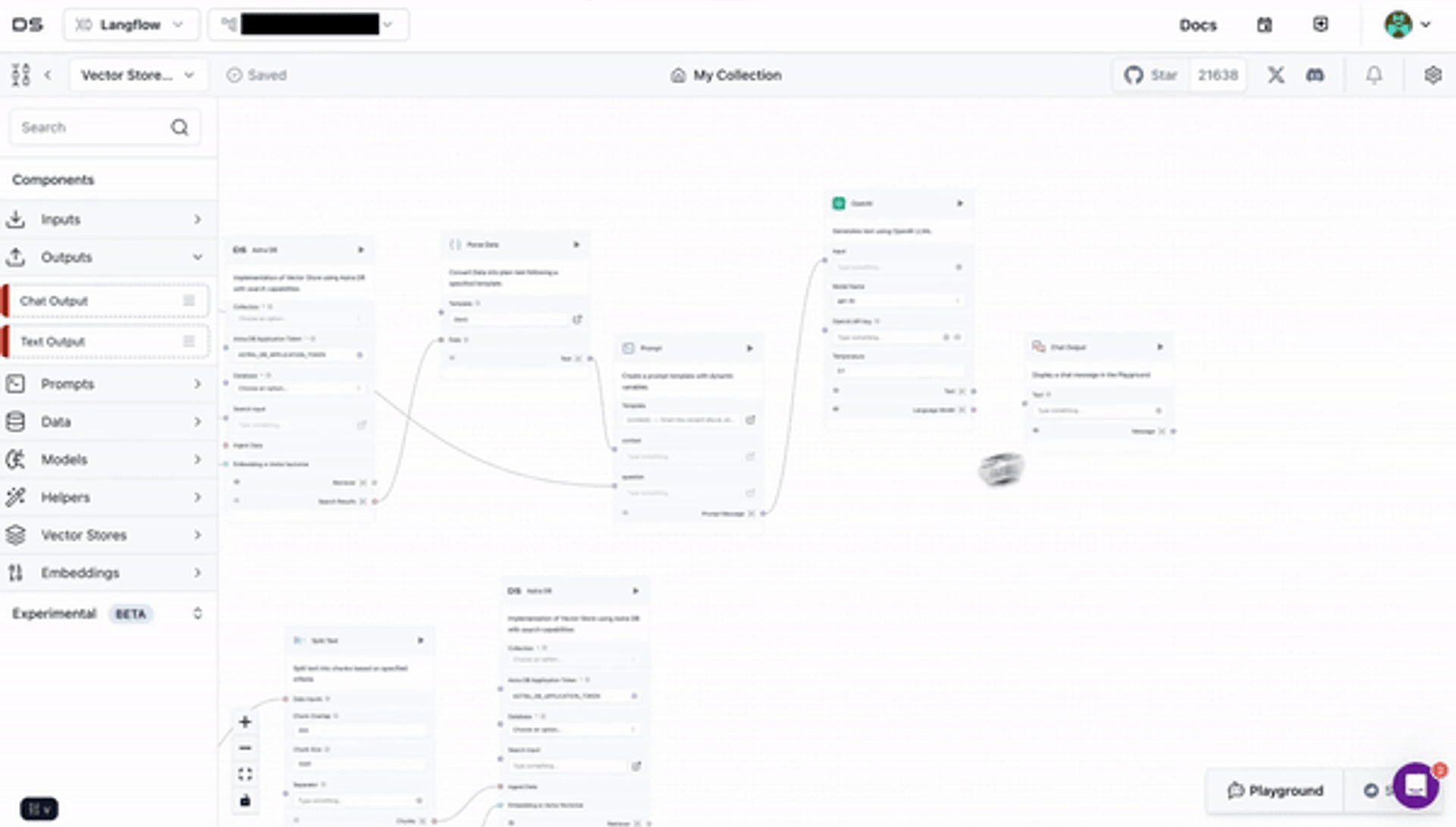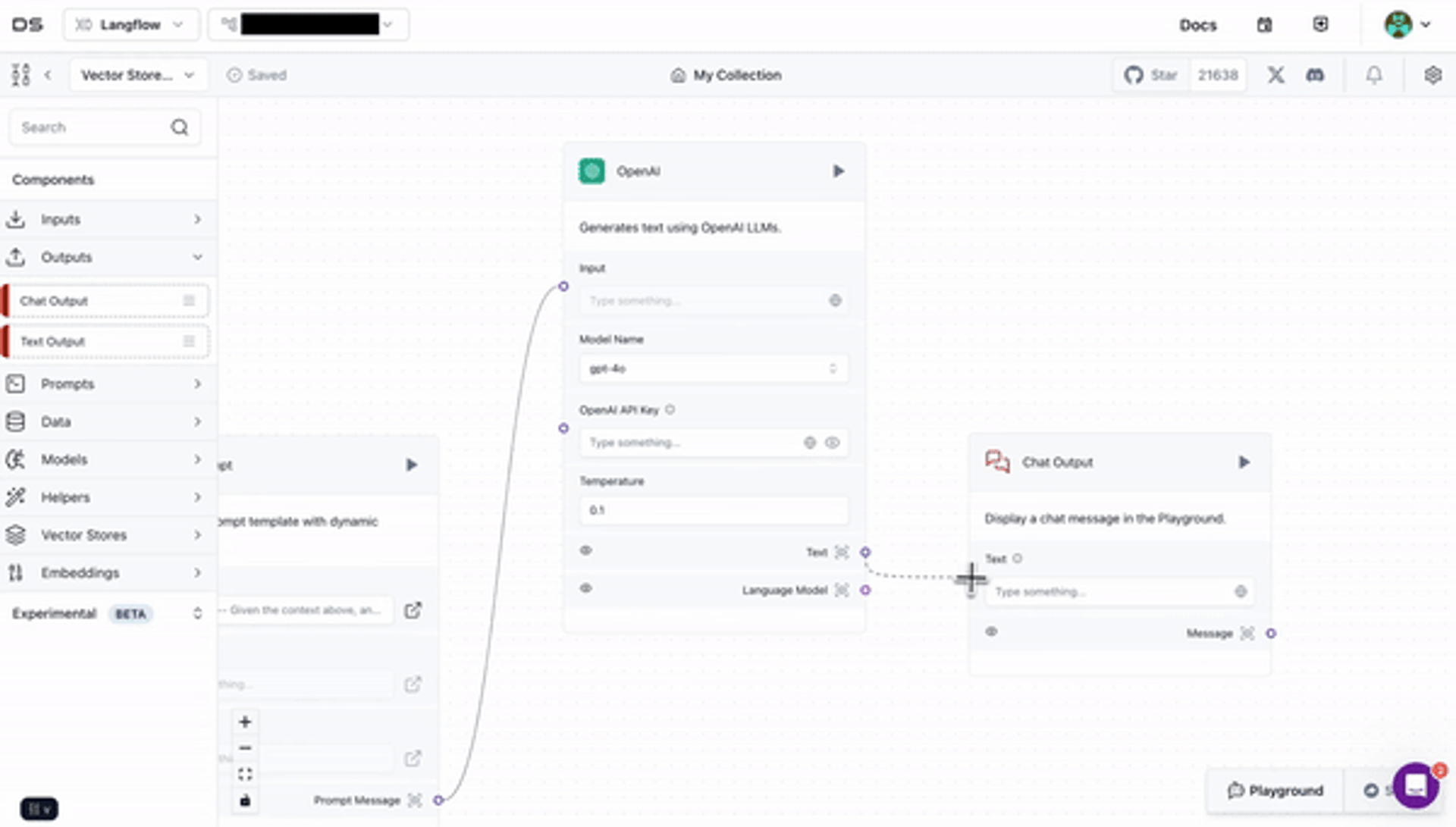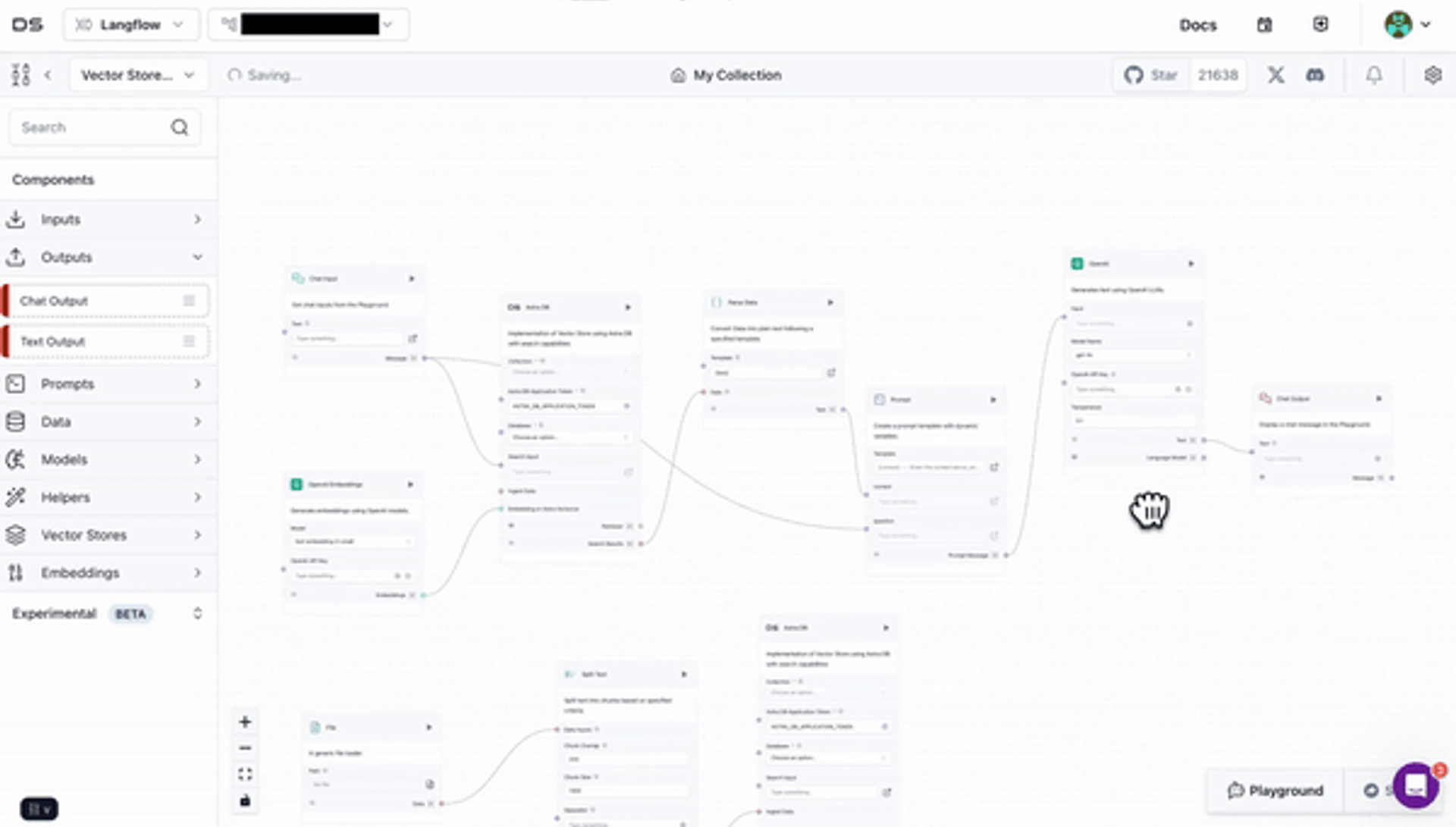
Langflow simplifies app development of RAG (retrieval-augmented generation) and multi-agent AI pipelines and apps. Langflow is a visual no-code/low-code builder with prebuilt components to connect to any data source, vector database (from Astra DB to MongoDB or Pinecone) or API.