DataStax Python Driver: A Multiprocessing Example for Improved Bulk Data Throughput

Adam Holmberg

One question we get a lot from application integrators is "how to make it faster". In languages such as C++ and Java, this is often a matter of using asynchronous request execution, and tuning IO threads to maximally utilize the platform (e.g. multiple cores). Most DataStax drivers have utility functions for efficiently making concurrent asynchronous requests, and the Python driver is no exception. This works well for workloads that are IO bound. However, applications working with large datasets quickly become CPU bound as (de-)serialization dominates. Unfortunately a Python process is mostly relegated to a single effective CPU due to the Global Interpreter Lock (GIL). The Python threading documentation explains:

While Python might not be the best choice for bulk-processing workloads, its ease-of-use and raft of scientific processing libraries still make it attractive for experimentation and analysis with large datasets. The demand is there -- so how can we make this faster using the driver?
There is work to be done in making single-thread processing more efficient overall, to squeeze the most possible out of a single interpreter. In lieu of that, the most direct way to escape this limitation is to use the multiprocessing package from the Python standard library. This module provides simple, yet powerful abstractions over process management and inter-process communication (IPC), allowing applications to easily spawn multiple Python instances and marshal data between them.
In this post I use a small example workload to show how to use multiprocessing with the DataStax Python Driver to achieve higher throughput using multiple CPUs. The code referenced in this article is available in complete, self-contained examples in a repo here. The test setup uses a single node Cassandra cluster, running on the same host as the clients. Throughput figures cited here are only for illustration of limitations, and discussion of relative performance.
Single Process Baseline
To introduce the problem, let's start with a standard, single-process implementation of a contrived workload. We'll have a class that will manage my cluster and session, and produce query results for a sequence of parameters, using a predefined statement. We'll query system.local to simplify setup, and because it has a variety of data for deserialization (and plenty -- it can be upwards of 6KB when using vnodes). The parameter stream for this workload will simply be a sequence of keys for the table (always 'local' in this case).
|
|
Running this workload against a single local node shows the problem at hand:

The Python interpreter is pegged near 100% (effectively one core), and the Cassandra java process is not pushed too hard. Meanwhile, other cores remain idle. As a baseline, this pattern takes over four seconds running 10,000 queries:
|
|
We should be able to make this faster putting more cores to work.
Multi-processing Single Queries
The muliprocessing package makes it easy to distribute work among multiple processes, using the concept of a Pool. We can easily take advantage of this by updating our QueryManager to spawn a pool, and distribute request processing.
|
|
The pool allows us to specify an initializer, which is run in each subprocess after it has spawned. Note that the session is setup here, after forking to ensure that the event loop thread is initialized properly (internal threads do not survive the fork, and the cluster object is not designed to reinitialize in this case). Each subprocess has its own Session instance. In get_results we're simply mapping each request to the pool, and returning the results. The package handles marshaling parameters and assembling results from processes in the right order. Note that the form of input parameters and output results are the same here, as in the single process version.
In comparison to the baseline:
|
|
Running this for the same iterations shows better than 2x improvement in speed. Not bad for just a few lines of code. In this case we're actually bumping up against the CPU capacity of this single machine, so this rate is limited by the local setup. Looking at the CPU utilization shows some load spread among multiple Python runtimes, and the server being pushed harder:
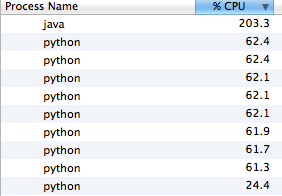
But what if we don't want to devote *all* of a host to this task? The package allows you to configure how many subprocess are started as part of the pool. Left unspecified, it defaults to the number of cores on the machine. Instead, we can specify a lower number to contain the CPU. Doing this with the present design results in lower load, but also diminished throughput:
|
|
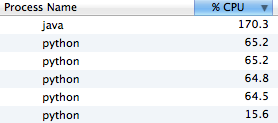
We can see that the worker processes are not fully utilized, which means this design is not as efficient as it could be in terms of requests per process overhead. To rectify this, we will introduce batching and make use of concurrent execution inside the pool.
Multi-processing Concurrent Queries
In the previous section we achieved improved throughput by simply mapping input parameters to single request executors. However, this simple approach did not result in full interpreter utilization, and thus requires more overhead for a given throughput. With only a few more tweaks, we can transform our work to take advantage of concurrent execution within each subprocess.
|
|
In the interest of comparison to the other designs, we are still accepting the same form of input, and producing the same list of results. In reality, an application would decide on an execution model, and likely process results in-place rather than doing this unnecessary transformation.
Now, we're taking input parameters and batching them into work units of 100 requests. These batches are executed concurrently in the subprocess, and the results are chained back into a single list. Running this script shows the worker processes better utilized, and even a better absolute throughput when compared to the previous design given more workers.
|
|
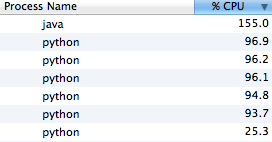
Here again, the single-host setup is limiting, but the point is made.
Where to draw the line
The multiprocessing package makes it so easy to build on pooled processes, perhaps the most interesting part of constructing an application like this is deciding how to portion the work. In the examples above we had a known query and we simply marshalled parameters for that query. Another, more general design might pass various queries along with parameters.
Work units are not limited to request execution inputs, though. For example, a bulk loading task might accept filenames, which the subprocesses then divvy up and read to produce input. A query task might accept date ranges (or any type of ranges or discrete buckets) to query in parallel for further processing in the parent process.
Whatever the work breakdown, it's fairly straightforward to apply these patterns for a given bulk processing application.
Resource Usage
Multiprocessing is a convenient way of escaping the GIL and taking advantage of multiple CPU cores available on most modern hardware. Naturally, it's not free of trade-offs. Here are a few things to keep in mind when considering this pattern:
Session per Process
Each subprocess requires its own driver session for communication with the cluster. This needs to be setup in the initializer, after the pool has spawned.
This incurs some overhead in the form of memory and TCP connections. This is usually not an issue on most systems. However, depending on your deployment model, you may need to be cognizant of spawning many sessions concurrently. This can cause connection failures (backlog overflows), and load spikes on a cluster. To mitigate this, you may introduce setup throttling using synchronization primitives provided by multiprocessing.
Pool Overhead
This pattern is most suitable for bulk tasks in which the throughput increase outweighs the cost of initializing the pool. Consider having long-lived processes that can start the pool and amortize that cost over as much work as possible.
There is also some additional latency due to IPC between the parent and worker processes. This is minimized by finding the right work unit, and often inflating data on the worker side. Pooling may not be appropriate for latency sensitive applications, or those with small query loads.
Conclusion
It is common for Python applications using this driver to become CPU-bound doing (de-)serialization in the GIL. In this post we saw how easy it is to use a standard Python package, multiprocessing, to achieve higher concurrency and throughput via process pools. This pattern is easily applied to a variety of bulk-processing applications with only a few lines of code.
More Technology
View All
Introducing the DataStax AI Terraform Module


