DSE Advanced Replication in DSE 5.1

Imran Chaudhry

DSE Advanced Replication feature in DataStax Enterprise underwent a major refactoring between DSE 5.0 (“V1”) and DSE 5.1 (“V2”), radically overhauling its design and performance characteristics.
DSE Advanced Replication builds on the multi-datacenter support in Apache Cassandra® to facilitate scenarios where selective or "hub and spoke" replication is required. DSE Advanced Replication is specifically designed to tolerate sporadic connectivity that can occur in constrained environments, such as retail, oil-and-gas remote sites and cruise ships.
This blog post provides a broad overview of the main performance improvements and drills down into how we support CDC ingestion and deduplication to ensure efficient transmission of mutations.
Note: This blog post was written targeting DSE 5.1. Please refer to the DataStax documentation for your specific version of DSE if different.
Overview
Discussion of performance enhancements is split into three broad stages:
- Ingestion: Capturing the Cassandra mutations for an Advance Replication enabled table
- Queueing: Sorting and storing the ingested mutations in an appropriate message queue
- Replication: Replicating the ingested mutation to the desired destination(s).
Ingestion
In Advanced Replication v1 (included in DSE 5.0); capturing mutations for an Advanced Replication enabled table used Cassandra triggers. Inside the trigger we unbundled the mutation and extract the various partition updates and key fields for the mutation. By using the trigger in the ingestion transaction, we provided backpressure to ingestion and reduced throughput latency, as the mutations were processed in the ingestion cycle.
In Advanced Replication v2 (included in DSE 5.1), we replaced triggers with the Cassandra Change Data Capture (CDC) feature added in Cassandra version 3.8. CDC is an optional mechanism for extracting mutations from specific tables from the commitlog. This mutation extraction occurs outside the Ingestion transaction, so it adds negligible direct overhead to the ingestion cycle latency.
Post-processing the CDC logs requires CPU and memory. This process competes with DSE for resources, so decoupling of ingestion into DSE and ingestion into Advanced Replication allows us to support bursting for mutation ingestion.
The trigger in v1 was previously run on a single node in the source cluster. CDC is run on every node in the source cluster, which means that there are replication factor (RF) number of copies of each mutation. This change creates the need for deduplication which we’ll explain later on.
Queuing
In Advanced Replication v1, we stored the mutations in a blob of data within a vanilla DSE table, relying on DSE to manage the replication of the queue and maintain the data integrity. The issue was that this insertion was done within the ingestion cycle with a negative impact on ingestion latency, at a minimum doubling the ingestion time. This could increase the latency enough to create a query timeout, causing an exception for the whole Cassandra query.
In Advanced Replication v2 we offloaded the queue outside of DSE and used local files. So for each mutation, we have RF copies of it that mutation - due to capturing the mutations at the replica level via CDC versus at the coordinator level via triggers in v1 – on the same nodes as the mutation is stored for Cassandra. This change ensures data integrity and redundancy and provides RF copies of the mutation.
We have solved this CDC deduplication problem based on an intimate understanding of token ranges, gossip, and mutation structures to ensure that, on average, each mutation is only replicated once.The goal is to replicate all mutations at least once, and to try to minimize replicating a given mutation multiple times. This solution will be described later.
Replication
Previously in Advanced Replication v1, replication could be configured only to a single destination. This replication stream was fine for a use case which was a net of source clusters storing data and forwarding to a central hub destination, essentially 'edge-to-hub.'
In Advanced Replication v2 we added support for multiple destinations, where data could be replicated to multiple destinations for distribution or redundancy purposes. As part of this we added the ability to prioritize which destinations and channels (pairs of source table to destination table) are replicated first, and configure whether channel replication is LIFO or FIFO to ensure newest or oldest data is replicated first.
CDC Deduplication and its integration into the Message Queue to support replication
With the new implementation of the v2 mutation Queue, we have the situation where we have each mutation stored in Replication Factor number of queues, and the mutations on each Node are interleaved depending on which subset of token ranges are stored on that node.
There is no guarantee that the mutations are received on each node in the same order.
With the Advanced Replication v1 trigger implementation there was a single consolidated queue which made it significantly easier to replicate each mutation only once.
Deduplication
In order to minimize the number of times we process each mutation, we triage the mutations that extract from the CDC log in the following way:
- Separate the mutations into their distinct tables.
- Separate them into their distinct token ranges.
- Collect the mutations in time sliced buckets according to their mutation timestamp (which is the same for that mutation across all the replica nodes.)
Distinct Tables
Separating them into their distinct table represents the directory structure:

token Range configuration
Assume a three node cluster with a replication factor of 3.
For the sake of simplicity, this is the token-range structure on the nodes:

Primary, Secondary and Tertiary are an arbitrary but consistent way to prioritize the token Ranges on the node – and are based on the token Configuration of the keyspace – as we know that Cassandra has no concept of a primary, secondary or tertiary node.
However, it allows us to illustrate that we have three token ranges that we are dealing with in this example. If we have Virtual-Nodes, then naturally there will be more token-ranges, and a node can be ‘primary’ for multiple ranges.
Time slice separation
Assume the following example CDC files for a given table:
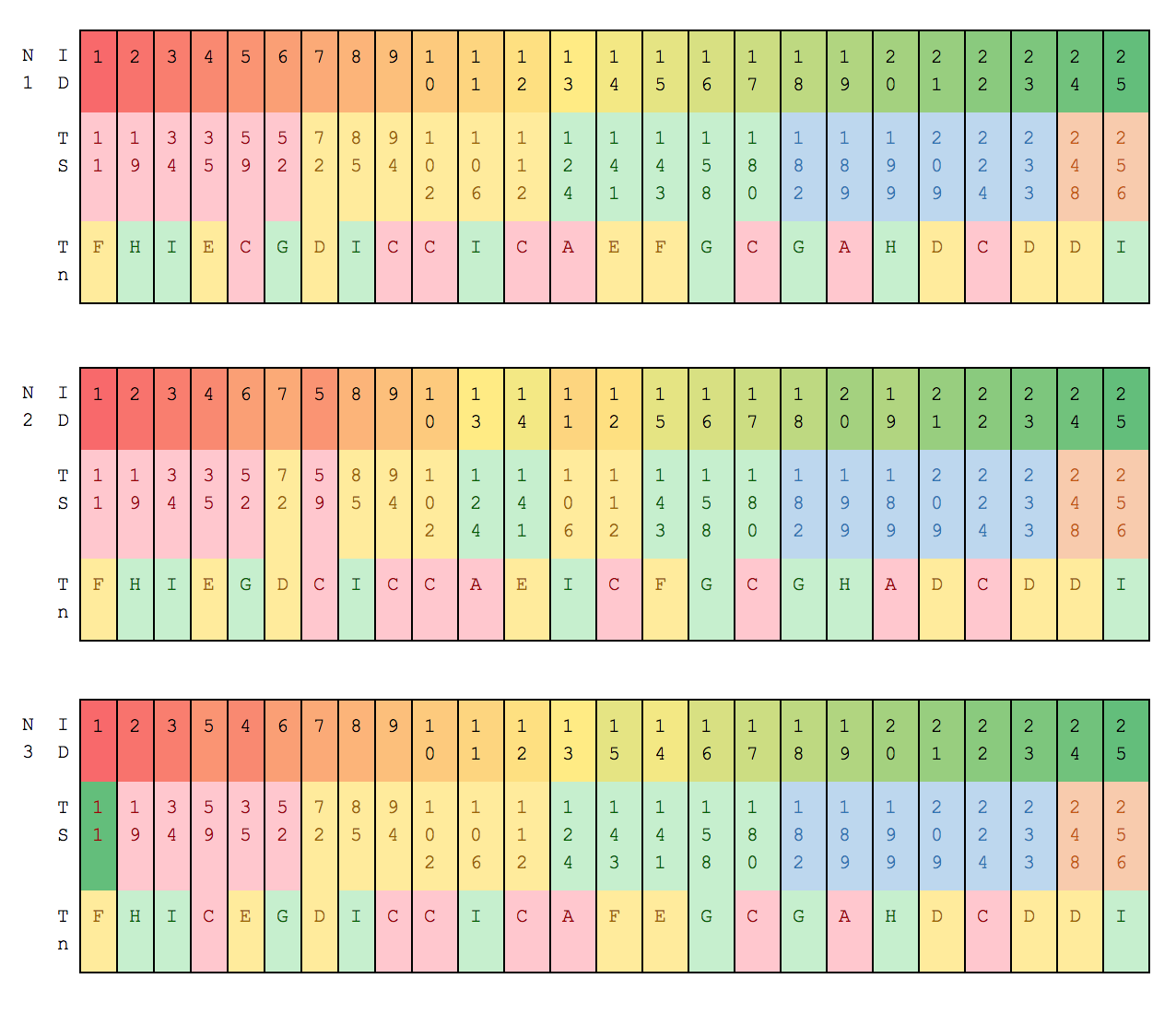
As we can see the mutation timestamps are NOT always received in order (look at the id numbers), but in this example we contain the same set of mutations.
In this case, all three nodes share the same token ranges, but if we had a 5 node cluster with a replication factor of 3, then the token range configuration would look like this, and the mutations on each node would differ:

Time slice buckets
As we process the mutations from the CDC file, we store them in time slice buckets of one minute’s worth of data. We also keep a stack of 5 time slices in memory at a time, which means that we can handle data up to 5 minutes out of order. Any data which is processed more than 5 minutes out of order would be put into the out of sequence file and treated as exceptional data which will be need to be replicated from all replica nodes.
Example CDC Time Window Ingestion
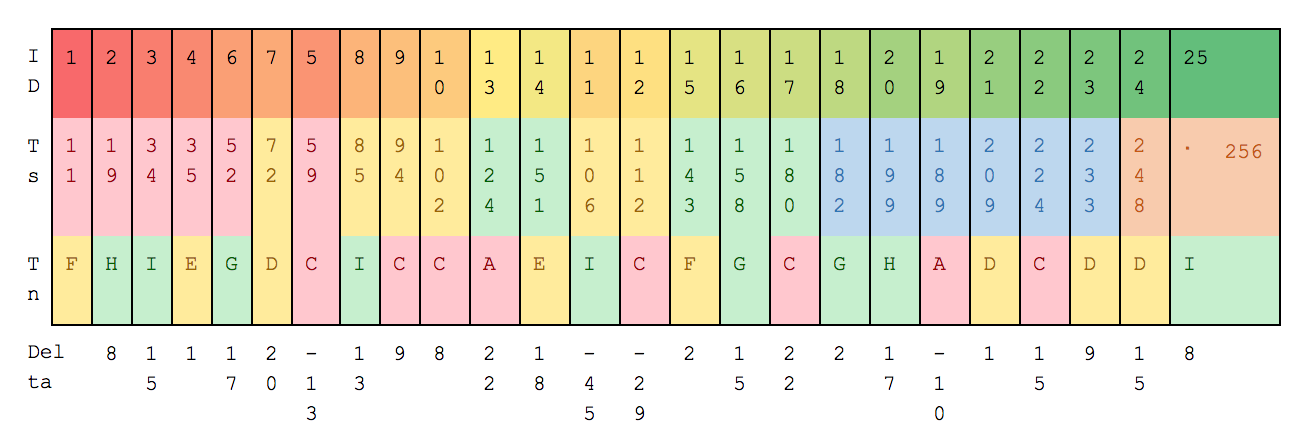
- In this example, assume that there are 2 time slices of 30 seconds
- Deltas which are positive are ascending in time so are acceptable.
- Id’s 5, 11 and 19 jump backwards in time.
- As the sliding time window is 30 seconds, Id’s 5, 12 & 19 would be processed, whilst ID 11 is a jump back of 45 seconds so would not be processed into the correct Time Slice but placed in the Out Of Sequence files.
Comparing Time slices
So we have a time slice of mutations on different replica nodes, they should be identical, but there is no guarantee that they are in the same order. But we need to be able to compare the time slices and treat them as identical regardless of order. So we take the CRC of each mutation, and when we have sealed (rotated it out of memory because the current mutation that we are ingesting is 5 minutes later than this time slice) the time slice , we sort the CRCs and take a CRC of all of the mutation CRCs.
That [TimeSlice] CRC is comparable between time slices to ensure they are identical.
The CRCs for each time slice are communicated between nodes in the cluster via the Cassandra table.
Transmission of mutations
In the ideal situation, identical time slices and all three nodes are active – so each node is happily ticking away only transmitting its primary token range segment files.
However, we need to deal with robustness and assume that nodes fail, time slices do not match and we still have the requirement that ALL data is replicated.
We use gossip to monitor which nodes are active and not, and then if a node fails – the ‘secondary’ become active for that nodes ‘primary’ token range.
Time slice CRC processing
If a CRC matches for a time slice between 2 node – then when that time slice is fully transmitted (for a given destination), then the corresponding time slice (with the matching crc) can be marked as sent (synchdeleted.)
If the CRC mismatches, and there is no higher priority active node with a matching CRC, then that time slice is to be transmitted – this is to ensure that no data is missed and everything is fully transmitted.
Active Node Monitoring Algorithm
Assume that the token ranges are (a,b], (b,c], (c,a], and the entire range of tokens is [a,c], we have three nodes (n1, n2 and n3) and replication factor 3.
-
- On startup the token ranges for the keyspace are determined - we actively listen for token range changes and adjust the schema appropriately.
- These are remapped so we have the following informations:
- node => [{primary ranges}, {secondary ranges}, {tertiary ranges}]
- Note: We support vnodes where there may be multiple primary ranges for a node.
- In our example we have:
- n1 => [{(a,b]}, {(b,c]}, {c,a]}]
- n2 => [{(b,c]}, {c,a]}, {(a,b]}]
- n3 => [{c,a]}, {(a,b]}, {(b,c]}]
- When all three nodes are live, the active token ranges for the node are as follows:
- n1 => [{(a,b]},
{(b,c]},{c,a]}] => {(a,b]} - n2 => [{(b,c]},
{c,a]}, {(a,b]}] => {(b,c]} - n3 => [{c,a]},
{(a,b]}, {(b,c]}] => {(c,a]}
- n1 => [{(a,b]},
- Assume that n3 has died, its primary range is then searched for in the secondary replicas of live nodes:
- n1 => [{(a,b]},
{(b,c]},{c,a]}] => {(a,b], } - n2 => [{(b,c]}, {c,a]},
{(a,b]}] => {(b,c], (c,a]} n3=>[{c,a]},{(a,b]},{(b,c]}] => {}
- n1 => [{(a,b]},
- Assume that n2 and n3 have died, their primary range is then searched for in the secondary replicas of live nodes, and if not found the tertiary replicas (assuming replication factor 3) :
- n1 => [{(a,b]}, {(b,c]}, {c,a]}] => {(a,b], (b,c], (c,a]}
n2=>[{(b,c]},{c,a]},{(a,b]}]=> {}n3=>[{c,a]},{(a,b]},{(b,c]}]=> {}
- This ensures that data is only sent once from each edge node, and that dead nodes do not result in orphaned data which is not sent.
Handling the Node Failure Case
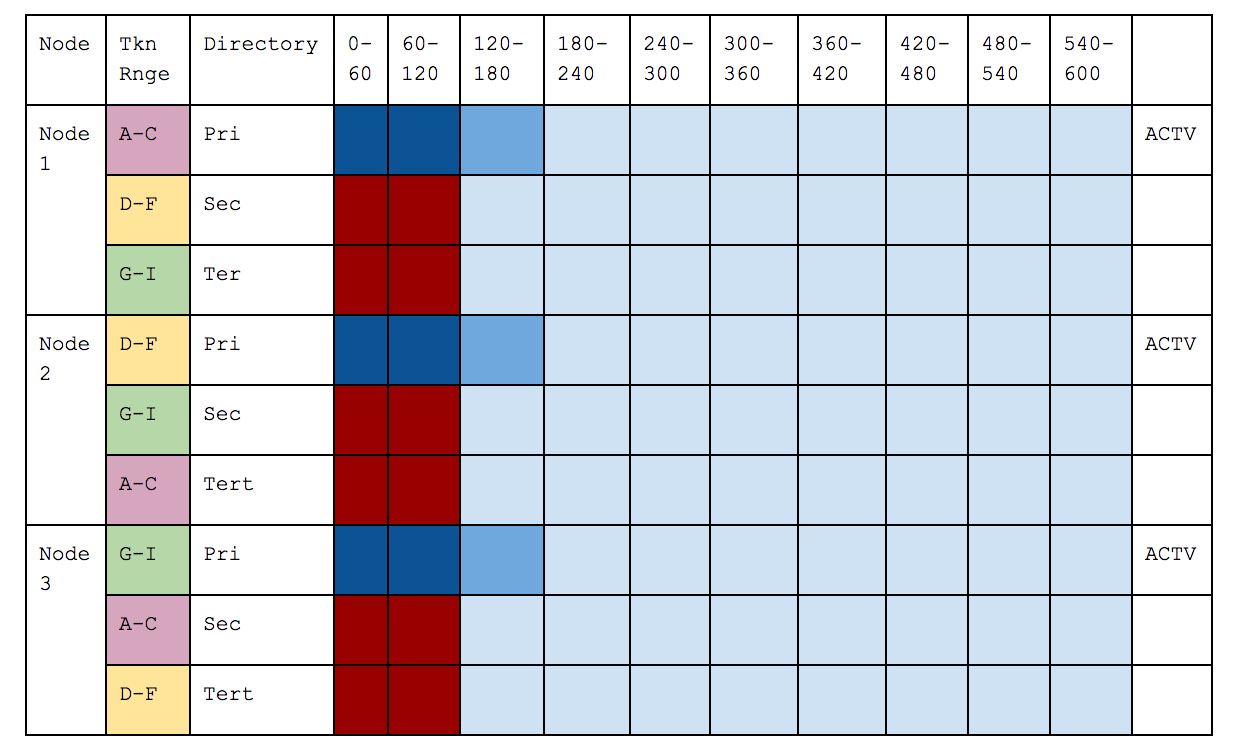
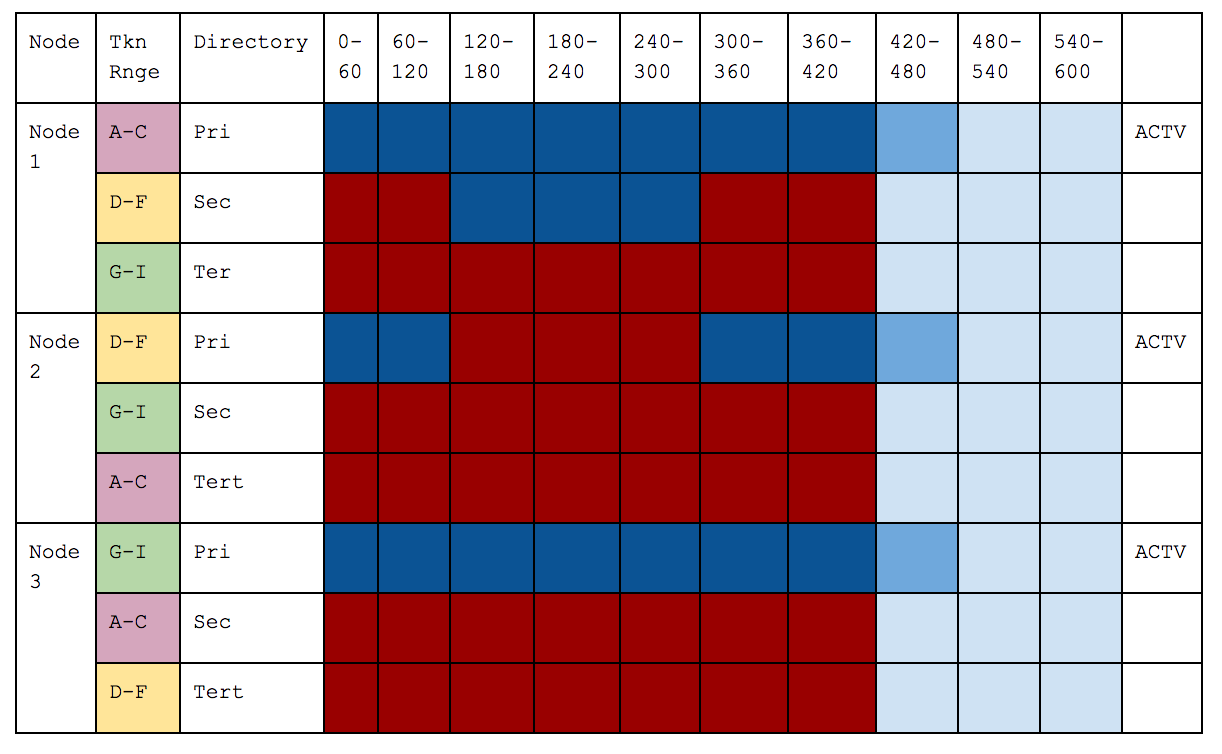
Below illustrates the three stages of a failure case.
- Before - where everything is working as expected.
- Node 2 Fails - so Node 1 becomes Active for its token Slices and ignores what it has already been partially sent for 120-180, and resends from its secondary directory.
- Node 2 restarts - this is after Node 1 has sent 3 Slices for which Node 2 was primary (but Node 1 was Active because it was Node 2’s secondary), it synchronously Deletes those because the CRCs match. It ignores what has already been partially sent for 300-360 and resends those from its primary directory and carries on.

Before
Node 2 Dies
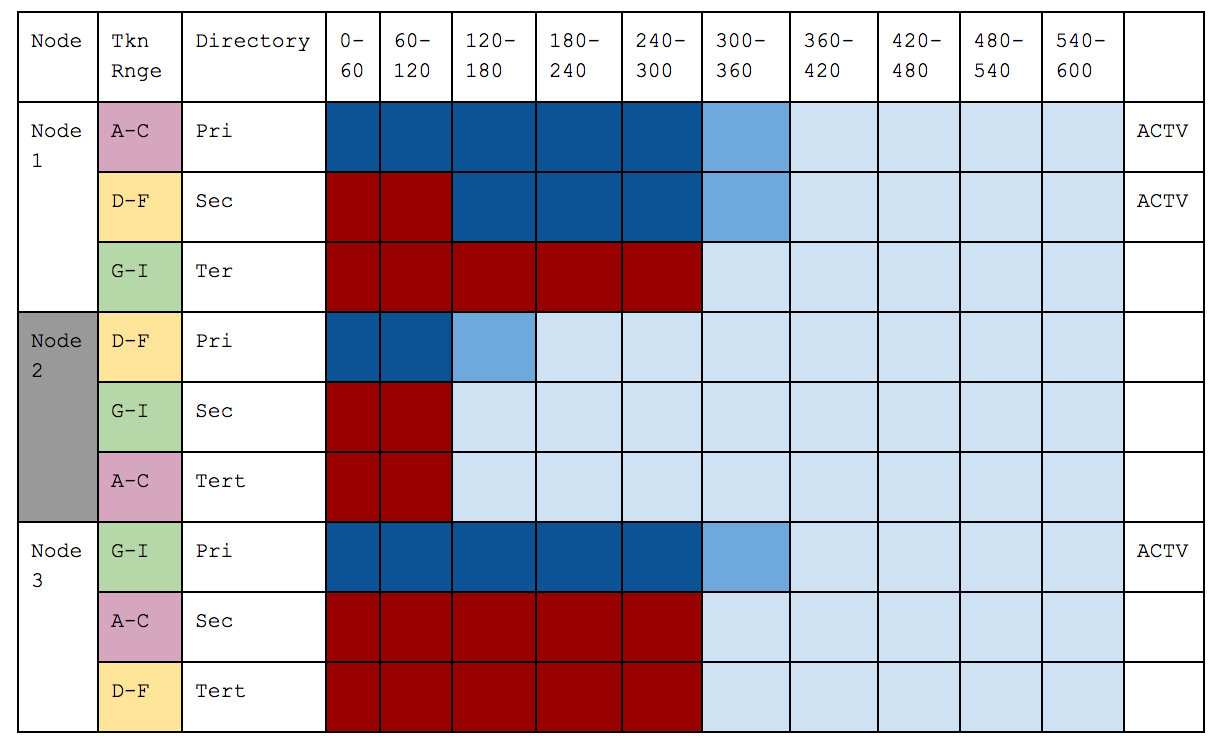
Node 2 Restarts
Conclusion
The vastly improved and revamped DSE Advanced Replication v2 in DSE 5.1 is more resilient and performant with support for multi-hubs and multi-clusters.
For more information see our documentation here.
Overview
Ingestion
Queuing
Replication
CDC Deduplication and its integration into the Message Queue to support replication
Deduplication
Distinct Tables
token Range configuration
Time slice separation
Time slice buckets
Example CDC Time Window Ingestion
Comparing Time slices
Transmission of mutations
Time slice CRC processing
Active Node Monitoring Algorithm
Handling the Node Failure Case
Conclusion
More Technology
View All
Introducing the DataStax AI Terraform Module


